Python 分页和shell命令行模式
前言
除了手动添加你的文章后外,你还可以用命令行来添加,python 自带了一种命令行 就是 shell
快速添加博文:Shell命令行模式
在你的目录下:mysite
python manage.py shell
导入Blog模型:
>>> from blog.models import Blog
验证是否成功引用:
>>> dir()
查看所有博文:
>>> Blog.objects.all()
查看博文数量:
>>> Blog.objects.count()
模型新增对象
实例化对象:
>>> blog = Blog()
查看是否成功:
>>> dir()
因为库中没有,所以库中查不到:
>>> Blog.objects.all()
添加文章标题:
>>> blog.title = "shell下第一篇"
添加文章内容:
>>> blog.context = "xxxxxxxxxxxxxx"
引入BlogType:
>>> from blog.models import BlogType
查询所有BlogType:
>>> BlogType.objects.all()
添加文章类型:
>>> blog.blog_type = BlogType.objects.all()[0]
引入Django的User模型:
>>> from django.contrib.auth.models import User
添加作者:
>>> blog.author = User.objects.all()[0]
保存入库:
>>> blog.save()
查询最新修改时间:
>>> blog.last_updated_time
如果这样一篇一篇当然麻烦,就可以用for 循环来添加
添加大量文章:
>>> for i in range(1, 31):
... blog = Blog()
... blog.title = "for %s" % i
... blog.content = "xxxx: %s" % i
... blog.blog_type = BlogType.objects.all()[0]
... blog.author = User.objects.all()[0]
... blog.save()
记住上面。。。 后面必须要空格
查看是否成功新增:
>>> Blog.objects.all().count()
引入分页器
你的文章过多的话,还是需要分页的,python 自带一个软件
>>> from django.core.paginator import Paginator
查看是否成功引入:
>>> dir()
有些不需要的可以移除,比如:
>>> del Blog
因为后面需要用分类页码来分页
这里最好重新开始 退出
>>> exit()
实例化分页器:
>>> paginator = Paginator(blogs, 10) # 第一个参数是具体的对象列表,第二个参数是每页文章数
模型有默认的排序,但不知道是不是每页的内容不一样,即第一篇博文可能在这一页出现,同时在另一页也出现。所以,最好有个排序规则。按照这个排序规则分页。
然后在你的 blog/models 下修改
...
class Blog(models.Model):
title = models.CharField(max_length=50)
blog_type = models.ForeignKey(BlogType, on_delete=models.DO_NOTHING)
content = models.TextField()
author = models.ForeignKey(User, on_delete=models.DO_NOTHING)
created_time = models.DateTimeField(auto_now_add=True)
last_updated_time = models.DateTimeField(auto_now=True) def __str__(self):
return "<Blog: %s>" % self.title class Meta:
ordering = ['-created_time'] # 按照created_time倒序排序
然后重新 数据库和更新
$ python manage.py makemigrations
$ python manage.py migrate
重新打开shell,引入需要的包(Blog、Paginator),再次实例化分页器:
>>> paginator = Paginator(blogs, 10)
可以打印出paginator:
>>> paginator
查看pagnitor有什么属性和方法:
>>> dir(paginator)
查看有多少篇文章:
>>> paginator.count
查看页码:
>>> paginator.page_range
取第一页:
>>> page1 = paginator.page(1)
分页的使用
过GET方法获取请求参数,例如: http://127.0.0.1:8000/blog/?page=2
修改blog/views.py:
from django.shortcuts import render_to_response, get_object_or_404
from django.core.paginator import Paginator
from .models import Blog, BlogType def blog_list(request): blogs_all_list = Blog.objects.all()
paginator = Paginator(blogs_all_list, 10)
page_num = request.GET.get('page', 1) # 获取url的页码参数。GET返回字典,page_num默认为1
page_of_blogs = paginator.get_page(page_num) context = {}
context['page_of_blogs'] = page_of_blogs
# context['blogs_count'] = Blog.objects.all().count()
context['blog_types'] = BlogType.objects.all()
return render_to_response('blog/blog_list.html', context)
...
