教你建立SQL数据库的表分区
1)新建一个数据库


2)添加几个文件组
3)回到“常规”选项卡,添加数据库文件
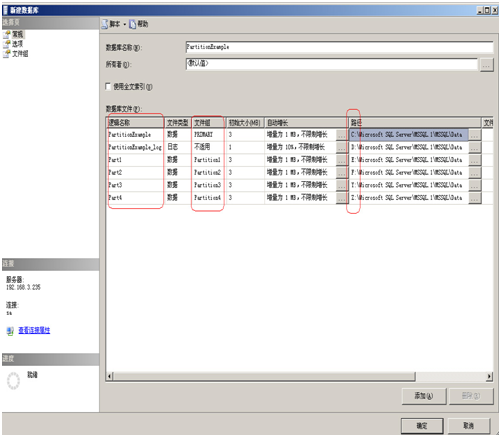
看到用红色框框起来的地方没?上一步中建立的文件组在这里就用上了。再看后面的路径,我把每一个文件都单独放在不同的磁盘上,而且最好都是单独的放在不同的物理盘上,这样会大大提高数据的性能。 点击“确定”数据库就算创建完成了。
4)接下来要做的是建立一个分区行数,SQL语句如下:大家学习的时候最好不要直接COPY,动手把它抄一遍也好。
|
以下是代码片段: create partition function PartFuncForExample(Datetime) |
这里我准备用表中的某个时间字段作为分区的条件,当然你也可以用其他的,比如INT之类,只要好分段的都可以。
这里注意 Right 关键字,意思就是当记录的时间(在下面会被指到表的某个字段)大于等于20000101的时候,数据会被分到下一个区间,比如2000年1月1号之前的数据会被分到一区,包含2000年1月1号和之后的数据会被分到二区,以此类推。Right 也可以使用Left替代,意思同上类似。另外,上面我定义了四个分割点,这四个分割点是根据我们刚刚创建的文件组来决定的。四个分割点就能产生5个区间段,我们把每个区间段的数据存入一个文件组。
正确执行上述语句后你可以在数据里找到以“PartFuncForExample”命名的分区函数,如下图

5)把分区函数建立好以后,我们再来建立分区方案。目的是为了把分区函数产生的分区映射到文件数据组里。分区函数是告诉数据库如何分区数据,而分区方案是告诉数据库如何把已分区的数据存到哪个文件组里。
下面我来创建分区方案。
|
以下是代码片段: Create Partition Scheme PartSchForExample //创建一个分区方案+分区方案名称 |
正确执行后能在分区方案中看到,如下图

