Flink sql 之AsyncIO与LookupJoin的几个疑问 (源码分析)
本文源码基于flink 1.14
被同事问到几个关于AsyncIO和lookUp维表的问题所以翻了下源码,从源码的角度解惑这几个问题
对于AsyncIO不了解的可以看看之前写的这篇 《Flink中异步AsyncIO的实现 (源码分析)》
问题一:AsyncIO 有(排序 / 非排序) 模式,非排序模式数据会乱序,那水印waterMarker会乱序吗 ???
不想看源码的先直接给出答案
:不会乱序,接收到水印数据后非排序模式会,直接往下游发送waterMarker
问题二:LookUp维表join分为同步和Async, 上面异步非排序,数据会乱序水印不会,那sql的维表异步join数据会乱序吗 ???
:不会乱序,源码中默认都是AsyncIO的排序(Ordered)模式
ok上源码
问题一:AsyncIO水印会乱序吗?
来看一下异步io对应的StreamOperator的源码 org.apache.flink.streaming.api.operators.async.AsyncWaitOperator
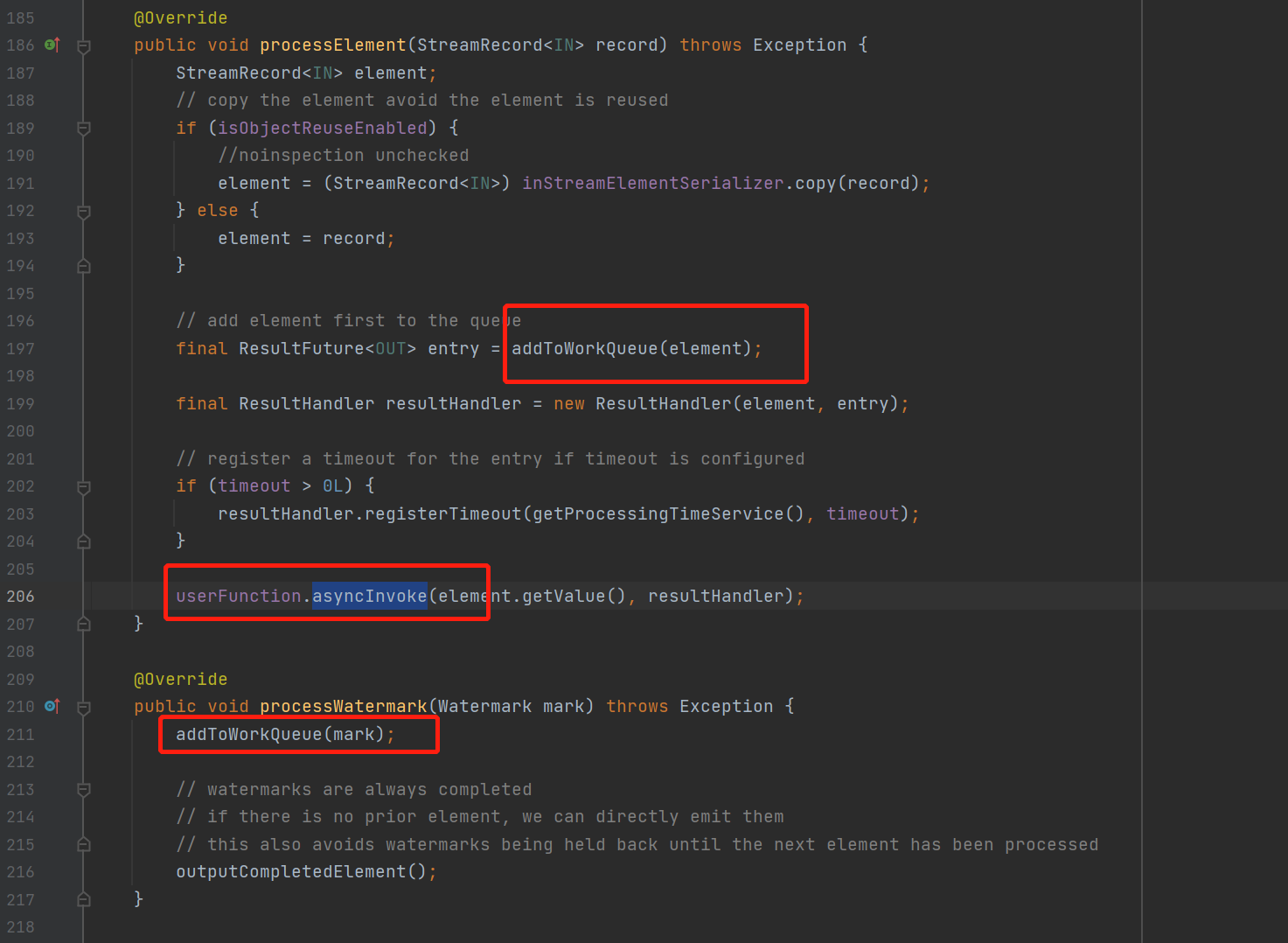
异步io接收到数据以后,加入到queue里面,然后调用用户写的UserFunction
异步io接收到水印以后,同样加入到queue里面
那继续看addToWorkQueue方法接收到水印以后

加入具体的queue
继续,这里只看非排序的unordered

也是一样直接加addWtaermark()
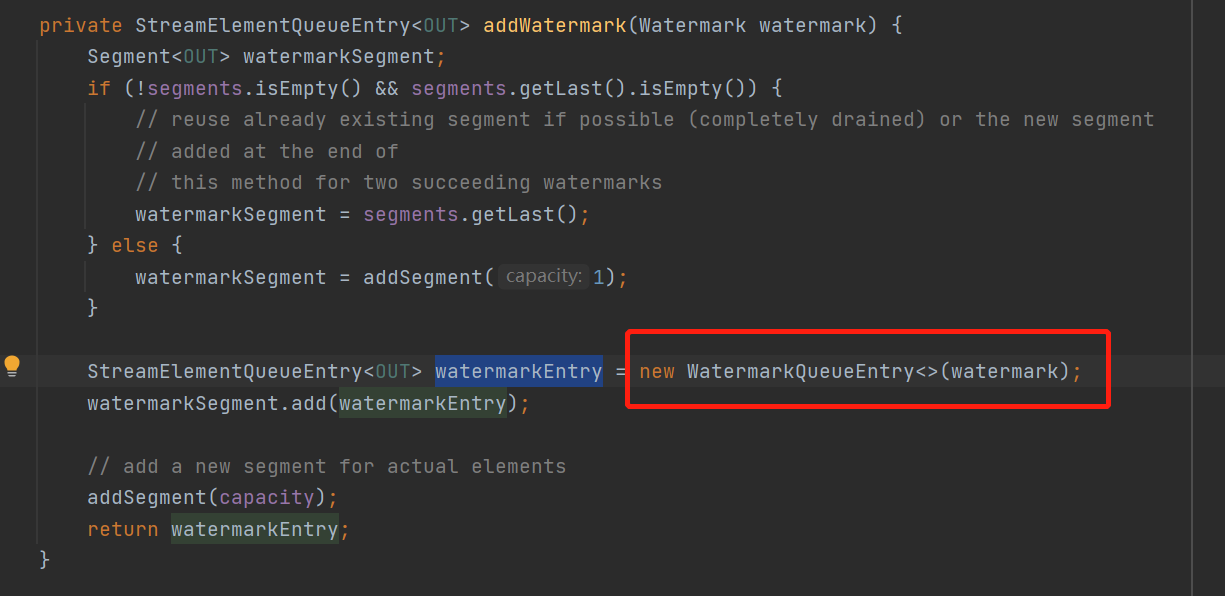
将水印包装成一个WatermarkQueueEntry对象直接放queue
ok那来看下这个watermarkQueueEntry类

可以看到当水印进入queue以后直接就是已完成的了,就可以直接往下游发送,管你其他异步处理的数据完成没完成,水印已经往下发了
问题二:LookUp维表异步join会导致数据乱序吗?
