HBase备份还原OpenTSDB数据之Snapshot
前言
本文基于伪分布式搭建 hadoop+zookeeper+hbase+opentsdb之后,想了解前因后果的可以看上一篇和上上篇。
opentsdb在hbase中生成4个表(tsdb, tsdb-meta, tsdb-tree, tsdb-uid),其中tsdb这个表最重要,数据迁移时,备份还原此表即可。
一、本地数据备份恢复
1、备份
本文测试本地备份服务器hostname:hbase3,ip为192.168.0.214。
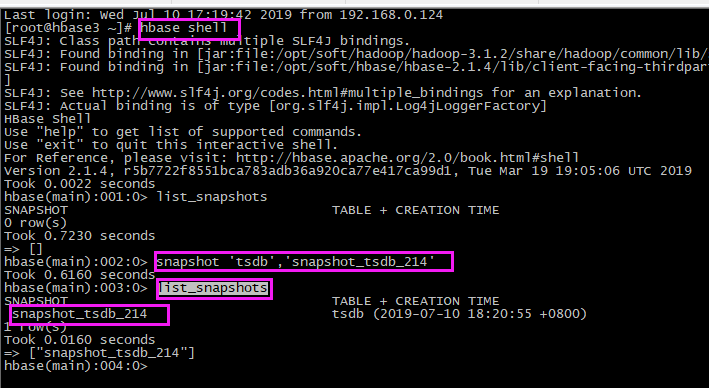
# 进入shell命令
hbase shell
# 快照tsdb表:快照名snapshot_tsdb_214
snapshot 'tsdb','snapshot_tsdb_214'
## 查看快照
# 1、shell查看快照
list_snapshots # 2、hdfs 查看快照:在hdfs的 /hbase/.hbase-snapshot 目录下可以查看所有快照
hdfs dfs -ls -R /hbase/.hbase-snapshot

2、还原
【1】原数据查看
【2】删除表
# disable表
disable 'tsdb'
# 查看
drop 'tsdb'

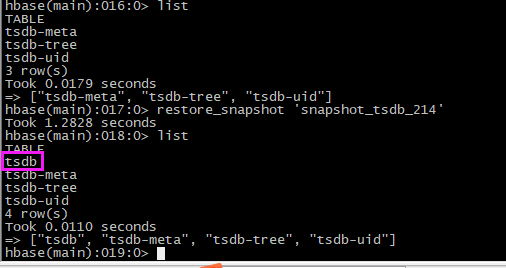
【3】还原
# 恢复快照
restore_snapshot 'snapshot_tsdb_214' # 查看表是否生成
list
【4】验证
二、数据迁移:从一台服务器迁移到另一台服务器
本文从hbase3(ip:192.168.0.214)迁移到hbase1(ip:192.168.0.211),这两台服务器搭建的环境一样,并且做了互相免密登录,在第一步已经在hbase3对tsdb做了快照snapshot_tsdb_214,先接下来要做的是,将此快照迁移到hbase1服务器上。
1、迁移快照
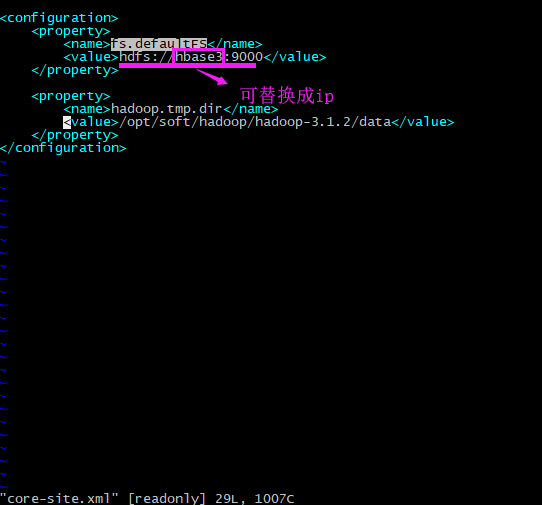
hbase org.apache.hadoop.hbase.snapshot.ExportSnapshot -snapshot snapshot_tsdb_214 -copy-from hdfs://192.168.0.214:9000/hbase -copy-to hdfs://192.168.0.211:9000/hbase -mappers 20 -bandwidth 1024
注:标黄的部分是hadoop的core-site.xml配置文件中,配置的fs.defaultFS的值。
2、解决报错:Java heap space
【1】报错日志
