用mongo和redis查询排行榜、统计活跃用户
nosql数据库能解决关系型数据库遇到的性能和扩展性的问题,本博客将以mongodb和redis两种nosql数据库为基础,简单的介绍下面两个业务场景的解决方案:
1.查询排行榜(以当日总步数排名为例,查询排名前200的用户); 2.统计活跃用户数(统计某个移动端app软件在各个下载渠道的活跃设备数,以起始时间,版本号,系统类型等作为查询条件)。
项目源码url:https://github.com/zhzhair/spring-boot-nosql.git。
运行环境很简陋:window10,8G内存(项目实际可用内存3个多G),i7处理器,4核8线程。
案例一:查询当日总步数排名前200的用户计步信息。技术架构:java8,spring boot2.0.0,mysql,redis,mongodb,mybatis,swagger,jmeter,idea,maven。
(i)添加测试数据:新建32个表,按照用户id对32取模添加测试数据到不同的表,做定时任务,每秒添加或修改300条记录。表包括user_id和步数step_count两个字段,假设手机每隔一段时间传一次累计步数,如果当日用户有记录,就修改用户的步数(增加新的步数),否则直接添加记录。部分代码如下:
@LogForTask
@Scheduled(cron = "0/1 * * * * ?")
public void uploadStep(){//定时任务每秒添加或修改300条记录
IntStream.range(0,300).parallel().forEach(i->stepService.uploadStep(32));
}
(ii)程序设计:在高并发的情况下内存是个问题(out of memory exception!),单个mongodb文档也不能放太多的数据,所以需要设置内存不足就读取磁盘。考虑到第200名的总步数不会减少,并且越往后越“稳定”,所以把它作为阈值就可以给查询的表“瘦身”,从而避免大表排序。
初始化(即启动项目时):需要将32个表的前200名都放到一个mongodb文档,再将文档前200名替换到该bson文档,同时将第200名的步数存到redis里面,部分代码如下:
@Resource
private StepService stepService;
private static StepService service;
@PostConstruct
public void init(){
service = this.stepService;
}
public static void main(String[] args) {
SpringApplication.run(StepsApplication.class, args);
//启动项目初始化排名
service.recordTopAll(32);
}
@Override
public void recordTopAll(int tableCount) {
mongoTemplate.dropCollection(StepsTop.class);//删除文档
IntStream.range(0,tableCount).parallel().forEach(this::insertOneTable);//将MySQL的数据插入到mongo文档
/*取出前200名放到list,更新mongo文档的数据为当前list的数据*/
Query query = new Query().with(new Sort(Sort.Direction.DESC,"totalCount")).limit(200);
List<StepsTop> list = mongoTemplate.find(query,StepsTop.class);
if(list.isEmpty()) return;
mongoTemplate.dropCollection(StepsTop.class);
mongoTemplate.insertAll(list);
/*redis保存阈值-第200名的步数*/
int size = Math.min(200,list.size());
redisTemplate.opsForValue().set(redisKey,String.valueOf(list.get(size - 1).getTotalCount()));
}
步数上传:redis的数据做定时任务更新,阈值越来越大,每次都将接收到的步数或更新后的步数与阈值比较,比这个阈值大才会去查mongo,然后对mongo文档做更新或插入操作,这个“比较”会非常频繁,但是redis“不惧怕”高并发,我们不必担心。这样就大大地减少了对mongo文档的操作,确保mongo文档数据量很少,之后查询并排序mongo文档的数据就很快了。部分代码如下:
@Override
public void uploadStep(int tableCount) {
