mysql 主从复制 (1)
Mysql主从配置
大型网站为了软解大量的并发访问,除了在网站实现分布式负载均衡,远远不够。到了数据业务层、数据访问层,如果还是传统的数据结构,或者只是单单靠一台服务器扛,如此多的数据库连接操作,数据库必然会崩溃,数据丢失的话,后果更是不堪设想。这时候,我们会考虑如何减少数据库的联接,一方面采用优秀的代码框架,进行代码的优化,采用优秀的数据缓存技术如:memcached,如果资金丰厚的话,必然会想到假设服务器群,来分担主数据库的压力。今天总结一下利用MySQL主从配置,实现读写分离,减轻数据库压力.
这里我们一阿里云为例来配置主从. mysql和mariadb是一样的配置的.我这里一mariadb为实际案例. 配置的时候两台阿里云使用的是内网地址.
1.阿里云部署环境
主机( master_mysql ): 192.168.1.200 OS:CentOS 7.4
从机( slave_mysql ): 192.168.1.201 OS: CentOS 7.4
主机和从机都需要安装好mysql 或者Mariadb数据库
2.主数据库的配置
首先使用命令
cd /etc
然后在执行
ls my.cnf

在使用编辑器vim打开my.cnf文件
vim my.cnf 按 i 进入编辑模式
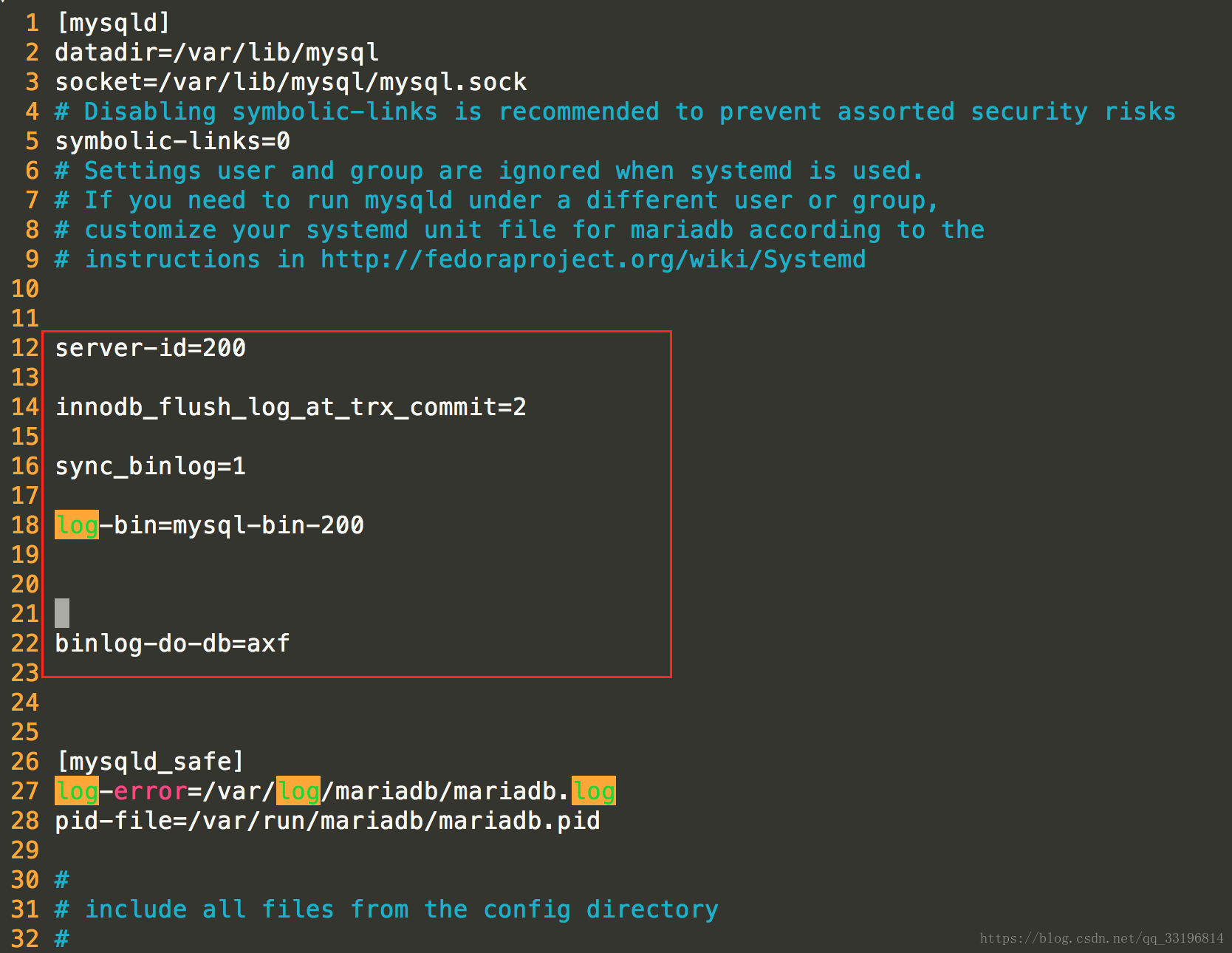
几条配置文件的含义如下:
#设置主服务 的ID (id可以自己随便设置但是要保证和slave的id不一样)
server-id=200
innodb_flush_log_at_trx_commit=2 #(参数的含义如下)