2019-07-11 10:09:09,875 INFO [main] snapshot.ExportSnapshot: Copy Snapshot Manifest from hdfs://192.168.0.214:9000/hbase/.hbase-snapshot/snapshot_tsdb_214 to hdfs://192.168.0.211:9000/hbase/.hbase-snapshot/.tmp/snapshot_tsdb_214
2019-07-11 10:09:10,942 INFO [main] client.RMProxy: Connecting to ResourceManager at hbase3/192.168.0.214:8032
2019-07-11 10:09:13,100 INFO [main] snapshot.ExportSnapshot: Loading Snapshot 'snapshot_tsdb_214' hfile list
2019-07-11 10:09:13,516 INFO [main] mapreduce.JobSubmitter: number of splits:5
2019-07-11 10:09:13,798 INFO [main] mapreduce.JobSubmitter: Submitting tokens for job: job_1562738985351_0004
2019-07-11 10:09:14,061 INFO [main] impl.YarnClientImpl: Submitted application application_1562738985351_0004
2019-07-11 10:09:14,116 INFO [main] mapreduce.Job: The url to track the job: http://hbase3:8088/proxy/application_1562738985351_0004/
2019-07-11 10:09:14,116 INFO [main] mapreduce.Job: Running job: job_1562738985351_0004
2019-07-11 10:09:23,331 INFO [main] mapreduce.Job: Job job_1562738985351_0004 running in uber mode : false
2019-07-11 10:09:23,333 INFO [main] mapreduce.Job: map 0% reduce 0%
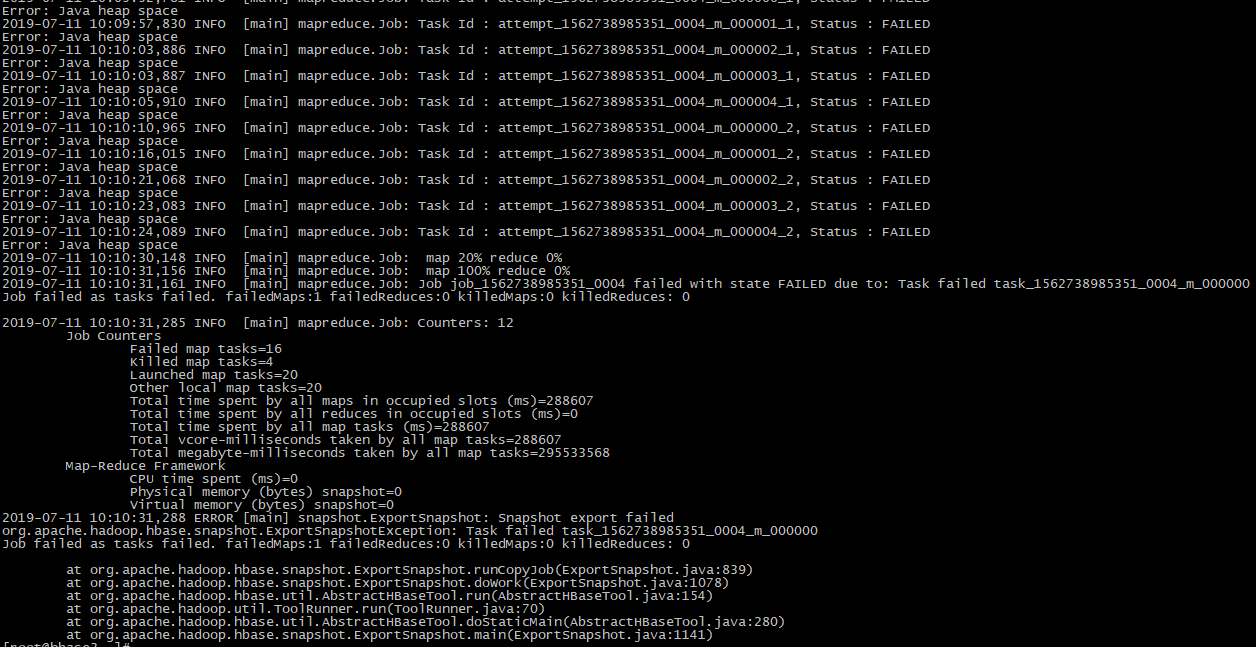