6)马上就快要大公告成了,下面我们来建立要分区存储的表,该表的数据理论上应该是非常非常多的,百万级别的记录以上而且基本上是不更新的。要不然建立分区存储就没多大意义了。
|
以下是代码片段: Create Table PartitionTable( |
执行这段SQL,没报错的话就大功告成了,呵呵.
总结:
分区存储提高了数据库的性能,被分区存储的数据物理上是多个文件,但逻辑上任然是一个表,对表的任何操作都跟没分区之前一样。插入、删除、查询、更新等操作的时候,数据库会自动为你找到对应的分区,然后执行操作。另外的话
把多个数据文件、日志文件都分别部署在不同的高性能物理盘上,也能大大提高性能.
当然,分区存储的好处还有很多我不知道的,欢迎高手们踊跃跟帖赐教,有错误的地方也欢迎踊跃拍砖!
---存在即是合理---
教你建立SQL数据库的表分区的更多相关文章
- SQL Server 2008 表分区的含义
https://www.cnblogs.com/knowledgesea/p/3696912.html 继续看这个文档 http://www.360doc.com/content/16/0104/11 ...
- SQL Server 创建表分区
原文:SQL Server 创建表分区 先准备测试表 CREATE TABLE [dbo].[Employee] ( EmployeeNo ,) PRIMARY KEY, EmployeeName ) ...
- MySQL数据库分表分区(一)(转)
面对当今大数据存储,设想当mysql中一个表的总记录超过1000W,会出现性能的大幅度下降吗? 答案是肯定的,一个表的总记录超过1000W,在操作系统层面检索也是效率非常低的 解决方案: 目前针对 ...
- 教你管理SQL数据库系列(1-4)
原文 教你管理 SQL Server 数据库(1)数据库的结构 http://bbs.51cto.com/thread-1084951-1.html教你管理 SQL Server 数据库(2)系统数 ...
- SQL Server 当表分区遇上唯一约束(转载)
一.前言 我已经在高兴对服务器创建了表分区并且获得良好性能和自动化管理分区切换的时候,某一天,开发人员告诉我,某表的两个字段的数据不唯一,需要为这两个字段创建唯一索引的时候,这一切就变得不完美了.列的 ...
- SQL Server 2012 表分区
转载于:https://www.cnblogs.com/knowledgesea/p/3696912.html 什么是表分区 一般建立数据库表时,表数据都存放在一个文件里. 但是如果是分区表的话,表数 ...
- sql数据库的表连接方式图文详解
sql数据库表连接,主要分为:内连接.外连接(左连接.右连接 .全连接).交叉连接,今天统一整合一下,看看他们的区别. 首先建表填充值. 学生表:student(id,姓名,年龄,性别 ) 成绩表 ...
- 用SQL数据库做多表关联应怎样设计库结构20170527
http://77857.blog.51cto.com/67857/143872/ 多表关联的话表之间必须得存在关系才行呢,这样建立外键约束就行了, 关系表中插入主表的主键做外键. 假设表1学生表st ...
- Protel99se教程一:建立一个数据库文件
学习Protel99 SE的第一步,是建立一个DDB文件,也就是说,使用protel99se进行电路图和PCB设计,以及其它的数据,都存放在一个统一的DDB数据库中的 一.打开protel 99se后 ...
随机推荐
- 牛客提高D6t3 分班问题
分析 就就就是推柿子 看官方题解吧/px 代码 #include<iostream> #include<cstdio> #include<cstring> #inc ...
- day39—JavaScript缓冲运动
转行学开发,代码100天!——2018-04-24 今天继续学习JavaScript运动之缓冲运动.相对于匀速运动,缓冲运动的不同之处在于其速度值是不断变化的,越靠近目标点,速度越小. 即可以表示为: ...
- day02-Javascript之document.write()方法
转行学开发,代码100天.——2018-03-18 document.write()方法作为Javascript的常用输出方式,可输出字符串,标签元素,变量等. document.write(&quo ...
- delphi中的idhttpserver如何才能收到idhttp发送来的exe\rar文件呢
http://zhidao.baidu.com/link?url=-q2oXqYCKBZ9OgFDEHAcQwQEY_NroHcqGvVfKW67X5sF9LdjAAB_HPXQo04VxStFVS7 ...
- python 可变类型和不可变类型
1. 什么是不可变类型变量对应的值中的数据是不能被修改,如果修改就会生成一个新的值从而分配新的内存空间.不可变类型: 数字(int,long,float) 布尔(bool) 字符串(string) 元 ...
- 希希敬敬对Alpha阶段测试报告
已经完成的功能:1 GUI界面效果已经达到了设计要求,经过review代码完成度较好,GUI.PY代码可以使用,完成了“贴吧名字关键字与URL关联”. 2 能够实现"贴吧名字关键字与URL关 ...
- from、includes、indexOf
from.includes.indexOf:https://blog.csdn.net/j59580/article/details/53897630?utm_source=blogxgwz1 语法 ...
- for in 和for of的区别
for in 和for of的区别:https://www.jianshu.com/p/c43f418d6bf0 1 遍历数组通常用for循环 ES5的话也可以使用forEach,ES5具有遍历数组功 ...
- ORM多对多的实现
#coding=utf-8 from sqlalchemy import Table, Column, Integer,String,DATE, ForeignKey from sqlalchemy. ...
- untiy3D-初学NGUI遇到问题
1,如果需要能在场景中右键添加NGUI的控件,我们需要做好下图两个框住的地方 第一个框可以使用键盘的W选中,或者鼠标点击 第二个框我们选中UIRoot然后保持它的脚本文件为打开状态,才可以使用右键添加 ...