看下关于lookup的calcite的对应规则

调用链不看了,有点长来看最后生成的,execNode物理的relNode执行节点StreamExecLookupJoin
来看下它抽象类 CommonExecLookupJoin的translateToPlanInternal方法
最后走到 createAsyncLookupJoin 来看下如何生成AsyncIO的function的
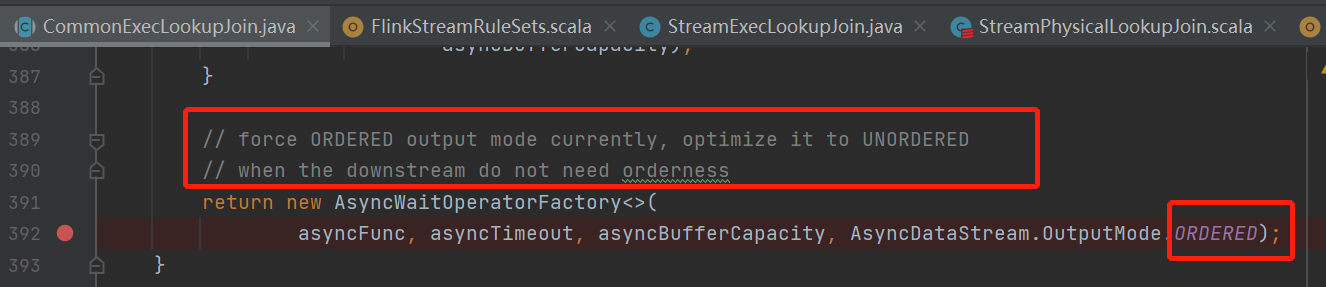
ok 用的ordered模式的异步io,维表关联的数据尽管是异步去join的,但是往下游发的时候还是按顺序的
不会乱序
Flink sql 之AsyncIO与LookupJoin的几个疑问 (源码分析)的更多相关文章
- [源码分析] 带你梳理 Flink SQL / Table API内部执行流程
[源码分析] 带你梳理 Flink SQL / Table API内部执行流程 目录 [源码分析] 带你梳理 Flink SQL / Table API内部执行流程 0x00 摘要 0x01 Apac ...
- [源码分析]从"UDF不应有状态" 切入来剖析Flink SQL代码生成 (修订版)
[源码分析]从"UDF不应有状态" 切入来剖析Flink SQL代码生成 (修订版) 目录 [源码分析]从"UDF不应有状态" 切入来剖析Flink SQL代码 ...
- MyCat源码分析系列之——SQL下发
更多MyCat源码分析,请戳MyCat源码分析系列 SQL下发 SQL下发指的是MyCat将解析并改造完成的SQL语句依次发送至相应的MySQL节点(datanode)的过程,该执行过程由NonBlo ...
- MyBatis源码分析-SQL语句执行的完整流程
MyBatis 是支持定制化 SQL.存储过程以及高级映射的优秀的持久层框架.MyBatis 避免了几乎所有的 JDBC 代码和手动设置参数以及获取结果集.MyBatis 可以对配置和原生Map使用简 ...
- Flink源码分析 - 源码构建
原文地址:https://mp.weixin.qq.com/s?__biz=MzU2Njg5Nzk0NQ==&mid=2247483692&idx=1&sn=18cddc1ee ...
- MyBatis 源码分析 - SQL 的执行过程
* 本文速览 本篇文章较为详细的介绍了 MyBatis 执行 SQL 的过程.该过程本身比较复杂,牵涉到的技术点比较多.包括但不限于 Mapper 接口代理类的生成.接口方法的解析.SQL 语句的解析 ...