2019-07-11 10:09:34,529 INFO [main] mapreduce.Job: Task Id : attempt_1562738985351_0004_m_000000_0, Status : FAILED
Error: Java heap space
2019-07-11 10:09:40,659 INFO [main] mapreduce.Job: Task Id : attempt_1562738985351_0004_m_000001_0, Status : FAILED
Error: Java heap space
2019-07-11 10:09:44,717 INFO [main] mapreduce.Job: Task Id : attempt_1562738985351_0004_m_000002_0, Status : FAILED
Error: Java heap space
2019-07-11 10:09:44,719 INFO [main] mapreduce.Job: Task Id : attempt_1562738985351_0004_m_000003_0, Status : FAILED
Error: Java heap space
2019-07-11 10:09:45,728 INFO [main] mapreduce.Job: Task Id : attempt_1562738985351_0004_m_000004_0, Status : FAILED
Error: Java heap space
2019-07-11 10:09:52,781 INFO [main] mapreduce.Job: Task Id : attempt_1562738985351_0004_m_000000_1, Status : FAILED
Error: Java heap space
2019-07-11 10:09:57,830 INFO [main] mapreduce.Job: Task Id : attempt_1562738985351_0004_m_000001_1, Status : FAILED
Error: Java heap space
2019-07-11 10:10:03,886 INFO [main] mapreduce.Job: Task Id : attempt_1562738985351_0004_m_000002_1, Status : FAILED
Error: Java heap space
2019-07-11 10:10:03,887 INFO [main] mapreduce.Job: Task Id : attempt_1562738985351_0004_m_000003_1, Status : FAILED
