MPP架构海量数据分析仓库——Greenplum介绍
一、Greenplum背景
时间回到2002年,互联网行业经过近10年的发展,数据量正处于快速增长期:
1、传统的主机计算模式在海量数据面前,除了造价昂贵外,在CPU计算和IO吞吐上不能满足海量数据的计算需求;
2、传统数据库大多基于SMP架,纵向扩容(scale-up)模式遇到了瓶颈。
3、分布式存储和分布式计算理论刚刚被提出来,Google的两篇著名论文关于GFS分布式文件系统和关于MapReduce 并行计算框架的理论引起业界的关注,分布式计算模式在互联网行业特别是收索引擎和分词检索等方面获得了巨大成功。
Greenplum是为解决以上问题产生的可以支持scale-out横向扩展的基于数据库的MPP架构的分布式数据存储和并行计算的工具。
二、Greenplum架构
2.1 Greenplum MPP架构
在介绍Greenplum架构前,先来了解下背景里出现的MPP架构。所谓的MPP架构即Massively Parallel Processing大规模并行进程。其基本特征是由多个SMP服务器通过节点互联网络连接而成,每个节点只访问自己的本地资源(内存、存储等),是一种完全无共享(Share Nothing)结构,因而横向扩展能力好,性能随着硬件增加呈线性提升,理论上其扩展无限制。
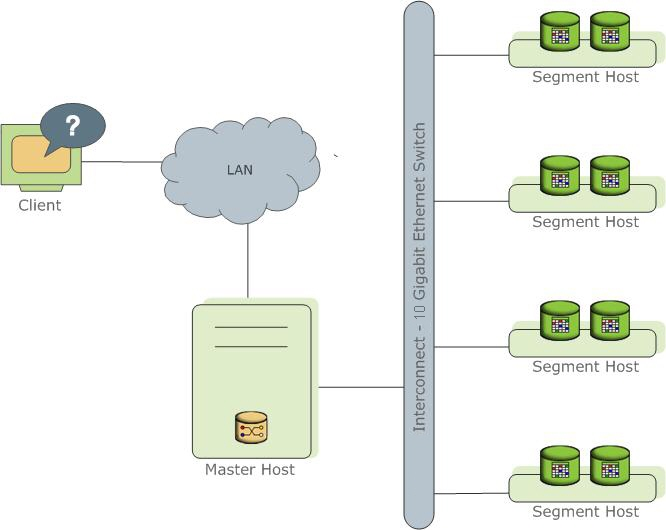
可以看到,每个segment的硬件内容是独立的,在上层通过网络进行通信,Greenplum架构是典型的MPP架构。Master节点保存着global system catalog,并提供外部访问入口。业务数据都根据分布规则存放在Segment节点上。
2.2 Master高可用之 Master&Standby
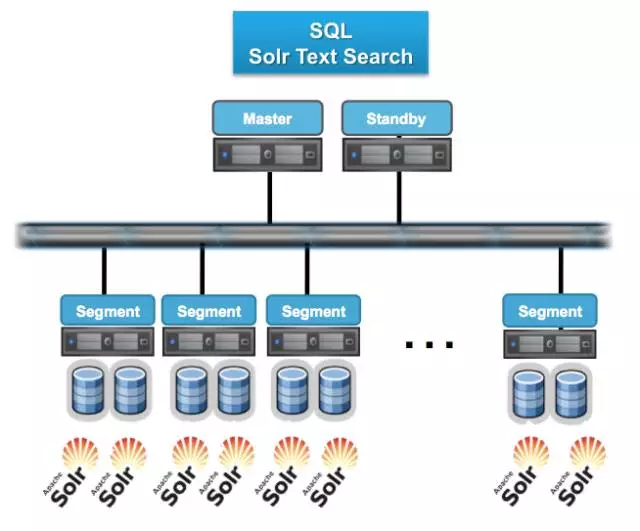
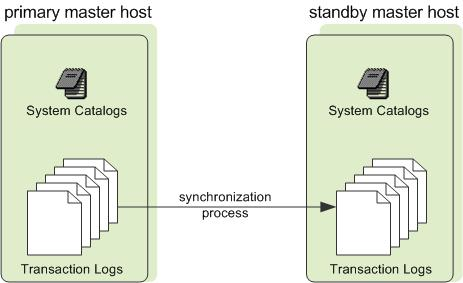
由于Greenplum所有的并行任务都是在Segment数据节点上完成后,Master只负责生成和优化查询计划、派发任务、协调数据节点进行并行计算。Master节点并不会因为因为数据压力过大导致资源紧张成为瓶颈。
2.3 Segment高可用之镜像策略
在上一期安装初始化的时候有讲到ssh协议不通会导致初始化互相copy primary文件到别的镜像主机当做mirror文件失效报错,现在详细介绍下镜像策略。
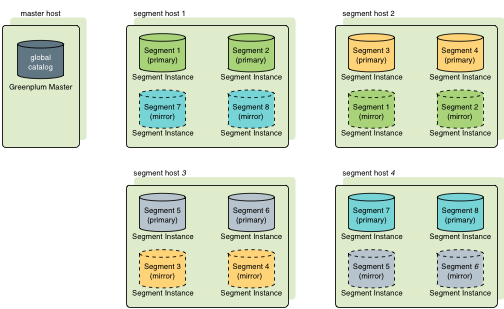
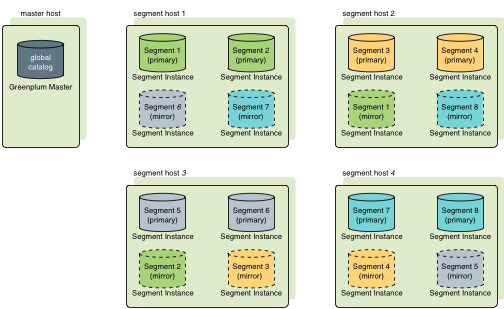
Greenplum有两种镜像策略,分别为group(默认策略)和spread模式。其中group模式每个Host的镜像文件都放在下一个Host上,所有计算节点形成一个环。如下图
而spread模式是将每个Host的镜像依次分散到后续Host上,如下图
两者的差异在于可宕机数量以及宕机后仍处在正常状态服务器的压力。
以上两图为例,group模式下segment host1挂掉后,集群会使用segment host2镜像实例当做segment host1主实例的备选,使集群继续使用。即使在segment host1挂掉后,segment host3挂掉,segment host2和segment host4的主实例和镜像实例扔能支撑整个集群正常使用;
