AI-Tensorflow-神经网络优化算法-梯度下降算法-学习率
记录内容来自《Tensorflow实战Google一书》及MOOC人工智能实践 http://www.icourse163.org/learn/PKU-1002536002?tid=1002700003
--梯度下降算法主要用于优化单个参数的取值, 反向传播算法给出了一个高效的方式在所有参数上使用梯度下降算法。
从而神经网络模型在训练数据的孙师函数尽可能小。
--反向传播算法是训练神经网络的核心算法, 它可以跟据定义好的损失函数优化神经网络中参数的取值, 从而使神经网络模型在训练数据集上的损失函数达到一个较小值。
假设损失函数如下:
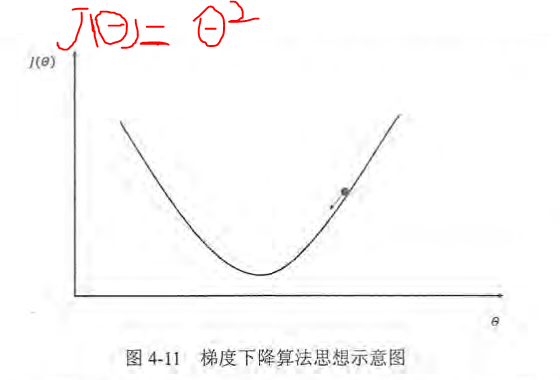
x轴表示参数取值, y轴表示损失函数的值。, 假设当前的参数和损失函数值的位置为图中小黑点的位置, 那么梯度下降算法将会将参数向x轴左侧移动, 从而使小圆点朝箭头的方向
移动。参数的梯度可以通过求骗到的方式计算。

通过以下是实例来解释梯度下降算法作用于损失函数的应用。
根据例子我们可以看出梯度下降算法可以顺利的使参数值朝着真实的值靠近。但是它并不能保证被优化的函数达到全局最优解。如下图实例所示:

为解决这一问题引进了随机梯度下降算法(stochastic gradient descent):这个算法优化的不是在全部训练数据上的损失函数, 而是在每一轮迭代中,随机优化
某一条训练数据上的损失函数。
神经网络的进一步优化
学习率的设置:
学习率表示了每次参数更新的幅度大小。学习率过大, 会导致待优化的参数在最小值附近波动, 不收敛;学习率过小, 会导致待优化的参数收敛缓慢。
在训练过程中, 参数的更新向着损失函数梯度下降的方向。

一个实例:来自大学MOOCTensorflow笔记
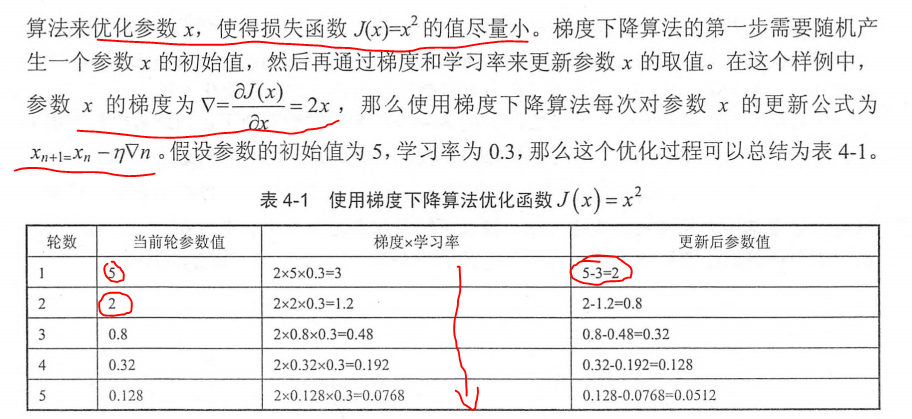
通过梯度下降算法优化损失函数 loss= (w+1)^2, w初始值设置为20, 学习率设置为0.2, 定义反向传播算法最后得到w的值为-1, loss为0, 符合函数曲线。
如果学习率设置为1 则会出现不收敛的情况