Error: Java heap space
2019-07-11 10:10:05,910 INFO [main] mapreduce.Job: Task Id : attempt_1562738985351_0004_m_000004_1, Status : FAILED
Error: Java heap space
2019-07-11 10:10:10,965 INFO [main] mapreduce.Job: Task Id : attempt_1562738985351_0004_m_000000_2, Status : FAILED
Error: Java heap space
2019-07-11 10:10:16,015 INFO [main] mapreduce.Job: Task Id : attempt_1562738985351_0004_m_000001_2, Status : FAILED
Error: Java heap space
2019-07-11 10:10:21,068 INFO [main] mapreduce.Job: Task Id : attempt_1562738985351_0004_m_000002_2, Status : FAILED
Error: Java heap space
2019-07-11 10:10:23,083 INFO [main] mapreduce.Job: Task Id : attempt_1562738985351_0004_m_000003_2, Status : FAILED
Error: Java heap space
2019-07-11 10:10:24,089 INFO [main] mapreduce.Job: Task Id : attempt_1562738985351_0004_m_000004_2, Status : FAILED
Error: Java heap space
2019-07-11 10:10:30,148 INFO [main] mapreduce.Job: map 20% reduce 0%
2019-07-11 10:10:31,156 INFO [main] mapreduce.Job: map 100% reduce 0%
2019-07-11 10:10:31,161 INFO [main] mapreduce.Job: Job job_1562738985351_0004 failed with state FAILED due to: Task failed task_1562738985351_0004_m_000000
