Windows下配置eclipse写WordCount
1 下载插件
hadoop-eclipse-plugin-2.7.2.jar
github上下载源码后需要自己编译。这里使用已经编译好的插件即可
2 配置插件
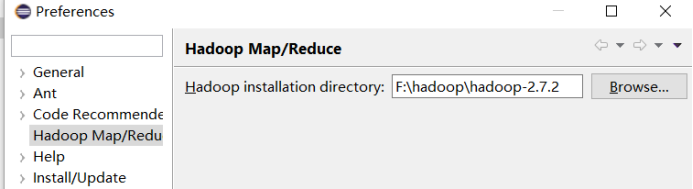
把插件放到..\eclipse\plugins目录下,重启eclipse,配置Hadoop installation directory ,
如果插件安装成功,打开Windows—Preferences后,在窗口左侧会有Hadoop Map/Reduce选项,点击此选项,在窗口右侧设置Hadoop安装路径。(windows下只需把hadoop-2.7.2.tar.gz解压到指定目录)
3 配置Map/Reduce Locations
打开Windows —> Open Perspective —> Other,选择Map/Reduce,点击OK,控制台会出现:

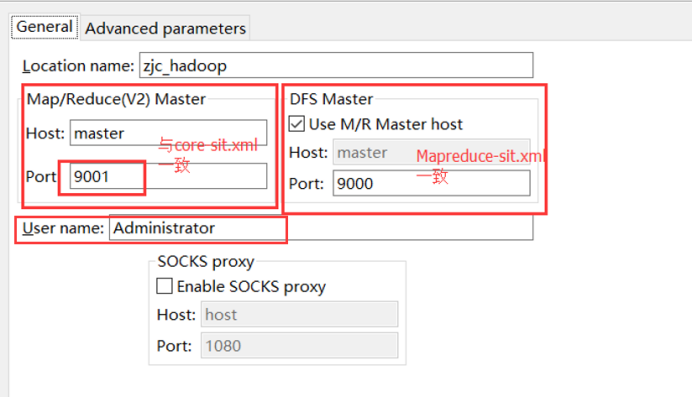
右键 zjc_hadoop 配置hadoop:输入
Location Name,任意名称即可.
配置Map/Reduce Master和DFS Mastrer,
前一个与Cores-site.xml的fs.defaultFS一致
后一个与Mapreduce-site.xml的mapreduce.jobtracker.address 一致.
user name:这个是连接hadoop的用户名,因为我是用Administrator用户安装的hadoop,而且没建立其他的用户,所以就用Administrator
重启eclipse后在配置Advanced parameters ,这个里面有很多默认的参数与路径,还要再配置下:(重启编辑advance parameters tab页原因:在新建连接的时候,这个advance paramters tab页面的一些属性会显示不出来,显示不出来也就没法设置,所以必须重启一下eclipse再进来编辑才能看到)
(1) dfs.replication:
这个这里默认是3,但是要根据你的Datanode的个数来定,如果你仅有2个datanode,那么就写2,如果只有一个,就写1,大于或者等于3个,写3
如果你只有3个datanode,但是你却指定副本数为4,是不会生效的,因为每个datanode上只能存放一个副本。
首先 dfs.replication这个参数是个client参数,即node level参数。需要在每台datanode上设置。
其实默认为3个副本已经够用了,设置太多也没什么用。
一个文件,上传到hdfs上时指定的是几个副本就是几个。以后你修改了副本数,对已经上传了的文件也不会起作用。可以再上传文件的同时指定创建的副本数
hadoop dfs -D dfs.replication=1 -put 70M logs/2
可以通过命令来更改已经上传的文件的副本数:
hadoop fs -setrep -R 3 /
查看当前hdfs的副本数
hadoop fsck –locations
hadoop.tmp.dir:
这个要跟上节建立的Hadoop集群配置中core-site.xml 中的hadoop.tmp.dir设置一样,上节填写的是/tmp/hadoop-root,这里也如是填写
(2) 点击"Finish"按钮,关闭窗口。
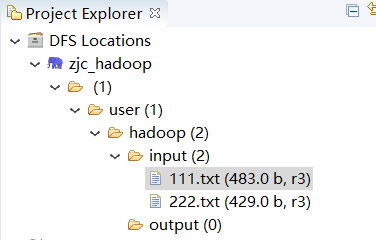
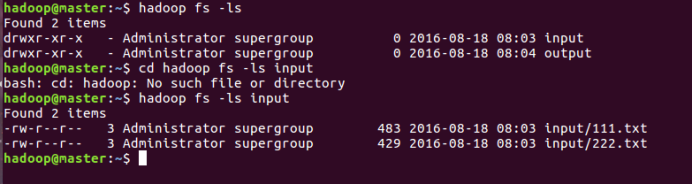
点击左侧的DFSLocations—>master (上一步配置的location name),如能看到hdfs的列表,表示安装成功
PS:Eclipse利用插件访问HDFS时,提示用户没有相应权限。
org.apache.hadoop.security.AccessControlException: Permission denied: user=ff
解决方法:更改HDFS权限