int userId = new Random().nextInt(500_0000);
int stepCount = 1 + new Random().nextInt(5000);
Integer count = commonMapper.getStepCount(prefix + userId%tableCount,userId);
if(count != null){
commonMapper.updateSteps(prefix + userId%tableCount, userId,count + stepCount);
}else{
commonMapper.insertTables(prefix + userId%tableCount, userId, stepCount);
}
String tailSteps = redisTemplate.opsForValue().get(redisKey);
int totalCount = count == null?stepCount:count + stepCount;
if(tailSteps != null && totalCount > Integer.valueOf(tailSteps)){//步数超过阈值就插入或更新用户的记录
Query query = new Query(Criteria.where("userId").is(userId));
if(!mongoTemplate.exists(query,StepsTop.class)){
StepsTop stepsTop = new StepsTop();
stepsTop.setUserId(userId);
stepsTop.setTotalCount(stepCount);
mongoTemplate.insert(stepsTop);
}else{
System.out.println("update: " + tailSteps);
Update update = new Update();
update.set("totalStep",totalCount);
mongoTemplate.upsert(query,update,StepsTop.class);
}
}else{
StepsTop stepsTop = new StepsTop();
stepsTop.setUserId(userId);
stepsTop.setTotalCount(stepCount);
mongoTemplate.insert(stepsTop);
}
}
定时任务:每隔10秒更新一次阈值,同时删除mongo文档中200名以外的数据;每隔1秒从mongo查询排好序的前200名的数据push到redis队列,方便从redis取出排名。部分代码如下:
@Override//更新阈值,删除mongo文档中200名以外的数据
public void flushRankAll() {
// Query query = new Query().with(new Sort(Sort.Direction.DESC,"totalCount")).limit(201);
// List<StepsTop> list = mongoTemplate.find(query,StepsTop.class);//高并发场景下容易出现内存不足异常:out of memory Exception
TypedAggregation<StepsTop> aggregation = Aggregation.newAggregation(
StepsTop.class,
project("userId", "totalCount"),//查询用到的字段
sort(Sort.Direction.DESC,"totalCount"),
limit(200)
).withOptions(newAggregationOptions().allowDiskUse(true).build());//内存不足到磁盘读写,应对高并发
AggregationResults<StepsTop> results = mongoTemplate.aggregate(aggregation, StepsTop.class, StepsTop.class);
List<StepsTop> list = results.getMappedResults();
if(list.size() == 201){
int totalCount = list.get(199).getTotalCount();
Query query1 = new Query(Criteria.where("totalCount").lt(totalCount));
mongoTemplate.remove(query1,StepsTop.class);
}
}
@Override//查询排好序的前200名的数据push到redis队列
public void recordRankAll() {