修改blog/templates/blog/blog_list.html:
{% extends 'base.html' %}
{% block title %}
我的网站
{% endblock %}
{% block nav_blog_active %}
active
{% endblock %}
{% load staticfiles %}
{% block header_extends %}
<link rel="stylesheet" href="{% static 'blog/blog.css' %}">
{% endblock %}
{% block content %}
<div class="container">
<div class="row">
<div class="col-xs-12 col-sm-8 col-md-9 col-lg-10">
<div class="panel panel-default">
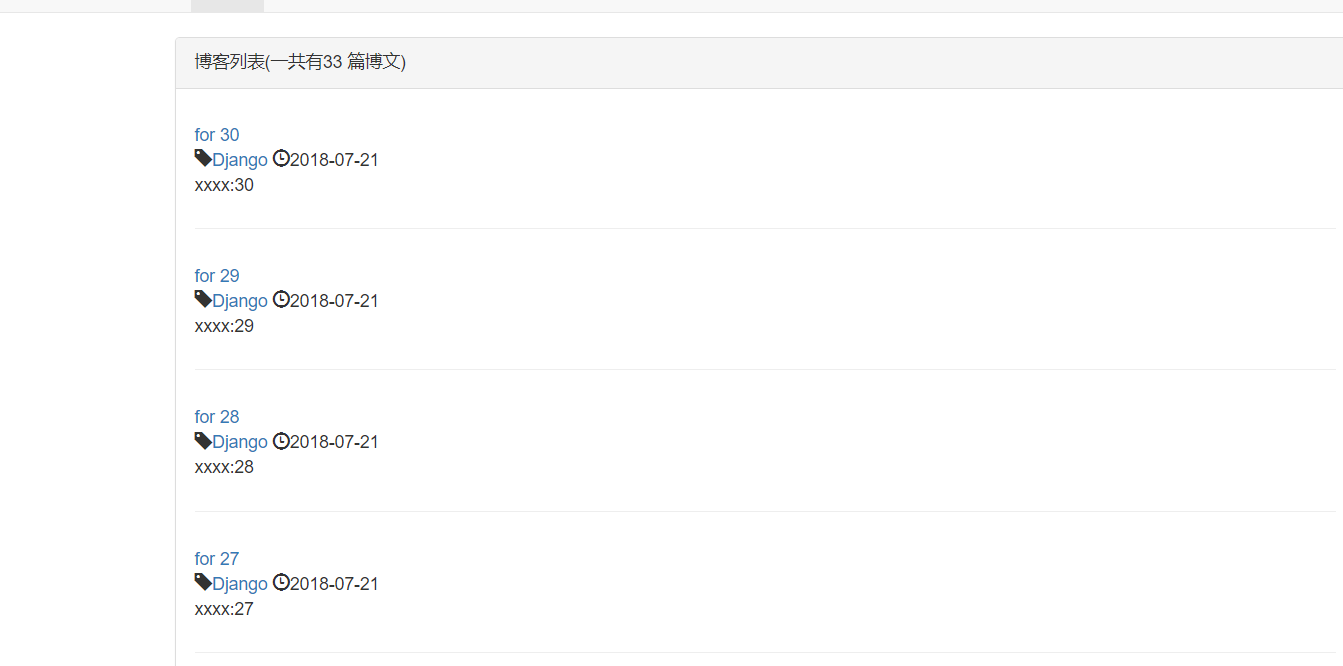
<div class="panel-heading">{% block blog_list_title %}博客列表(一共有{{ page_of_blogs.paginator.count }} 篇博文){% endblock %}</div>
<div class="panel-body">
{% for blog in page_of_blogs.object_list %}
<div class="blog">
<h3></h3><a href="{% url 'blog_detail' blog.pk %}">{{ blog.title }}</a></h3>
<p class="blog-info">
<span class="glyphicon glyphicon-tag"></span><a href="{% url 'blogs_with_type' blog.blog_type.pk %}">{{ blog.blog_type }}</a>
<span class="glyphicon glyphicon-time"></span>{{ blog.created_time|date:"Y-m-d" }}
</p>
<p>{{ blog.context|truncatechars:120 }}</p>
</div>
{% empty %}
<div class="blog">
<h3>---暂无博文,敬请期待---</h3>
</div>
{% endfor %}
</div>
</div>
</div>
<div class="hidden-xs col-sm-4 col-md-3 col-lg-2">
<div class="panel panel-default">
<div class="panel-heading">博客分类</div>
<div class="panel-body">
<ul class="blog-types">
{% for blog_type in blog_types %}
<li>
<a href="{% url 'blogs_with_type' blog_type.pk %}">{{ blog_type.type_name }}</a>
</li>
{% empty %}
<li>暂无分类</li>
{% endfor %}
</ul>
</div>
</div>
</div>
</div>
<div>
<ul class="pagination">
<li>
{# 上一页 #}
{% if page_of_blogs.has_previous %}
<a href="?page={{ page_of_blogs.previous_page_number }}" aria-label="Previous">
<span aria-hidden="true">«</span>
</a>
{% else %}
<span aria-hidden="true">«</span>
{% endif %}
</li>
<li>
{# 页码 #}
{% for page_num in page_of_blogs.paginator.page_range %}
<a href="?page={{ page_num }}">{{ page_num }}</a>
{% endfor %}
</li>
<li>
{# 下一页 #}
{% if page_of_blogs.has_next %}
<a href="?page={{ page_of_blogs.next_page_number }}" aria-label="Next">
<span aria-hidden="true">»</span>
</a>
{% else %}
<span aria-hidden="true">»</span>
{% endif %}
</li>
</ul>
</div>
</div>
{% endblock %}
然后 运行虚拟环境p
python manage.py runserver
就可以看到咯
Python 分页和shell命令行模式的更多相关文章
- 使用github的使用,利用git shell命令行模式进行操作
一.登录到git,新建一个版本仓库 二.在"Repository name"一栏里填写版本仓库的名称,如"test",Description栏是描述,可填可不填 ...