Job failed as tasks failed. failedMaps:1 failedReduces:0 killedMaps:0 killedReduces: 0 2019-07-11 10:10:31,285 INFO [main] mapreduce.Job: Counters: 12
Job Counters
Failed map tasks=16
Killed map tasks=4
Launched map tasks=20
Other local map tasks=20
Total time spent by all maps in occupied slots (ms)=288607
Total time spent by all reduces in occupied slots (ms)=0
Total time spent by all map tasks (ms)=288607
Total vcore-milliseconds taken by all map tasks=288607
Total megabyte-milliseconds taken by all map tasks=295533568
Map-Reduce Framework
CPU time spent (ms)=0
Physical memory (bytes) snapshot=0
Virtual memory (bytes) snapshot=0
2019-07-11 10:10:31,288 ERROR [main] snapshot.ExportSnapshot: Snapshot export failed
org.apache.hadoop.hbase.snapshot.ExportSnapshotException: Task failed task_1562738985351_0004_m_000000
Job failed as tasks failed. failedMaps:1 failedReduces:0 killedMaps:0 killedReduces: 0 at org.apache.hadoop.hbase.snapshot.ExportSnapshot.runCopyJob(ExportSnapshot.java:839)
at org.apache.hadoop.hbase.snapshot.ExportSnapshot.doWork(ExportSnapshot.java:1078)
at org.apache.hadoop.hbase.util.AbstractHBaseTool.run(AbstractHBaseTool.java:154)