// Query query = new Query().with(new Sort(Sort.Direction.DESC,"totalCount")).limit(200);
// List<StepsTop> list = mongoTemplate.find(query,StepsTop.class);
TypedAggregation<StepsTop> aggregation = Aggregation.newAggregation(
StepsTop.class,
project("userId", "totalCount"),//查询用到的字段
sort(Sort.Direction.DESC,"totalCount"),
limit(200)
).withOptions(newAggregationOptions().allowDiskUse(true).build());//内存不足到磁盘读写,应对高并发
AggregationResults<StepsTop> results = mongoTemplate.aggregate(aggregation, StepsTop.class, StepsTop.class);
List<StepsTop> list = results.getMappedResults();
if(list.size() == 200){
Integer stepCount = list.get(199).getTotalCount();
redisTemplate.opsForValue().set(redisKey,String.valueOf(stepCount));
}
if(!list.isEmpty()){
redisListTemplate.delete(redisQueueKey);
//noinspection unchecked
redisListTemplate.opsForList().rightPushAll(redisQueueKey,list);
}
}
查询排行榜:现在就简单了,直接到redis队列查询即可,部分代码如下:
@ApiOperation(value = "查询当日总步数排名", notes = "查询当日总步数排名")
@RequestMapping(value = "/getRankAll", method = {RequestMethod.GET}, produces = {MediaType.APPLICATION_JSON_VALUE})
public BaseResponse<List<StepsRankAllResp>> getRankAll(int begin,int pageSize) {
BaseResponse<List<StepsRankAllResp>> baseResponse = new BaseResponse<>();
List<StepsRankAllResp> list = stepService.getRankAllFromRedis(begin,pageSize);
if(list.isEmpty()) list = stepService.getRankAll(begin,pageSize);//redis查不到数据就从Mongo查
baseResponse.setCode(0);
baseResponse.setMsg("返回数据成功");
baseResponse.setData(list);
return baseResponse;
}
@Override//todo 从redis读取
public List<StepsRankAllResp> getRankAllFromRedis(int begin, int pageSize) {
List<StepsTop> stepsList = redisListTemplate.opsForList().range(redisQueueKey,begin,pageSize);
List<StepsRankAllResp> list = new ArrayList<>(stepsList.size());
for (int i = 0; i < stepsList.size(); i++) {
StepsRankAllResp stepsRankAllResp = new StepsRankAllResp();
StepsTop stepsTop = stepsList.get(i);
BeanUtils.copyProperties(stepsTop,stepsRankAllResp);
stepsRankAllResp.setRank(begin + i + 1);
list.add(stepsRankAllResp);
}
return list;
}
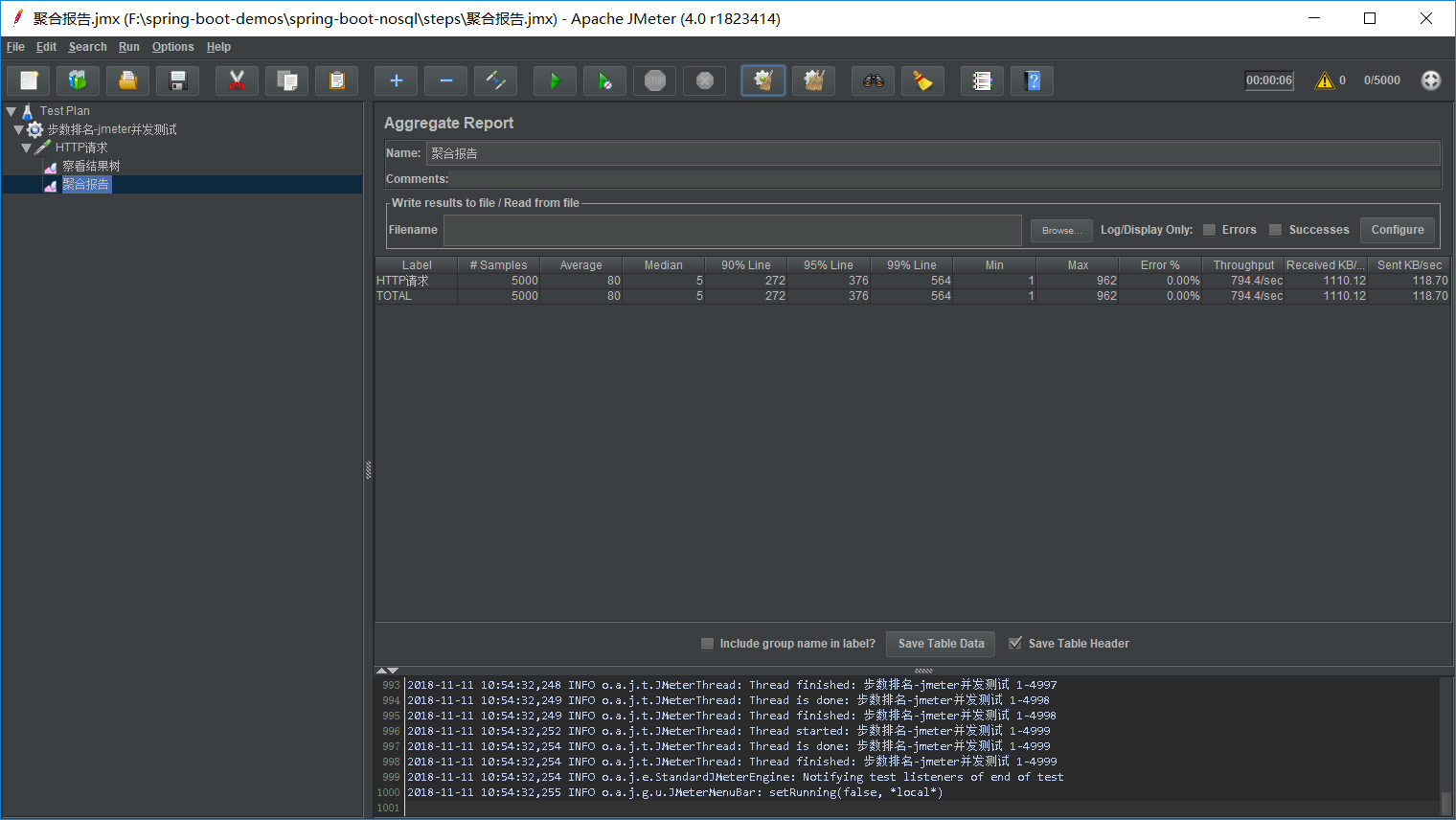
jmeter并发测试:访问接口文档--http://localhost:8080/swagger-ui.html/,调接口查询排名,配置调接口5000次,持续5秒,聚合报告如下:
案例二:统计活跃用户数(统计某个移动端app软件在各个下载渠道的活跃设备数,以起始时间,版本号,系统类型等作为查询条件,这里为了简便起见,不考虑查询条件)。技术架构:java8,spring boot2.0.0,mysql,mongodb,mybatis,swagger,idea,maven。
添加测试数据:新建4个表(建4个表是为了用多线程添加数据比较快,要不然“我没得耐心等”),包括APP_CHANNEL--下载渠道,DEVICE_ID--设备id号,DEVICE_HASHCODE--设备id号的hash值,DEVICE_HASHCODE_IDX--hash值的绝对值除以16384的余数。将1000w条记录插入这4个表,每个表250万,然后新建32个表,根据DEVICE_HASHCODE_IDX对32取模,将四个表的数据按类别插入到这32个表中,移动设备被分成了32个类,此时再也不用担心select app_channel,count(distinct device_id) from t group by app_channel;的效率了,如果你用的是专业的服务器,还有多台机器,你完全可以放到更多甚至几百个表中,这样就更无敌了。好了,现在我不关心去重再计数(MySQL的大表去重计数慢到你怀疑人生)的问题了,我只需要将每个表的数据合到一起(总数据量<=分表的个数*下载渠道个数),再分组求和(select app_channel,sum(device_count) from t group by app_channel)。部分代码如下:
@Override//按设备分类将1000w数据放到32个表中
public void insertTables(int tableCount) {
IntStream.range(0,tableCount).parallel().forEach(i->this.insertOneTable(i,tableCount));
}
private void insertOneTable(int i,int tableCount){
commonMapper.truncateTable(tableName + "_" + i);
for (int k = 0; k < 4; k++) {
List<StartRecordMapperRequest> list0 = new ArrayList<>(1000_0000/tableCount/4);
for (int j = i; j < 16384; j+=tableCount) {
List<StartRecordMapperRequest> list = commonMapper.getStartDataByRem(tableName + k, j);
list0.addAll(list);
}
int size = list0.size();
for (int j = 0; j < size/10000 + 1; j++) {
List<StartRecordMapperRequest> list = list0.subList(j*10000,Math.min(j*10000 + 10000,size));
commonMapper.insertTables(list,tableName + "_" + i);
}
}
System.out.println(i + " =================");
}
查询活跃用户数:将32个表的活跃设备数据先查出来,即select app_channel,count(distinct device_id) from t group by app_channel;插入到mongo文档,再从mongo分组求和即可得到最终的活跃设备数,部分代码如下:
@Override
public List<Document> getActiveCount(int tableCount) {
mongoTemplate.dropCollection(ActiveChannelCountMongo.class);
if(!mongoTemplate.collectionExists(ActiveChannelCountMongo.class))
IntStream.range(0,tableCount).parallel().forEach(this::getActiveCountOne);
TypedAggregation<ActiveChannelCountMongo> aggregation = Aggregation.newAggregation(
ActiveChannelCountMongo.class,
project("appChannel", "activeCount"),//查询用到的字段
// match(Criteria.where("dateTime").lte(Date.valueOf(todayZero).getTime()).gte(Date.valueOf(yesterday).getTime())),