# 0:如果innodb_flush_log_at_trx_commit的值为0,log buffer每秒就会被刷写日志文件到磁盘,提交事务的时候不做任何操作(执行是由mysql的master thread线程来执行的。
# 主线程中每秒会将重做日志缓冲写入磁盘的重做日志文件(REDO LOG)中。不论事务是否已经提交)默认的日志文件是ib_logfile0,ib_logfile1
# 1:当设为默认值1的时候,每次提交事务的时候,都会将log buffer刷写到日志。
# 2:如果设为2,每次提交事务都会写日志,但并不会执行刷的操作。每秒定时会刷到日志文件。要注意的是,并不能保证100%每秒一定都会刷到磁盘,这要取决于进程的调度。
# 每次事务提交的时候将数据写入事务日志,而这里的写入仅是调用了文件系统的写入操作,而文件系统是有 缓存的,所以这个写入并不能保证数据已经写入到物理磁盘
# 默认值1是为了保证完整的ACID。当然,你可以将这个配置项设为1以外的值来换取更高的性能,但是在系统崩溃的时候,你将会丢失1秒的数据。
# 设为0的话,mysqld进程崩溃的时候,就会丢失最后1秒的事务。设为2,只有在操作系统崩溃或者断电的时候才会丢失最后1秒的数据。InnoDB在做恢复的时候会忽略这个值。
# 总结
# 设为1当然是最安全的,但性能页是最差的(相对其他两个参数而言,但不是不能接受)。如果对数据一致性和完整性要求不高,完全可以设为2,如果只最求性能,例如高并发写的日志服务器,设为0来获得更高性能
#开启binlog 志同步功能
sync_binlog=1
#binlog 日志文件名
log-bin=mysql-bin-200
# 这个表示只同步某个库 (如果没有此项,表示同步所有的库)
binlog-do-db=xxxx
上面的配置写好之后按键盘ESC键在按shift+:输入wq.保存退出.
重启我们的主机数据库看自己的数据库是什么选用不同的命令
systemctl restart mysql或者 systemctl restart mariadb
完成后使用
mysql -u root -p 登录mysql或者mariadb.输入登录密码.这个是自己的数据库的账户密码.