at org.apache.hadoop.util.ToolRunner.run(ToolRunner.java:70)
at org.apache.hadoop.hbase.util.AbstractHBaseTool.doStaticMain(AbstractHBaseTool.java:280)
at org.apache.hadoop.hbase.snapshot.ExportSnapshot.main(ExportSnapshot.java:1141)
【2】异常分析
这个报错信息是jvm的堆内存不够,便查询了hadoop运行mapreduce的时候jvm的默认值,得知在 hadoop的mapred-site.xml配置中有一个mapred.child.java.opts的参数,用于jvm运行时heap的运行参数和垃圾回收之类的参数的配置,heap的-Xmx默认值为200m,报错说明这个值是不够的,于是解决方案就是加大这个值。
这个值设置多大合适?https://blog.csdn.net/wjlwangluo/article/details/76667999文中说:一般情况下,该值设置为 总内存/并发数量(=核数)
【3】解决方案
# 进入目录
cd /opt/soft/hadoop/hadoop-3.1.2/etc/hadoop
# 进入文件编辑模式
vim mapred-site.xml
# 添加以下内容 <property>
<name>mapred.child.java.opts</name>
<value>-Xmx1024m</value>
</property>
【4】验证
# 重启hadoop、hbase:注意先停habse,并且不要要kill,因为hadoop在不断的切割,用stop停止,它会记录下来,下次启动继续切割
stop-hbase.sh
stop-all.sh
start-all.sh
start-hbase.sh # 再次迁移快照 hbase org.apache.hadoop.hbase.snapshot.ExportSnapshot -snapshot snapshot_tsdb_214 -copy-from hdfs://192.168.0.214:9000/hbase -copy-to hdfs://192.168.0.211:9000/hbase -mappers 20 -bandwidth 1024
查看进度是成功的:
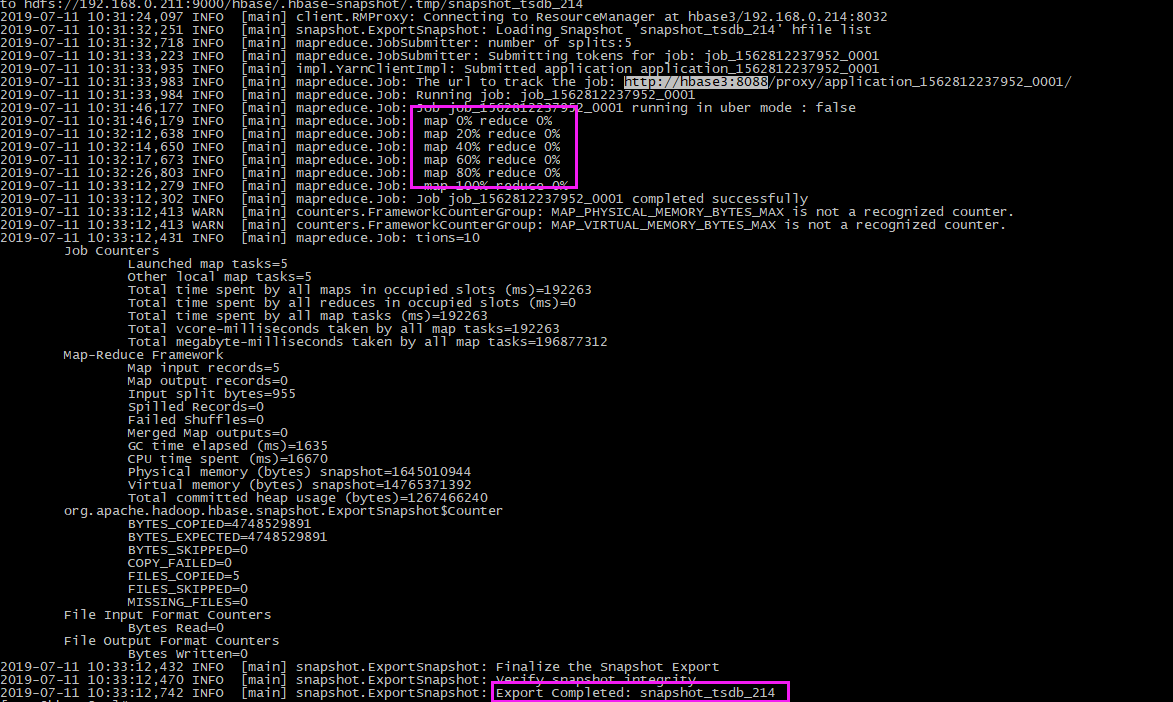
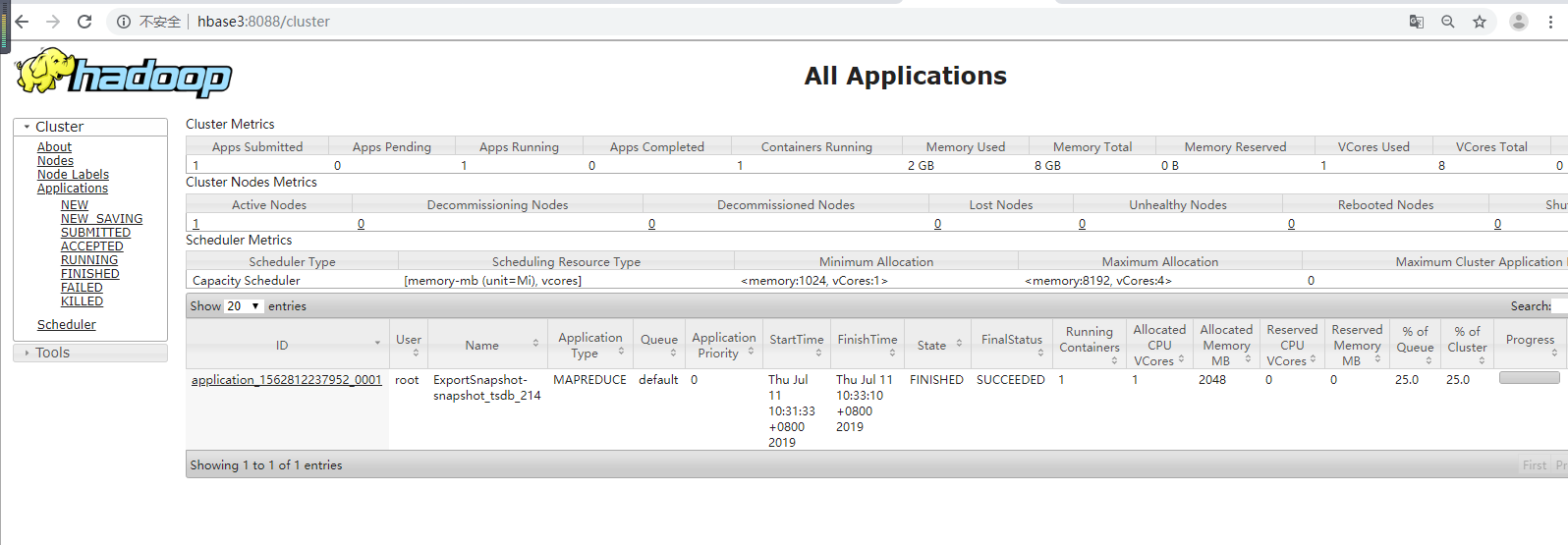
迁移过程中,在hbase1 上会产生 快照的 ./tmp文件