#coding:utf-8
#设损失函数 loss=(w+1)^2, 令w初值是常数5。反向传播就是求最优w,即求最小loss对应的w值
import tensorflow as tf
#定义待优化参数w初值赋5
w = tf.Variable(tf.constant(20, dtype=tf.float32))
#定义损失函数loss
loss = tf.square(w+1)
#定义反向传播方法
train_step = tf.train.GradientDescentOptimizer(0.2).minimize(loss)
#生成会话,训练40轮
with tf.Session() as sess:
init_op=tf.global_variables_initializer()
sess.run(init_op)
for i in range(40):
sess.run(train_step)
w_val = sess.run(w)
loss_val = sess.run(loss)
print "After %s steps: w is %f, loss is %f." % (i, w_val,loss_val)
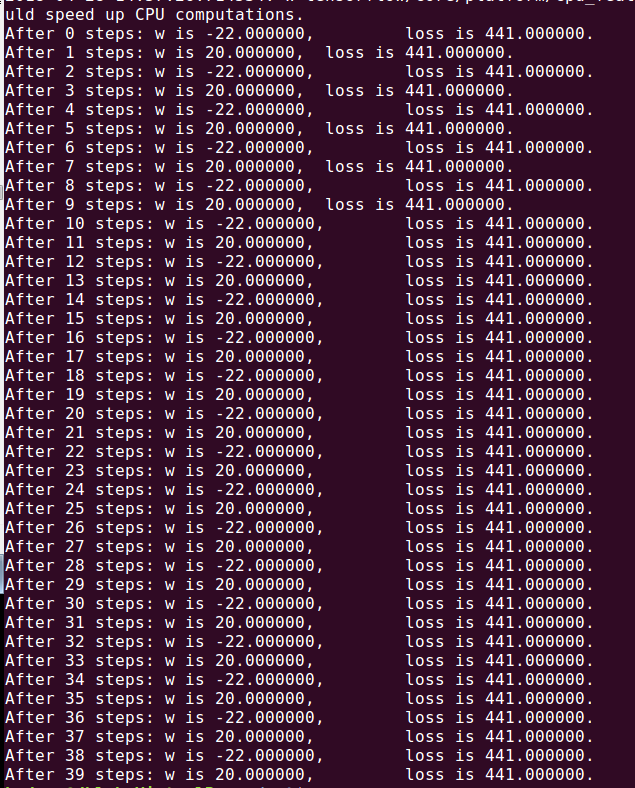
学习率为0.2运行结果如下, 较正常的结果:

学习率为1则会出现震荡不收敛的结果w的值在20和-22之间跳动,这就是不收敛:
为了解决设定学习率的问题, Tensorflow提供了一种更加灵活的学习率设置方法--指数衰减法
指数衰减学习率: 学习率随着训练轮数变化而动态更新,通过这个函数,可以先使用较大的学习率来快速得到一个比较优的解,然后随着迭代的接续逐步减小学习率,
是的模型在训练后期更加稳定。
学习率计算公式如下:

用 Tensorflow 的函数表示为:
global_step = tf.Variable(0, trainable=False)
learning_rate = tf.train.exponential_decay(
LEARNING_RATE_BASE,
global_step,
LEARNING_RATE_STEP, LEARNING_RATE_DECAY,
staircase=True/False)
其中, LEARNING_RATE_BASE 为学习率初始值, LEARNING_RATE_DECAY 为学习率衰减率,global_step 记
录了当前训练轮数,为不可训练型参数。学习率 learning_rate 更新频率为输入数据集总样本数除以每
次喂入样本数。若 staircase 设置为 True 时,表示 global_step/learning rate step 取整数,学习
率阶梯型衰减;若 staircase 设置为 false 时,学习率会是一条平滑下降的曲线。