- python中执行shell命令行read结果
+++++++++++++++++++++++++++++ python执行shell命令1 os.system 可以返回运行shell命令状态,同时会在终端输出运行结果 例如 ipython中运行如 ...
- python如何在shell命令行执行创建用户命令
- 如何在命令行模式下查看Python帮助文档---dir、help、__doc__
如何在命令行模式下查看Python帮助文档---dir.help.__doc__ 1.dir函数式可以查看对象的属性,使用方法很简单,举str类型为例,在Python命令窗口输入 dir(str) 即 ...
- windows命令行模式下无法打开python程序解决方法
今天刚开始学Python,首先编写一个简单地hello world程序,想在命令行模式运行,结果出现下面: 经过一番思考,发现用cd命令可以解决这件事,看下图: 这样就解决了.
- 区分命令行模式和Python交互模式
命令行模式 在Windows开始菜单选择"命令提示符",就进入到命令行模式,它的提示符类似C:\> Python交互模式 在命令行模式下敲命令python,就看到类似如下的一 ...
- centos6.5 python命令行模式左右建无法使用
我的虚拟机是centos6.5,自带python2.6:安装了Python2.7(安装了pip管理工具)后,在python2.7命令行模式下,左右键及退格键无法使用,基于以上情况,我进行了百度: 第一 ...
- 命令行模式和python交互模式
一.命令行模式 在Windows开始菜单选择“命令提示符”,就进入到命令行模式,它的提示符类似C:>:. 二.Python交互模式 在命令行模式下敲命令python,就看到类似如下的一堆文本输出 ...
- mysq在命令行模式下执行shell命令
mysql可以在命令行模式下执行shell命令 mysql> help For information about MySQL products and services, visit: htt ...
随机推荐
- MySQL 5.7.27 MGR 单主/多主+ ProxySQL
1 MySQL 5.7.27 MGR 多主环境 基础信息如下: centos 6.5/vbox 实例名 A B C IP 10.15.7.29 10.15.7.28 10.15.7.27 实例端口号 ...
- ubuntu分区建议总结
本文为转载别人的内容,结合了其他内容,进行分区的总结.其中主要是分区表格,对于ubuntu安装时,进行分区非常有用. 无论是安装Windows还是Linux操作系统,硬盘分区都是整个系统安装过程中最为 ...
- python基础--面向对象之多态
# 多态是指一类事物有多种行态, # 例如:动物有多种形态:人,狗,猫 # 他们有一些共同的特征:吃,喝,拉,撒 # 多态性是指在不考虑实例类型的情况下使用实例 # 对同一事物不同的类,对象有不同的响 ...
- XSS-反射型
前情提要:html的dom对象:document 如document.cookie / document.write() http://netsecurity.51cto.com/art/20131 ...
- vue父子组件相互传值的实例
当子组件需要向父组件传递数据时,就要用到自定义事件 子组件用 $emit()来触发事件,父组件用$on()来监昕子组件的事件 父组件也可以直接在子组件的自定义标签上使用 v-on 来监昕子组件触发的自 ...
- 记一则update 发生enq: TX - row lock contention 的处理方法
根据事后在虚拟机中复现客户现场发生的情况,做一次记录(简化部分过程,原理不变) 客户端1执行update语句 SQL> select * from test; ID NAME --------- ...
- SpringMvc 整合mybatis项目搭建
1.使用idea创建maven项目 2.在项目src目录下 添加java文件夹 并设置类型为sources,添加resource文件夹 设置为resources 4.修改pom文件 添加引用 < ...
- Javascript设计原则
Javascript设计原则 在面向对象的程序设计思想中, 我们能够遵循一些原则能够让我们开发代码时结构层次清晰, 更具说服力, 可谓是事半功倍. 做到这一点我们掌握一些程序设计原则是非常有利的, 如 ...
- 部署 laravel项目404错误
1.nginx 下部署出现404错误 (1)打开php.ini中的php_openssl.dll这个扩展: (2)修改nginx 下的站点目录配置文件(我的是配置在vhost.conf)为: loca ...
- Ehcache 入门详解 (转)
一:目录 EhCache 简介 Hello World 示例 Spring 整合 二: 简介 2.1.基本介绍 EhCache 是一个纯Java的进程内缓存框架,具有快速.精干等特点,是Hiberna ...