# 查看 hdfs上快照文件
hdfs dfs -ls -R /hbase/.hbase-snapshot
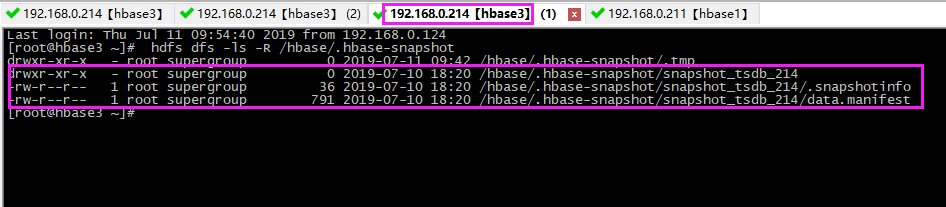
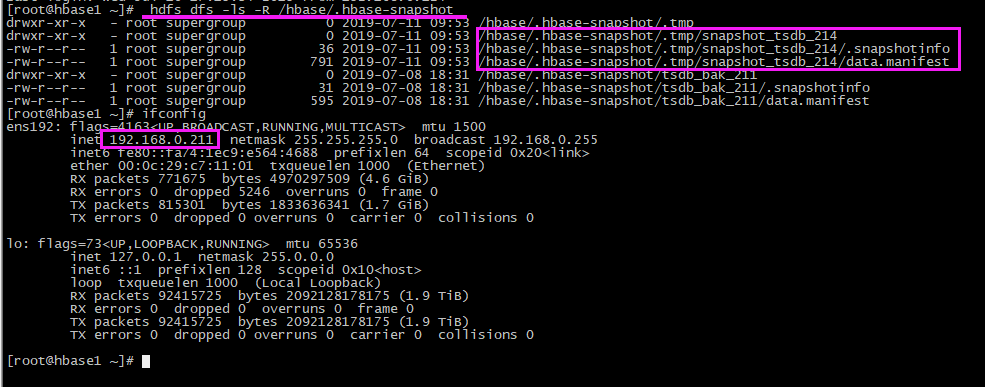
迁移完毕,在hbase1 上会生成了相应的快照
# 进入shell命令
habase shell
# 查看快照 list_snapshot

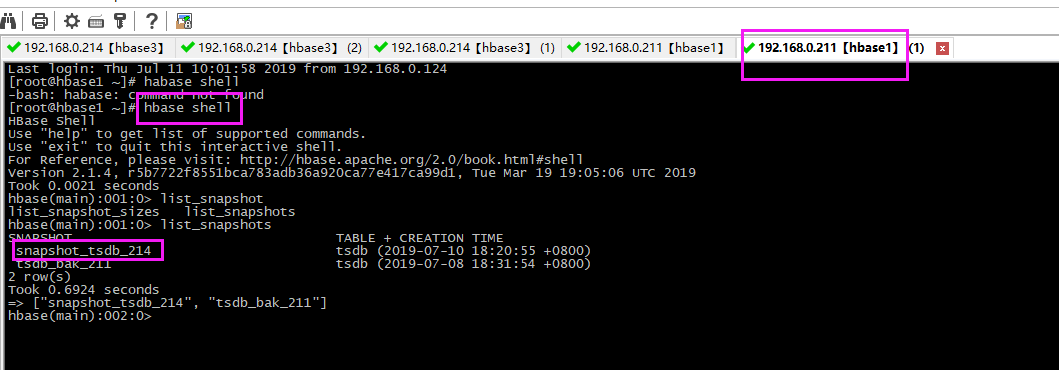
3、恢复数据
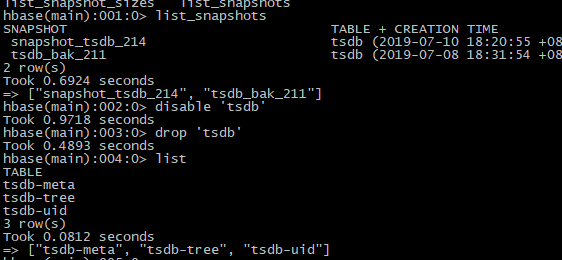
【1】删除hbase1的原始数据
## 我这里还是直接删除tsdb表
# disable表
disable 'tsdb'
# 查看
drop 'tsdb'

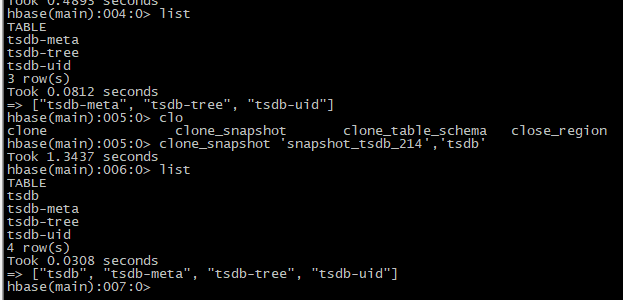
【2】还原数据
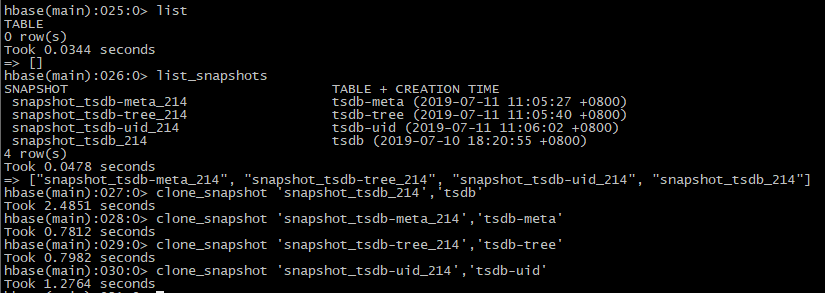
clone_snapshot 'snapshot_tsdb_214','tsdb'
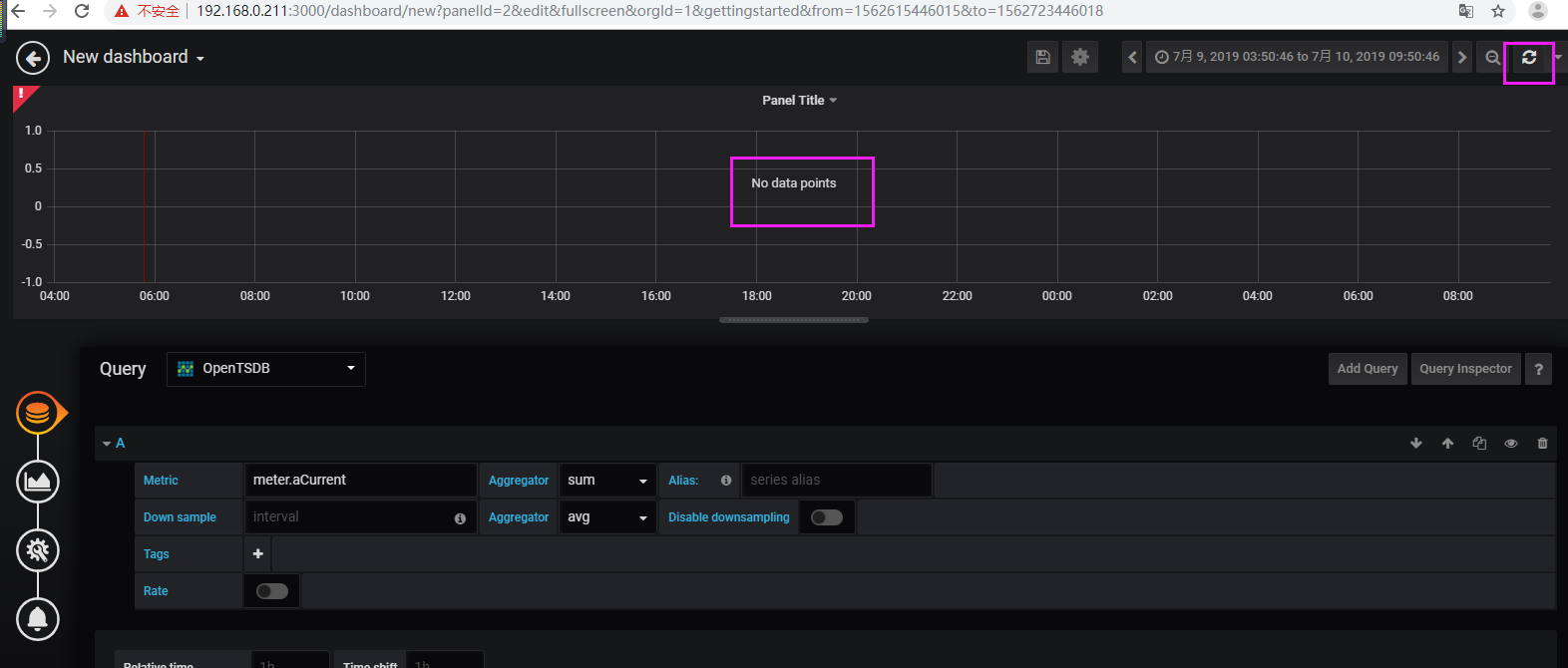
【3】验证
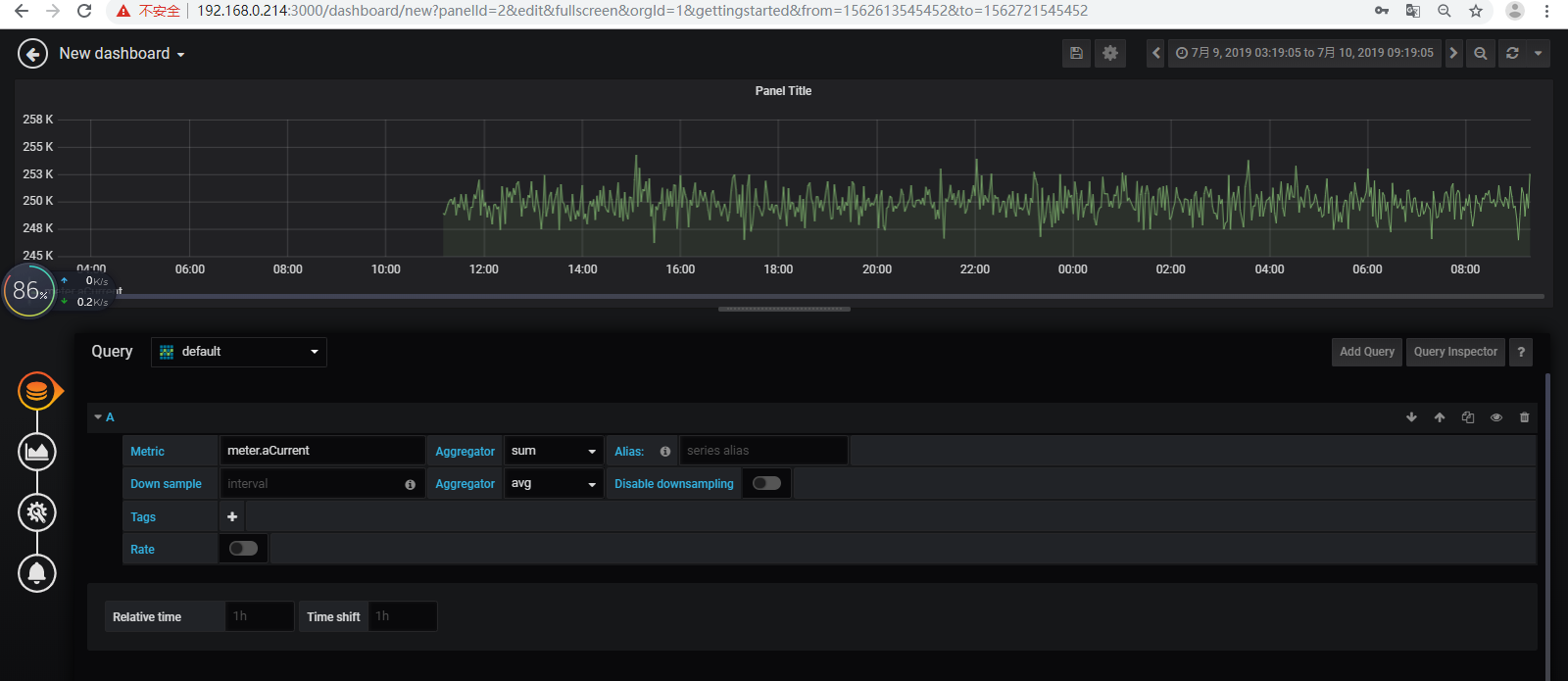
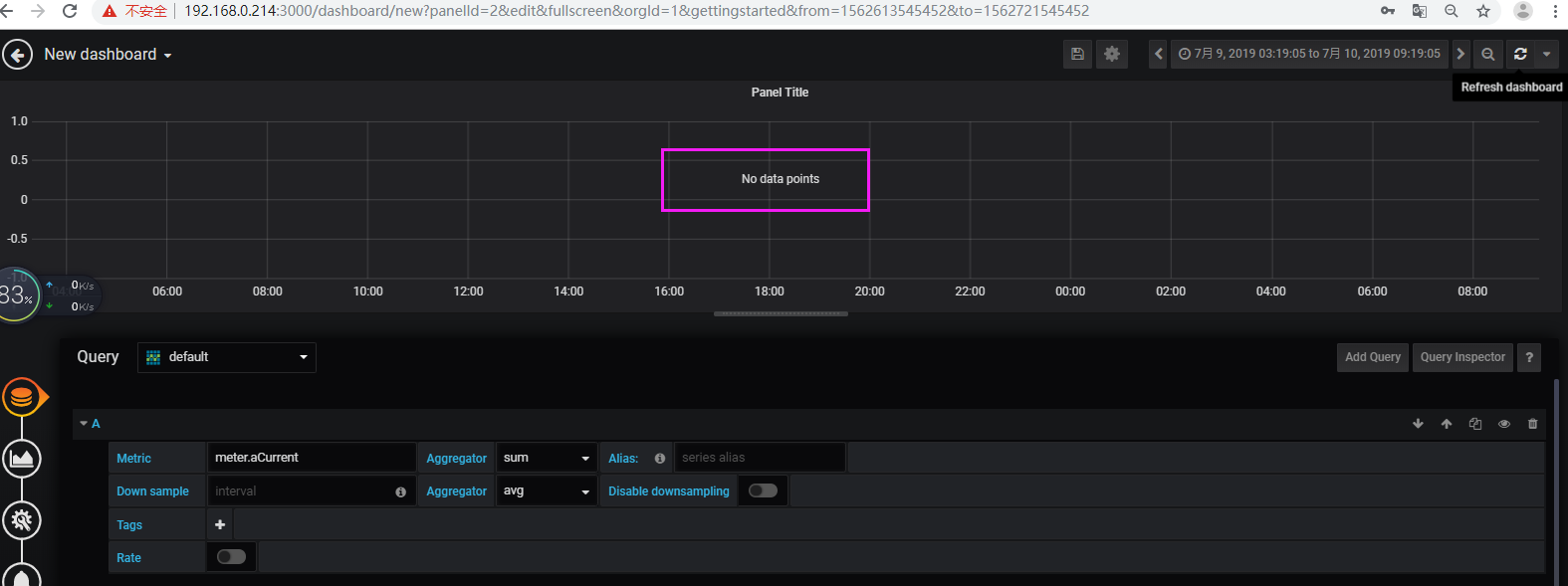
查验tsdb表存在且有数据,但是grafana查验无数据

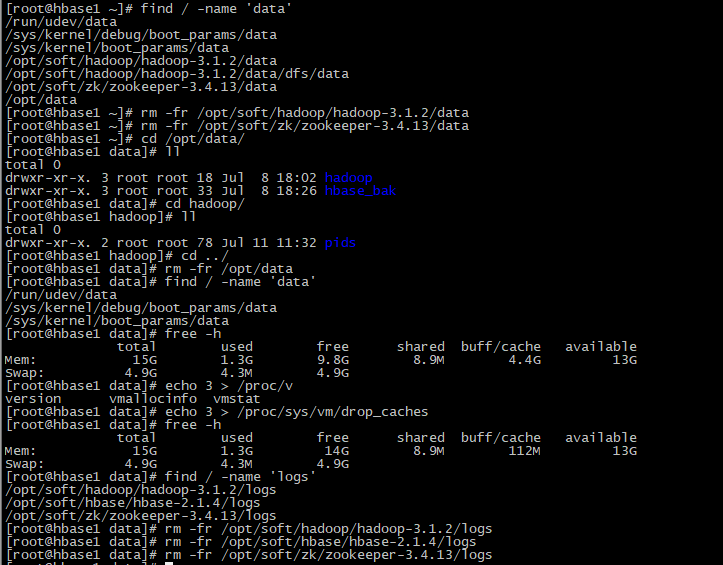
停止hadoop、zookeeper、hbase、opentsdb,删除了hbase1上的所有logs和data,格式化hdfs之后,再重启所有程序,再将tsdb相关的4个快照从214迁移过来进行还原,再次刷新就有数据了
三、总结
1、后面经验证,是opentsdb挂掉了,当opentsdb正常的时候,直接到上面第2步,只需要备份还原tsdb皆可。
2、另外验证restore_snapshot未成功,所以暂定还原用 clone_snapshot方法。
3、已验证,将快照传到目的服务器后,关闭源服务器,也可以进行还原。
4、验证:先把快照拷贝到本地,然后再上传到目的服务器的hdfs里面,进行恢复,结果:验证失败。
HBase备份还原OpenTSDB数据之Snapshot的更多相关文章
- HBase备份还原OpenTSDB数据之Export/Import(增量+全量)
前言 本文基于伪分布式搭建 hadoop+zookeeper+hbase+opentsdb之后,文章链接:https://www.cnblogs.com/yybrhr/p/11128149.html, ...