方法一:执行命令bin/hadoop fs -chmod -R 777
方法二:修改hadoop的配置文件:conf/hdfs-core.xml, 找到 dfs.permissions 的配置项 , 将value值改为 false
<property>
<name>dfs.permissions</name>
<value>false</value>
</property>
重启HADOOP:$HADOOP_HOME/bin/stop-all.sh
$HADOOP_HOME/bin/start-all.sh
4 wordcount实例
File—>Project,选择Map/Reduce Project,输入项目名称WordCount等。在WordCount项目里新建class,名称为WordCount,代码是从官方网站复制下来的,可以直接用,//代码网址:http://hadoop.apache.org/docs/current/hadoop-mapreduce-client/hadoop-mapreduce-client-core/MapReduceTutorial.html#Example:_WordCount_v1.0
如下:
package com.zjc.hadoop; import java.io.IOException;
import java.util.StringTokenizer; import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; public class WordCount { public static class TokenizerMapper extends Mapper<Object, Text, Text, IntWritable> { // 下面的IntWritable 跟 Text 类是hadoop内部类,相当于 java 中的 int 与 String
// MapReduce 程序中互相传递的是这种类型的参数
private final static IntWritable one = new IntWritable(1);
private Text word = new Text(); public void map(Object key, Text value, Context context) throws IOException, InterruptedException {
StringTokenizer itr = new StringTokenizer(value.toString());//java 自带的字符串分割函数
while (itr.hasMoreTokens()) {
word.set(itr.nextToken());
context.write(word, one);
/*
*eg map output:
* hello 1
* word 1
* hello 1
* hadoop 1
*/
}
}
} /*
* Reduce 输入:
* key: hello
* value: [1,1]
*
* Hadoop负责将Map产生的<key,value>处理成{具有相同key的value集合},传给Reducer
输入:<key,(listof values)>
输出:<key,value>
reduce函数(必须是这个名字)的参数,(输入key,输入具有相同key的value集合,Context)其中,
输入的key,value必须类型与map的输出<key,value>相同,这一点适用于map,reduce类及函数
*
*/
public static class IntSumReducer extends Reducer<Text, IntWritable, Text, IntWritable> {
private IntWritable result = new IntWritable(); public void reduce(Text key, Iterable<IntWritable> values, Context context)