而在spread模式下segment host1挂掉后,其他三台任意出现故障导致服务不可用时,整个集群会有部分节点无法访问导致异常(例如segment host2和segment host3挂掉绿色不可用,segment host4挂掉蓝色不可用),spread对比group的优点在于,当只出现一台机器如segment host1挂掉时,spread能将segment host1的压力平分到segment host2和segment host3上,而group模式会将压力全都转移到segment host2上。
镜像模式可自动实现故障转移功能;如何选择镜像模式,需要根据实际情况来选择。
gpinitsystem_config初始化文件
################################################
#### OPTIONAL MIRROR PARAMETERS
################################################ #### Base number by which mirror segment port numbers
#### are calculated.
MIRROR_PORT_BASE= #### Base number by which primary file replication port
#### numbers are calculated.
REPLICATION_PORT_BASE= #### Base number by which mirror file replication port
#### numbers are calculated.
MIRROR_REPLICATION_PORT_BASE= #### File system location(s) where mirror segment data directories
#### will be created. The number of mirror locations must equal the
#### number of primary locations as specified in the
#### DATA_DIRECTORY parameter.
#declare -a MIRROR_DATA_DIRECTORY=(/data1/mirror /data1/mirror /data1/mirror /data2/mirror /data2/mirror /data2/mirror)
declare -a MIRROR_DATA_DIRECTORY=(/home/gpadmin/gpdata/gpdatam1 /home/gpadmin/gpdata/gpdatam2)
参考文档:
1、Greenplum架构 https://gpdb.docs.pivotal.io/5100/admin_guide/intro/arch_overview.html
2、镜像模式 https://gpdb.docs.pivotal.io/570/admin_guide/highavail/topics/g-overview-of-segment-mirroring.html
3、Master-Slave https://gpdb.docs.pivotal.io/5100/admin_guide/highavail/topics/g-overview-of-master-mirroring.html
MPP架构海量数据分析仓库——Greenplum介绍的更多相关文章
- MPP 架构数据库
Greenplum是一种基于postgresql的分布式数据库.其采用shared nothing架构(MPP),主机,操作系统,内存,存储都是自我控制的,不存在共享.也就是每个节点都是一个单独的数据 ...