再来给授权给从数据库服务 192.168.1.201, 户名mark,密码123456
可以根据自己的情况来配置
grant replication slave on *.* to 'mark'@'192.168.1.201' identified by '123456';
查看主数据库的状态
show master status;
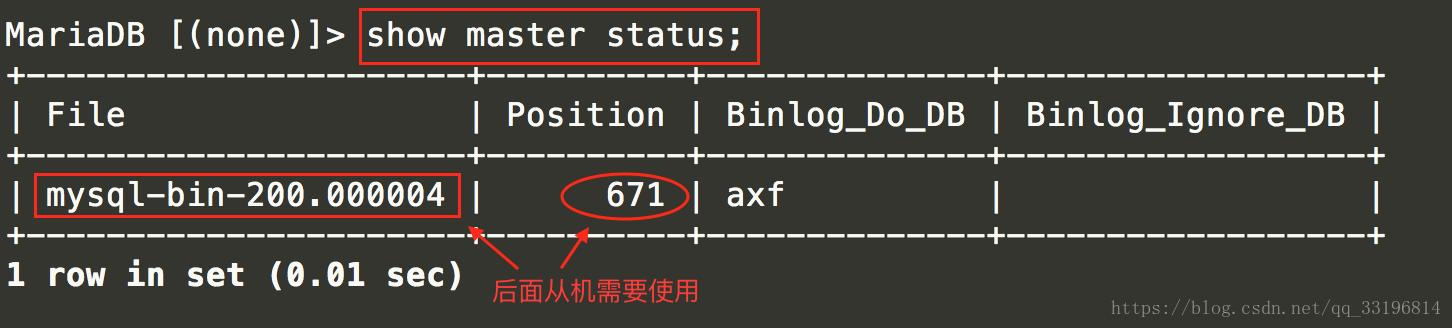
到这一步我们就已经完成主数据库的配置了.
3.从数据库的配置
和前面的主机配置大同小异.
server-id=201
innodb_flush_log_at_trx_commit=2
sync_binlog=1
log-bin=mysql-bin-201
配置完成后一样的保存退出.在重启从机的数据库.
systemctl restart mysql或者 systemctl restart mariadb
mysql -u root -p 登录mysql或者mariadb.输入登录密码.这个是自己的数据库的账户密码.
如果配置了同步的数据库,则在从机数据库上面要有一个和主机配置的数据库一样的数据库.
配置从机连接master
change master to master_host='192.168.1.200',master_user='mark' ,master_password='12345', master_log_file='mysql- bin-200.000004' ,master_log_pos=671;
参数说明:
master_host: 主机的ip
master_user : 主机授权的用户.
master_password : 主机授权时候填写的密码
master_log_file : 主机show master status;中的File
master_log_pos: 主机show master status;中的Position.
配置完成后启动slave.
start slave;
最后查看slave的状态