throws IOException, InterruptedException {
int sum = 0;
System.out.println("-----------------------------------------");
System.out.println("key: "+key);
for (IntWritable val : values) {
System.out.println("val: "+val);
sum += val.get();
}
result.set(sum);
System.out.println("result: "+result.toString());
context.write(key, result);
}
} public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
Job job = Job.getInstance(conf, "word count"); // 任务名
job.setJarByClass(WordCount.class); // 指定Class
job.setMapperClass(TokenizerMapper.class); // 指定 Mapper Class
job.setCombinerClass(IntSumReducer.class); // 指定 Combiner Class
job.setReducerClass(IntSumReducer.class); // 指定Reucer Class
job.setOutputKeyClass(Text.class); // 指定输出的KEY的格式
job.setOutputValueClass(IntWritable.class); // 指定输出的VALUE的格式
job.setNumReduceTasks(2); //设置Reducer 个数默认1
// Mapper<Object, Text, Text, IntWritable> 输出格式必须与继承类的后两个输出类型一致
String args_0 = "hdfs://master:9000/test/input";
String args_1 = "hdfs://master:9000/test/output";
FileInputFormat.addInputPath(job, new Path(args_0)); // 输入路径
FileOutputFormat.setOutputPath(job, new Path(args_1)); // 输出路径
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}
上面的路径1 和路径2 由于在代码中已经定义,这不需要在配置文件中定义,若上面路径1和路径2 代码为:
FileInputFormat.addInputPath(job, new Path(otherArgs[0])); FileOutputFormat.setOutputPath(job, new Path(otherArgs[1]));
需要配置运行路径:类 右键 Run As—>Run Configurations
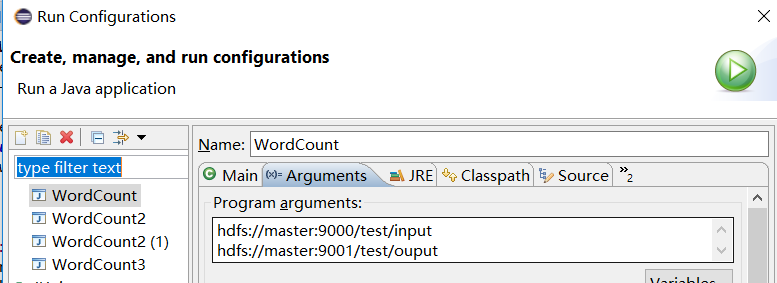
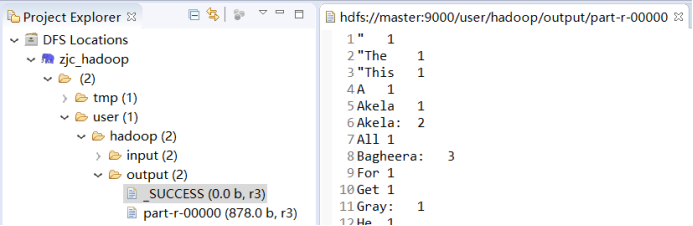
运行结果:
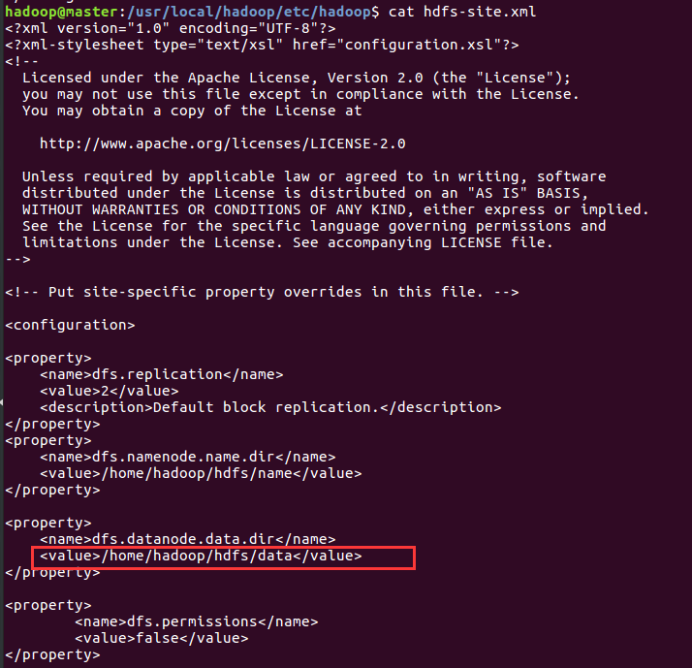
上传的文件在linux 里具体的位置是在 Hdfs-sit.xml 里设置的data路径下:
5 问题及解决办法
5.1 出现 空指针异常:
1 在Hadoop的$HADOOP_HOME/bin目录下放winutils.exe,
2 在windows环境变量中配置 HADOOP_HOME,

3
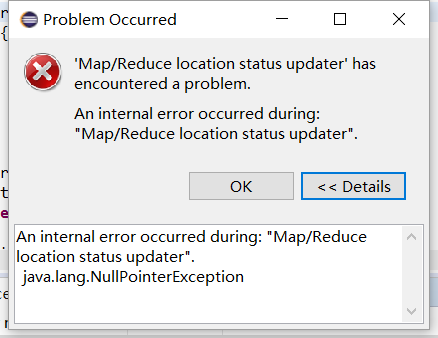