group("appChannel").sum("activeCount").as("activeCount"),
sort(Sort.Direction.DESC,"activeCount"),
project("appChannel", "activeCount").and("appChannel").previousOperation()//输出字段,后面是取别名
).withOptions(newAggregationOptions().allowDiskUse(true).build());//内存不足就到磁盘读写
AggregationResults<Document> results = mongoTemplate.aggregate(aggregation, ActiveChannelCountMongo.class, Document.class);
return results.getMappedResults();
}
private void getActiveCountOne(int i){
List<ActiveChannelCount> list = viewMapper.getActiveCount(tableName + i);
mongoTemplate.insert(list,ActiveChannelCountMongo.class);
}
调接口看执行时间和返回结果:访问接口文档--http://localhost/swagger-ui.html/,调接口输出如下日志:
前端调用方法开始----getActiveCount---->:#{"URL地址":/view/getActiveCount, "HTTP方法":GET,参数:, "tableCount":32}
前端调用方法结束----getActiveCount---->:返回值: BaseResponse{code=0, msg='获取数据成功', data=[Document{{activeCount=111792, appChannel=appStore}}, Document{{activeCount=73757, appChannel=yingyongbao}}, Document{{activeCount=55640, appChannel=baiduyingyong}}, Document{{activeCount=55605, appChannel=vivo}}, Document{{activeCount=36997, appChannel=xiaomi}}, Document{{activeCount=36991, appChannel=360yingyong}}, Document{{activeCount=18575, appChannel=samsung}}, Document{{activeCount=18528, appChannel=iTools}}, Document{{activeCount=18483, appChannel=oppo}}, Document{{activeCount=18472, appChannel=htc}}, Document{{activeCount=18457, appChannel=huawei}}, Document{{activeCount=18374, appChannel=wandoujia}}, Document{{activeCount=18329, appChannel=mezu}}]}
2018-11-11 09:45:26,595 INFO - [http-nio-80-exec-13 ] c.e.f.c.m.i.RequestTimeConsumingInterceptor : /view/getActiveCount 3010ms
结束语:本文的方案能解决一些高并发,大数据量的问题,但只是对于数据量不是特别巨大,又想用较低成本解决问题的一小点想法。
用mongo和redis查询排行榜、统计活跃用户的更多相关文章
- 用Redis bitmap统计活跃用户、留存
Spool的开发者博客,描述了Spool利用Redis的bitmaps相关的操作,进行网站活跃用户统计工作. 原文:http://blog.getspool.com/2011/11/29/fast-e ...
- 05 redis中的Setbit位图法统计活跃用户
一:场景=>>>长轮询Ajax,在线聊天时,能够用到 Setbit 的实际应用 场景: 1亿个用户, 每个用户 登陆/做任意操作 ,记为 今天活跃,否则记为不活跃 每周评出: 有奖活 ...
- redis 用setbit(bitmap)统计活跃用户
getspool.com的重要统计数据是实时计算的.Redis的bitmap让我们可以实时的进行类似的统计,并且极其节省空间.在模拟1亿2千8百万用户的模拟环境下,在一台MacBookPro上,典型的 ...