show slave status \G;
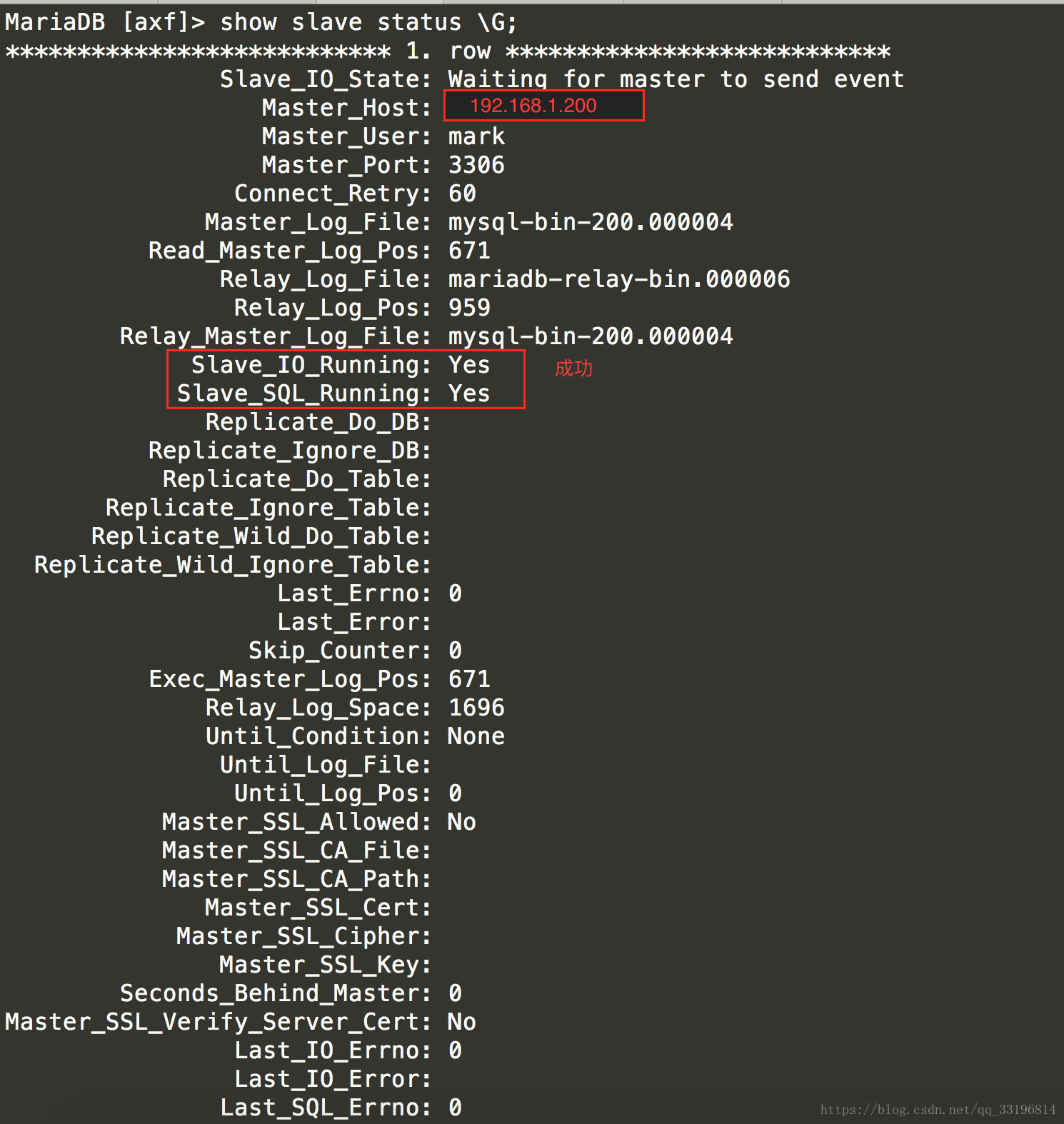
看到上图的状态就已经完全配置好主从数据库了.
4.验证是否配置成功
可以在主库上创建个库,再在从库上刷新查看是否同步
5.故障排除.
如果出现1236错误

可以通过:
停止从机.
stop slave
重置从机
reset slave
启动从机
start slave
来解决这个错误

---------------------
作者:Li-boss
来源:CSDN
原文:https://blog.csdn.net/qq_33196814/article/details/81513907
版权声明:本文为博主原创文章,转载请附上博文链
mysql 主从复制 (1)的更多相关文章
- MySQL主从复制(Master-Slave)实践
MySQL数据库自身提供的主从复制功能可以方便的实现数据的多处自动备份,实现数据库的拓展.多个数据备份不仅可以加强数据的安全性,通过实现读写分离还能进一步提升数据库的负载性能. 下图就描述了一个多个数 ...
- 2.快速部署MySQL主从复制
1.快速部署MySQL主从复制 [root@mysql ~]# mysql -uroot -p123456 -S /data/3307/mysql.sock -e "show slave ...
- MySQL 主从复制与读写分离概念及架构分析
1.MySQL主从复制入门 首先,我们看一个图: 影响MySQL-A数据库的操作,在数据库执行后,都会写入本地的日志系统A中. 假设,实时的将变化了的日志系统中的数据库事件操作,在MYSQL-A的33 ...
- MySQL主从复制原理及配置详细过程以及主从复制集群自动化部署的实现
一.复制概述 Mysql内建的复制功能是构建大型,高性能应用程序的基础.将Mysql的数据分布到多个系统上去,这种分布的机制,是通过将Mysql的某一台主机的数据复制到其它主机(slaves)上,并重 ...