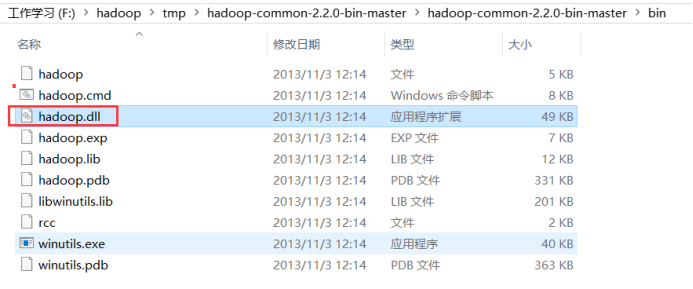
解决方法:hadoop.dll拷贝到C:\Windows\System32下面即可
5.2 出现log4j警告
将文件log4j.properties放到src下和java文件同目录.
# Configure logging for testing: optionally with log file
log4j.rootLogger=WARN, stdout
# log4j.rootLogger=WARN, stdout, logfile
log4j.appender.stdout=org.apache.log4j.ConsoleAppender
log4j.appender.stdout.layout=org.apache.log4j.PatternLayout
log4j.appender.stdout.layout.ConversionPattern=%d %p [%c] - %m%n
log4j.appender.logfile=org.apache.log4j.FileAppender
log4j.appender.logfile.File=target/spring.log
log4j.appender.logfile.layout=org.apache.log4j.PatternLayout
log4j.appender.logfile.layout.ConversionPattern=%d %p [%c] - %m%n
5.3 访问权限不够
参考博客:http://www.linuxidc.com/Linux/2014-08/105335.htm
方法1:访问无效
Eclipse连接远程Hadoop集群开发时权限不足问题解决方案:
当前登录windows的用户名和hadoop集群的用户名不一致,将没有权限访问
解决方案:
管理DFS system目录。目前做法是将hadoop服务集群关闭权限认证,修改hadoop安装集群master的hadoop-1.2.0/conf/hdfs-site.xml,增加:
|
<property> <name>dfs.permissions</name> <value>false</value> </property> |
正式发布时,可以在服务器创建一个和hadoop集群用户名一致的用户,即可不用修改master的permissions策略。
方法2:在master节点执行:(有效)
hadoop fs -chmod 777 /user
其中/user是我上传文件的路径(这个视具体情况而定)
方法3 :计算机用户名改为hadoop
5.4 Could not locate executable null\bin\winutils.exe in the Hadoop binaries
在运行程序中添加如下代码
File workaround = new File(".");
System.getProperties().put("hadoop.home.dir", workaround.getAbsolutePath());
new File("./bin").mkdirs();
new File("./bin/winutils.exe").createNewFile();
Windows下配置eclipse写WordCount的更多相关文章
- 在windows下配置Eclipse + go环境
http://blog.csdn.net/hengyunabc/article/details/7371446 本文章地址:http://blog.csdn.net/hengyunabc/articl ...
- [转]MonkeyRunner在Windows下的Eclipse开发环境搭建步骤(兼解决网上Jython配置出错的问题)
MonkeyRunner在Windows下的Eclipse开发环境搭建步骤(兼解决网上Jython配置出错的问题) 网上有一篇shangdong_chu网友写的文章介绍如何在Eclipse上配置M ...