- 用redis统计大量用户的登陆情况[只判断是否活跃]
有这样的一个场景需求:有上亿的用户,要统计这批用户的登陆情况,例如一周连续登陆,连续三天是是否登陆,一周活跃天数等用户 存在的挑战 数据如何尽可能用小的空间存储 如何能快速获取指定的数据 如果使用文件 ...
- 使用Redis做产品统计的两种模式
http://zihua.li/2012/07/two-patterns-of-statistics-using-redis/ 产品运行过程中及时记录收集并分析统计数据对产品的持续改进有重要的指导作用 ...
- Redis实现排行榜功能(实战)
需求前段时间,做了一个世界杯竞猜积分排行榜.对世界杯64场球赛胜负平进行猜测,猜对+1分,错误+0分,一人一场只能猜一次.1.展示前一百名列表.2.展示个人排名(如:张三,您当前的排名106579). ...
- redis实现排行榜
1 前言 实现一个排版榜,我们通常想到的就是mysql的order by 简单粗暴就撸出来了.但是这样真的优雅吗? 数据库是系统的瓶颈,这是众所周知的.如果给你一张百万的表,让你排序做排行榜,花费的时 ...
- 拼多多后台开发面试真题:如何用Redis统计独立用户访问量
众所周至,拼多多的待遇也是高的可怕,在挖人方面也是不遗余力,对于一些工作3年的开发,稍微优秀一点的,都给到30K的Offer,当然,拼多多加班也是出名的,一周上6天班是常态,每天工作时间基本都是超过1 ...
- 拼多多面试真题:如何用 Redis 统计独立用户访问量!
阅读本文大概需要 2.8 分钟. 作者:沙茶敏碎碎念 众所周至,拼多多的待遇也是高的可怕,在挖人方面也是不遗余力,对于一些工作 3 年的开发,稍微优秀一点的,都给到 30K 的 Offer. 当然,拼 ...
随机推荐
- 二、PHP基本语法 - PHP零基础快速入门
我们日常生活中,有些人使用普通话交流,有些人使用家乡话.类比到计算机的世界里,PHP 是人与计算机沟通的语言之一. 既然是语言,那就必须遵循一定的语法规则.譬如 A 向 B 表白,A 会对 B 说:& ...
- Spring通过注释配置Bean2 关联关系
接着我们讲讲关联关系的配置,我们耳熟能详的MVC结构,Controller关联着Service,Service关联着UserRepository,接着上一节的代码,完成上诉功能 在Main方法里,我们 ...
- 设置tomcat开机自启和后台运行
前言:程序登录遇到了问题,重启服务器上的tomcat后程序可以正常的使用,是通过进入bin目录,双击startup.bat运行启动的程序,此时会弹出启动窗口,而且该窗口不能关闭,这个窗口是tomcat ...
- Git diff 统计代码更改数量
1. git diff HEAD~2 获取最近两次提交的具体不同 包括增删的文件以及行数以及每行具体的改动 2. git diff --stat 获取文件更改的个数 增加行数 删除行数 3. git ...
- html5+ 原生标题栏添加input 输入框
titleNView: { backgroundColor: "#f7f7f7", // 导航栏背景色 titleText: "", // 导航栏标题 titl ...
- 浅谈kafka streams
随着数据时代的到来,数据的实时计算也越来越被大家重视.实时计算的一个重要方向就是实时流计算,目前关于流计算的有很多成熟的技术实现方案,比如Storm.Spark Streaming.flink等.我今 ...
- java8list排序
https://blog.csdn.net/york_2016/article/details/80169467
- Flask 构建微电影视频网站(七)
电影模块实现 上映预告 @home.route("/animation/") def animation(): """ 首页轮播动画 "&q ...
- Wiki leaks files backup
Wiki leaks files backup 来源 http://ftp.icm.edu.pl/packages/incoming/torrent/ Index of /packages/inco ...
- Python--基础二
Python基础:字符串str & 列表list & 元组tuple & 字典dict & 集合set Python 基础 2 字符串 str 字符串是以单引号或双引号 ...