- 从0到1搭建基于Kafka、Flume和Hive的海量数据分析系统(一)数据收集应用
大数据时代,一大技术特征是对海量数据采集.存储和分析的多组件解决方案.而其中对来自于传感器.APP的SDK和各类互联网应用的原生日志数据的采集存储则是基本中的基本.本系列文章将从0到1,概述一下搭建基 ...
- 海量数据处理利器greenplum——初识
简介及适用场景 如果想在数据仓库中快速查询结果,可以使用greenplum. Greenplum数据库也简称GPDB.它拥有丰富的特性: 第一,完善的标准支持:GPDB完全支持ANSI SQL 200 ...
- 海量数据处理利器greenplum——初识
简介及适用场景 如果想在数据仓库中快速查询结果,可以使用greenplum. Greenplum数据库也简称GPDB.它拥有丰富的特性: 第一,完善的标准支持:GPDB完全支持ANSI SQL 200 ...
- DDD分层架构之值对象(介绍篇)
DDD分层架构之值对象(介绍篇) 前面介绍了DDD分层架构的实体,并完成了实体层超类型的开发,同时提供了验证方面的支持.本篇将介绍另一个重要的构造块——值对象,它是聚合中的主要成分. 如果说你已经在使 ...
- [转]MPP架构
数据库构架设计中主要有Shared Everthting.Shared Nothing.和Shared Disk: Shared Everthting:一般是针对单个主机,完全透明共享CPU/MEMO ...
- MPP、SMP、NUMA概念介绍
一.MPP,SMP,NUMA概念介绍 1.1. MPP架构介绍 MPP (Massively Parallel Processing),大规模并行处理系统,这样的系统是由许多松耦合的处理单 ...
- github仓库主页介绍、用git管理本地仓库和github仓库、搭建网站
github仓库主页介绍 名词解释: 工作区: 添加.编辑.修改文件等动作 暂存区: 暂存已经修改的文件,最后统一提交到git中 git(仓库): 最终确定的文件保存到仓库,成为一个新的版本,并且对他 ...
- (转)私有代码存放仓库 BitBucket介绍及入门操作
转自:http://blog.csdn.net/lhb_0531/article/details/8602139 私有代码存放仓库 BitBucket介绍及入门操作 分类: 研发管理2013-02-2 ...
随机推荐
- 阿里云rds数据库迁移实战(多数据源)
由于某几个业务表数据量太大,数据由业务写,数据部门读. 写压力不大,读却很容易导致长时间等待问题(读由单独系统进行读),导致连接被占用,从而容易并发稍稍增长导致全库卡死! 于是,就拆库呗. 业务系统拆 ...
- 英语笔记3(git)
备注 一: Staging Modified Files Let’s change a file that was already tracked. (tracked 表示该文件已经被git管理过,再 ...
- linux系统安全设置策略
1.检查是否设置口令长度至少8位,并包括数字,小写字符.大写字符和特殊符号4类中至少2类. 在文件/etc/login.defs中设置 PASS_MIN_LEN 不小于标准值 修改/etc/pam.d ...
- SQL数据库连接语句
一般的远程访问的写成这样: Data Source=IP ;Initial Catalog=数据库名 ;UserID= 用户名 ;Password=密码 本地访问的写成这样: Data Source= ...
- 淘宝npm镜像使用方法(转)
1.临时使用 npm --registry https://registry.npm.taobao.org install express 2.持久使用 npm config set registry ...
- linux(centos)搭建.net core 运行环境
总的来说,非常简单,我记录一下: 1.打开https://www.microsoft.com/net/download?initial-os=linux 这里"Instal .NET C ...
- XML就是这么简单
什么是XML? XML:extensiable markup language 被称作可扩展标记语言 XML简单的历史介绍: gml->sgml->html->xml gml(通用标 ...
- Linux 终端下解压文件失败问题
Linux 终端下解压文件失败: # tar -zxvf *****.tar.bz2 tar 命令出错gzip: stdin: not in gzip format tar: Child return ...
- PE知识复习之PE的导入表
PE知识复习之PE的导入表 一丶简介 上一讲讲解了导出表. 也就是一个PE文件给别人使用的时候.导出的函数 函数的地址 函数名称 序号 等等. 一个进程是一组PE文件构成的. PE文件需要依赖那些 ...
- [解决方案]SystemError: Parent module '' not loaded, cannot perform relative import的解决方案
缺陷:__mian__不能使用相对导入 PEP 328 Relative Imports and __name__ 中说明: Relative imports use a module's __nam ...