- 在windows下用eclipse + pydev插件来配置python的开发环境
在windows下用eclipse + pydev插件来配置python的开发环境 一.安装 python 可以到网上下个Windows版的python,官网为:https://www.python. ...
- Windows下为 Eclipse 配置 C/C++ 编译环境(转)
1.Eclipse及CDT的安装 CDT的全称是C/C++ DevelopmentTools,CDT使得Eclipse能够支持C/C++的开发.直接下载 eclipse CDT 集成版 下载地址:ht ...
- windows下用eclipse+goclipse插件+gdb搭建go语言开发调试环境
windows下用eclipse+goclipse插件+gdb搭建go语言开发调试环境 http://rongmayisheng.com/post/windows%E4%B8%8B%E7%94%A ...
- eclipse下使用cygwin的方法(Windows下用eclipse玩gcc/g++和gdb)
明天就回国了,今晚回国前写写如何配置eclipse和CDT.这个配置方法网上讨论不是很多,可能用的人少,毕竟Windows上写C++程序多数喜欢VS,即使写的是Linux程序,很多人仍然会用VS(说只 ...
- windows下配置lamp环境(2)---配置Apache服务器2.2.25
配置Apache 配置Apache时,先要找到安装目录中的主配置文httpd.conf,使用文本编辑器打开,最好不要使用windows自带的编辑器,可以使用NotePad++, vim,或者subli ...
- windows下配置svn的https访问
svn是一个功能强大的代码版本管理系统,可以将服务端安装在linux.unix以及windows下.svn通常采用http方式进行代码提交与下载.由于密码采用明文传输,因此存在泄密的风险.若采用htt ...
- 在Windows下用Eclipse+CDT+MinGW搭建C++开发平台
本文提供了在Windows下用Eclipse+CDT+MinGW搭建C / C++开发平台的方法, 测试平台为Windows XP Sp2 CHS. 以下软件均为Windows平台下的版本. 1. ...
随机推荐
- Linux IO 模型
Linux 中主要有五种IO模式:阻塞IO, 非阻塞IO, IO 多路复用,信号驱动IO和异步IO; 如果从同步非同步,阻塞非阻塞角度来看,又可以分为:同步阻塞IO, 同步非阻塞IO,异步阻塞IO和异 ...
- String输出结果to thi
http://blog.csdn.net/itmyhome1990/article/details/9132929
- idea怎么配置spring
前提基础: 1.idea软件并JDK成功能用 2.有tacate,并会导入. 3.了解jsp和mvc基本结构 详细介绍: https://www.cnblogs.com/wormday/p/84356 ...
- pydensecrf的inference.py代码的学习
https://github.com/lucasb-eyer/pydensecrf/blob/master/examples/inference.py 1.运行 先运行看看实现的结果: (deeple ...
- (一) Getting Started
Elasticsearch is a highly scalable open-source full-text search and analytics engine. It allows you ...
- Linux内核入门到放弃-网络-《深入Linux内核架构》笔记
网络命名空间 struct net { atomic_t count; /* To decided when the network * namespace should be freed. */ a ...
- 二十九、layui分页插件的使用
<div id="page1"></div> <script> //开启分页 var page = 1; function findstoreL ...
- 【转】Python爬虫:抓取新浪新闻数据
案例一 抓取对象: 新浪国内新闻(http://news.sina.com.cn/china/),该列表中的标题名称.时间.链接. 完整代码: from bs4 import BeautifulSou ...
- Kubernetes — Job与CronJob
有一类作业显然不满足这样的条件,这就是“离线业务”,或者叫作 Batch Job(计算业务). 这 种业务在计算完成后就直接退出了,而此时如果你依然用 Deployment 来管理这种业务的话,就会 ...
- git命令行 整理(一位大神给我的私藏)
Evernote Export Git 是一个很强大的分布式版本控制系统.它不但适用于管理大型开源软件的源代码,管理私人的文档和源代码也有很多优势. Git常用操作命令: 1) 远程仓库相关命令 检出 ...