- MySQL主从复制
Mysql主从复制介绍 MySQL支持单向.双向.链式级联.实时.异步复制.在复制过程中,一台服务器充当服务器(Master),而一个或多个其它的服务器充当从服务器(Slave). 复制可以是单向:M ...
- mysql主从复制实现数据库同步
mysql主从复制相信已经用得很多了,但是由于工作原因一直没怎么用过.趁着这段时间相对空闲,也就自己实现一遍.尽管互联网上已有大把类似的文章,但是自身实现的仍然值得记录. 环境: 主服务器:cento ...
- mysql主从复制配置
使用mysql主从复制的好处有: 1.采用主从服务器这种架构,稳定性得以提升.如果主服务器发生故障,我们可以使用从服务器来提供服务. 2.在主从服务器上分开处理用户的请求,可以提升数据处理效率. 3. ...
- 【大型网站技术实践】初级篇:搭建MySQL主从复制经典架构
一.业务发展驱动数据发展 随着网站业务的不断发展,用户量的不断增加,数据量成倍地增长,数据库的访问量也呈线性地增长.特别是在用户访问高峰期间,并发访问量突然增大,数据库的负载压力也会增大,如果架构方案 ...
- Mysql主从复制,读写分离(mysql-proxy),双主结构完整构建过程
下面介绍MySQL主从复制,读写分离,双主结构完整构建过程,不涉及过多理论,只有实验和配置的过程. Mysql主从复制(转载请注明出处,博文地址:) 原理是master将改变记录到二进制日志(bina ...
- MySQL主从复制中常见的3个错误及填坑方案
一.问题描述 主从复制错误一直是MySQL DBA一直填不完的坑,如鲠在喉,也有人说mysql主从复制不稳定云云,其实MySQL复制比我们想象中要坚强得多,而绝大部分DBA却认为只要跳过错误继续复制就 ...
随机推荐
- Vue 实现一个分页组件
实现分页组件要分三个部分 样式,逻辑,和引用 首先新建一个vue文件用来承载组件内容 第一步:构建样式 <template> <nav> <ul class=" ...
- Nodejs 学习笔记 --- 安装与环境配置
一.安装Node.js步骤 1.下载对应自己系统对应的 Node.js 版本,地址:https://nodejs.org/zh-cn/ 2.选安装目录进行安装 3.环境配置 ...
- vim插件YouCompleteMe安装
这里在ubuntu16.4下安装的需要提前安装cmake clang python3sudo apt-get install clang 因为不能访问google,安装时,安装go的插件会访问goo ...
- Docker镜像+nginx 部署 vue 项目
一.打包vue项目 在开发完的vue项目输入如下命名,打包生成dist文件夹 yarn build / npm run build 此时根目录会多出一个文件夹:dist文件夹,里面就是我们要发布的东西 ...
- centos误删除文件如何恢复
当意识到误删除文件后,切忌千万不要再频繁写入了,否则你的数据恢复的数量将会很少. 而我们要做的是,第一时间把服务器上的服务全部停掉,直接killall 进程名 或者 kill -9 pid . 然后把 ...
- Q开头的类找不到,无法加载插件:com.mysema.maven:apt-maven-plugin
http://www.jspxcms.com/documentation/297.html 如果出现无法加载com.mysema.maven:apt-maven-plugin插件的情况,通常是由于ma ...
- nodejs 更新代码自动刷新页面
安装第三方工具: nodemon npm install --global nodemon 安装完毕后使用: 之前使用: node xxx.js 改成 nodemon xxx.js 只要通过nodem ...
- 基于cdn方式的vue+element-ui的单页面架构
一.下载vue2.x,下载element-ui.js以及css 二.html文件 <!DOCTYPE html> <html> <head> <meta ch ...
- [Poj2349]Arctic Network(二分,最小生成树)
[Poj2349]Arctic Network Description 国防部(DND)要用无线网络连接北部几个哨所.两种不同的通信技术被用于建立网络:每一个哨所有一个无线电收发器,一些哨所将有一个卫 ...
- 王垠-40行代码 -cps.ss
;; A simple CPS transformer which does proper tail-call and does not ;; duplicate contexts for if-ex ...