一般来说初始学习率、衰减系数和衰减速度都是根据经验设置的。而且损失函数下降的速度和迭代结束之后总损失的大小没有必然的联系。
也就是说不能通过前几轮损失函数下降的速度来比较不同神经网络的效果。
#coding:utf-8
#设损失函数 loss=(w+1)^2, 令w初值是常数10。反向传播就是求最优w,即求最小loss对应的w值
#使用指数衰减的学习率,在迭代初期得到较高的下降速度,可以在较小的训练轮数下取得更有收敛度。
import tensorflow as tf LEARNING_RATE_BASE = 0.1 #最初学习率
LEARNING_RATE_DECAY = 0.99 #学习率衰减率
LEARNING_RATE_STEP = 1 #喂入多少轮BATCH_SIZE后,更新一次学习率,一般设为:总样本数/BATCH_SIZE #运行了几轮BATCH_SIZE的计数器,初值给0, 设为不被训练
global_step = tf.Variable(0, trainable=False)
#定义指数下降学习率
learning_rate = tf.train.exponential_decay(LEARNING_RATE_BASE, global_step, LEARNING_RATE_STEP, LEARNING_RATE_DECAY, staircase=True)
#定义待优化参数,初值给10
w = tf.Variable(tf.constant(10, dtype=tf.float32))
#定义损失函数loss
loss = tf.square(w+1)
#定义反向传播方法
train_step = tf.train.GradientDescentOptimizer(learning_rate).minimize(loss, global_step=global_step)
#生成会话,训练40轮
with tf.Session() as sess:
init_op=tf.global_variables_initializer()
sess.run(init_op)
for i in range(40):
sess.run(train_step)
learning_rate_val = sess.run(learning_rate)
global_step_val = sess.run(global_step)
w_val = sess.run(w)
loss_val = sess.run(loss)
print "After %s steps: global_step is %f, w is %f, learning rate is %f, loss is %f" % (i, global_step_val, w_val, learning_rate_val, loss_val)
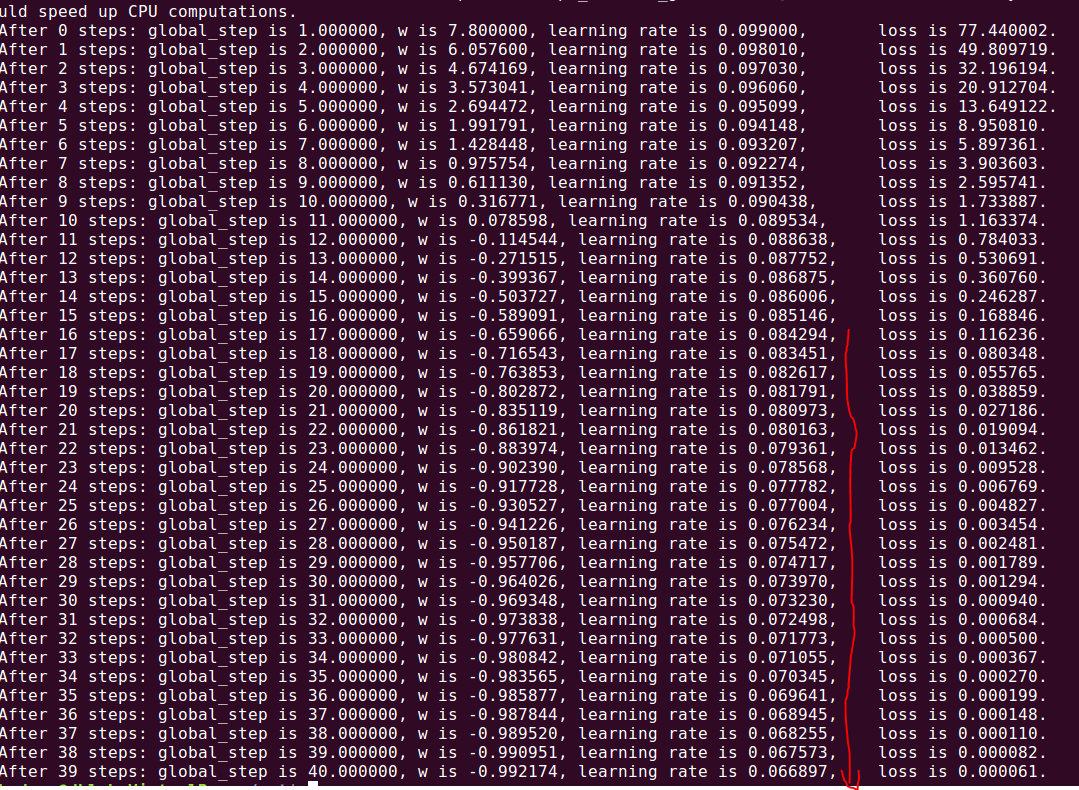
由结果看出学习率在不断的减小
AI-Tensorflow-神经网络优化算法-梯度下降算法-学习率的更多相关文章
- 机器学习之路: 深度学习 tensorflow 神经网络优化算法 学习率的设置
在神经网络中,广泛的使用反向传播和梯度下降算法调整神经网络中参数的取值. 梯度下降和学习率: 假设用 θ 来表示神经网络中的参数, J(θ) 表示在给定参数下训练数据集上损失函数的大小. 那么整个优化 ...
- 神经网络优化算法:梯度下降法、Momentum、RMSprop和Adam
最近回顾神经网络的知识,简单做一些整理,归档一下神经网络优化算法的知识.关于神经网络的优化,吴恩达的深度学习课程讲解得非常通俗易懂,有需要的可以去学习一下,本人只是对课程知识点做一个总结.吴恩达的深度 ...
- 神经网络优化算法:Dropout、梯度消失/爆炸、Adam优化算法,一篇就够了!
1. 训练误差和泛化误差 机器学习模型在训练数据集和测试数据集上的表现.如果你改变过实验中的模型结构或者超参数,你也许发现了:当模型在训练数据集上更准确时,它在测试数据集上却不⼀定更准确.这是为什么呢 ...
- 神经网络优化算法如何选择Adam,SGD
之前在tensorflow上和caffe上都折腾过CNN用来做视频处理,在学习tensorflow例子的时候代码里面给的优化方案默认很多情况下都是直接用的AdamOptimizer优化算法,如下: o ...
- 机器学习算法(优化)之一:梯度下降算法、随机梯度下降(应用于线性回归、Logistic回归等等)