- 第十一篇:Spark SQL 源码分析之 External DataSource外部数据源
上周Spark1.2刚发布,周末在家没事,把这个特性给了解一下,顺便分析下源码,看一看这个特性是如何设计及实现的. /** Spark SQL源码分析系列文章*/ (Ps: External Data ...
- 第十篇:Spark SQL 源码分析之 In-Memory Columnar Storage源码分析之 query
/** Spark SQL源码分析系列文章*/ 前面讲到了Spark SQL In-Memory Columnar Storage的存储结构是基于列存储的. 那么基于以上存储结构,我们查询cache在 ...
- 第九篇:Spark SQL 源码分析之 In-Memory Columnar Storage源码分析之 cache table
/** Spark SQL源码分析系列文章*/ Spark SQL 可以将数据缓存到内存中,我们可以见到的通过调用cache table tableName即可将一张表缓存到内存中,来极大的提高查询效 ...
随机推荐
- cmake入门:01 构建一个简单的可执行程序
一.目录结构 CMakeLists.txt:cmake 工程入口文件,包含当前目录下的工程组织信息.cmake 指令根据此文件生成相应的 MakeFile 文件. Hello.c: 源代码文件 bui ...
- YbtOJ#943-平方约数【莫比乌斯反演,平衡规划】
正题 题目链接:http://www.ybtoj.com.cn/contest/122/problem/3 题目大意 \(S(i)\)表示\(i\)的约数个数,\(Q\)次询问给出\(n,m\)求 \ ...
- WPF实现统计图(饼图仿LiveCharts)
WPF开发者QQ群: 340500857 | 微信群 -> 进入公众号主页 加入组织 每日一笑 下班和实习生一起回家,公交站等车,一乞丐把碗推向实习生乞讨.这时,实习生不慌不忙的说了句:&qu ...
- Excel备忘录
1. 导入文本文件(.txt) 2. 排序 3. 批量填充空白 选定区域,Ctrl+G,定位,空值. 输入内容,Ctrl+Enter. 4. 清除无法修改的背景色. 5. 身份证号 数字精度为15位, ...
- java课堂测试3第一部分(未完善)
package test3;import java.util.*; public class Grade2 { static String[][] mis=new String[500][4]; // ...
- 洛谷4208 JSOI2008最小生成树计数(矩阵树定理+高斯消元)
qwq 这个题目真的是很好的一个题啊 qwq 其实一开始想这个题,肯定是无从下手. 首先,我们会发现,对于无向图的一个最小生成树来说,只有当存在一些边与内部的某些边权值相同的时候且能等效替代的时候,才 ...
- 一个简单的Java应用程序
目录 一个简单的Java应用程序 首次运行结果 程序示例 运行结果 修改大小写之后的运行结果 程序示例 运行结果 关键字public 关键字class 类名及其命名规则 类名必须以字母开头 不能使用J ...
- IEEE754浮点数的转换
将十进制数转换为单精度浮点数 如何将十进制数转换为单精度浮点数参考 首先要知道 IEEE浮点标准:V=(-1)^s * M * 2^E 1.符号(sign)s决定这个数是负数(s=1)还是正数,0(s ...
- 微软Windows11安卓子系统已支持运行APK 应用(附手把手详细安装攻略)怎么安装安卓/如何安装安卓应用/支持多窗口多任务
10 月 21 日消息,微软博客宣称,Windows 11 上 安卓子系统运行 Android 应用程序的第一个预览版现已提供给美国 Beta 频道的 Windows 内部人员.但现在通过教程 ...
- 【UE4 C++】编程子系统 Subsystem
概述 定义 Subsystems 是一套可以定义.自动实例化和释放的类的框架.可以将其理解为 GamePlay 级别的 Component 不支持网络赋值 4.22开始引入,4.24完善.(可以移植源 ...