- 基于物理文件的HBase备份还原
前提说明: 1.HBase数据分表,所以备份的粒度是表. 2.备份的内容为Azure的Blob存储. HBase Blob备份 备份时,需要先将表disable,以保持数据一致性. 备份的工具可以用A ...
- elasticsearch数据备份还原
elasticsearch数据备份还原 1.在浏览器中运行http://XXX.XXX.XXX.XXX:9200/_flush,确保索引数据能保存到硬盘中. 2.原数据的备份.主要是elasticse ...
- SQL Server 大数据搬迁之文件组备份还原实战
一.本文所涉及的内容(Contents) 本文所涉及的内容(Contents) 背景(Contexts) 解决方案(Solution) 搬迁步骤(Procedure) 搬迁脚本(SQL Codes) ...
- MS SQL数据批量备份还原(适用于MS SQL 2005+) 分类: SQL Server 数据库 2015-03-10 14:32 103人阅读 评论(0) 收藏
我们知道通过Sql代理,可以实现数据库的定时备份功能:当数据库里的数据库很多时,备份一个数据库需要建立对应的定时作业,相对来说比较麻烦: 还好,微软自带的osql工具,比较实用,通过在命令行里里输入命 ...
- mysql innobackupex xtrabackup 大数据量 备份 还原
大数据量备份与还原,始终是个难点.当MYSQL超10G,用mysqldump来导出就比较慢了.在这里推荐xtrabackup,这个工具比mysqldump要快很多. 一.Xtrabackup介绍 1, ...
- DEDECMS网站数据备份还原教程
备份织梦网站数据 dedecms备份教程 进入DedeCms后台 -> 系统 -> 数据库备份/还原 备份文件在\data\backupdata 下载数据库备份资料\data\backup ...
- mysql innobackupex xtrabackup 大数据量 备份 还原(转)
原文:http://blog.51yip.com/mysql/1650.html 作者:海底苍鹰 大数据量备份与还原,始终是个难点.当MYSQL超10G,用mysqldump来导出就比较慢了.在这里推 ...
- 一次生产环境下MongoDB备份还原数据
最近开发一个版本的功能当中用到了MongoDB分页,懒于造数据,于是就研究了下从生产环境上导出数据到本地来进行测试. 研究了一下,发现MongoDB的备份还原和MySQL语法还挺类似,下面请看详细介绍 ...
随机推荐
- HDU 1069 Monkey and Banana dp 题解
HDU 1069 Monkey and Banana 纵有疾风起 题目大意 一堆科学家研究猩猩的智商,给他M种长方体,每种N个.然后,将一个香蕉挂在屋顶,让猩猩通过 叠长方体来够到香蕉. 现在给你M种 ...
- 漫漫人生路,我们该何去何从! Python让我找到了方向
互联网寒冬 2017年冬天,是我人生中最难熬的一个冬天,其实2017年的冬天并不算太冷,比这冬日的寒风还要严寒的要属这所谓的"互联网寒冬"吧!各大厂裁员的消息充斥着互联网,互联网表 ...
- P4643 [国家集训队]阿狸和桃子的游戏
传送门 这题看一眼就很不可做 考虑对于任意一个最终状态,对于一条边的贡献分成三种情况 如果此边连接的两点属于 $A$,那么对 $A$ 的贡献就是边权 $w$,即对答案的贡献为 $+w$ 如果两点都属于 ...
- 计算机体系结构——流水线技术(Pipelining)
本文导读: 一.并行技术 .并行技术分类 .新技术的设计与实现 .指令周期 二.流水线技术 .什么是流水线 .指令重叠方式 .流水工作设计 .流水线的描述方法(时空图) .流水线特点 三.流水线的分类 ...
- linux中的一些常用命令
shutdown -h now 现在马上关机 shutdown -r now 现在重新启动 reboot 现在重新启动 su - 如果当前是普通用户,则输入这条命令切换到管理员用户(root),如果要 ...
- 总结const、readonly、static三者的区别【收藏、转载】20190614
总结const.readonly.static三者的区别 const:静态常量,也称编译时常量(compile-time constants),属于类型级,通过类名直接访问,被所有对象共享! a.叫编 ...
- 转载——CentOS---网络配置详解
看到一篇关于Centos网络配置很详细的文章,特此复制来.原文网址:http://blog.chinaunix.net/uid-26495963-id-3230810.html 一.配置文件详解在RH ...
- TensorFlow 安装及使用
安装 (1)安装包安装:pip install tensorflow==1.14 -i https://pypi.douban.com/simple virtualenv -p /usr/bin/py ...
- Linux shell中自动完成登录
在写shell脚本时,需要登录到不同的服务器上执行相关命令,在未建立信任之前如何批量操作. 1.ssh 首次登录服务器时会提示RSA key fingerprint输入yes/no,可以通过下面的方法 ...
- css 鼠标经过图片缓慢切换图片、鼠标离开缓慢还原
https://blog.csdn.net/qq_26780317/article/details/80486766 一.控制背景图片在一个圆形div内切换 .header .logo { width ...