本文介绍了机器学习中基本的优化算法—梯度下降算法和随机梯度下降算法,以及实际应用到线性回归.Logistic回归.矩阵分解推荐算法等ML中. 梯度下降算法基本公式 常见的符号说明和损失函数 X :所有 ...
- [2] TensorFlow 向前传播算法(forward-propagation)与反向传播算法(back-propagation)
TensorFlow Playground http://playground.tensorflow.org 帮助更好的理解,游乐场Playground可以实现可视化训练过程的工具 TensorFlo ...
- Tensorflow学习:(三)神经网络优化
一.完善常用概念和细节 1.神经元模型: 之前的神经元结构都采用线上的权重w直接乘以输入数据x,用数学表达式即,但这样的结构不够完善. 完善的结构需要加上偏置,并加上激励函数.用数学公式表示为:.其中 ...
- 梯度下降算法&线性回归算法
**机器学习的过程说白了就是让我们编写一个函数使得costfunction最小,并且此时的参数值就是最佳参数值. 定义 假设存在一个代价函数 fun:\(J\left(\theta_{0}, \the ...
- tensorflow随机梯度下降算法使用滑动平均模型
在采用随机梯度下降算法训练神经网络时,使用滑动平均模型可以提高最终模型在测试集数据上的表现.在Tensflow中提供了tf.train.ExponentialMovingAverage来实现滑动平均模 ...
随机推荐
- BitMap位图
BitMap位图算法https://blog.csdn.net/varyall/article/details/79662029 常见面试题 题1:在2.5亿个整数找出不重复的整数,内存不足以容纳着2 ...
- phpstorm 生产php pojo类
一. 修改Generate POJO.groovy文件 改为 import com.intellij.database.model.DasTable import com.intellij.datab ...
- hdu 6143: Killer Names (2017 多校第八场 1011)
题目链接 题意,有m种颜色,给2n个位置染色,使左边n个和右边n个没有共同的颜色. 可以先递推求出恰用i种颜色染n个位置的方案数,然后枚举两边的染色数就可以了,代码很简单. #include<b ...
- webService接口的py文件打包成exe
(一)webService接口的py文件打包成exe,在python3.5版本.pyInstaller3.2版本.pywin32-219.win-amd64-py3.5版本打包时报错,原因可能是pyi ...
- day15—jQuery UI之widgets插件
转行学开发,代码100天——2018-03-31 今天学习了jQuery UI的widgets插件,主要包括accordion插件 accordion插件 该插件表示折叠面板效果,点击头部展开/折叠被 ...
- 16/7/11_PHP-日期和时间
取得当前的Unix时间戳 UNIX 时间戳(英文叫做:timestamp)是 PHP 中关于时间与日期的一个很重要的概念,它表示从 1970年1月1日 00:00:00 到当前时间的秒数之和. PHP ...
- Oracle系列:触发器、作业、序列、连接
.Net程序员学用Oracle系列(8):触发器.作业.序列.连接 1.触发器 2.作业 2.1.作业调度功能和应用 2.2.通过 DBMS_JOB 来调度作业 3.序列 3.1.创建序列 3.2 ...
- 不同vlan之间相互通信
不同VLAN之间相互通信的两种方式 (单臂路由.三层交换) 试验目的: 1.通过单臂路由实现不同VLAN之间的通信 2.通过三层交换路由功能实现不同VLAN之间的通信 网络拓扑图: 1.单臂路由实 ...
- .NET简单三层的理解
1.UI 表示层 :就是我们看到的网站前台2.BLL 业务逻辑层:很简单 也很重要 处理逻辑问题 简单程序看不出啥效果3.DAL 数据访问层: 写数据连接和执行的SQL语句4.MODEL 模型层:封装 ...
- 什么是php扩展
PHP扩展英文为PHP Extension and Application Repository,简称pear(下面都以pear简称),中文全称为PHP扩展与应用库.是为了创建一个类似于Perl CP ...