共享内存 & Actor并发模型哪个更快?
HI,前几天被.NET圈纪检委@懒得勤快问到
共享内存和Actor并发模型哪个速度更快。

前文传送门:
说实在,我内心10w头羊驼跑过......
先说结论
- 首先两者对于并发的风格模型不一样。
共享内存利用多核CPU的优势,使用强一致的锁机制控制并发, 各种锁交织,稍不注意可能出现死锁,更适合熟手。
Actor模型易于控制和管理,以消息触发,流水线挨个处理, 思路清晰。
- 真要说性能,
求100000 以内的素数的个数]场景&我电脑8c 16g的配置, 我根据这个示例拍脑袋对比。。。。。
2.1 理论上如果以默认的Actor并发模型来做这个事情,Actor的性能是逊于共享内存模型的;
2.2 上文中我对于Actor做了多线程优化,性能慢慢追上来了。
默认Actor模型
计算[100_000内素数的个数], 分为两步:
(1) 迭代判断当前数字是不是素数
(2) 如果是素数,执行sum++
共享内存完成以上两步, 均能充分利用CPU多核心。
Actor模型:与TPL中的原语不同,TPL datflow中的所有块默认是单线程的,这就意味着完成以上两步的TransfromBlock和ActionBlock都是以一个线程挨个处理消息数据(这也是Dataflow的设计初衷,形成清晰单纯的流水线)。
猜测起来也是共享内存相比默认的Actor模型更具优势。
使用NUnit做单元测试,数据量从小到大: 10_000,50_000,100_000,200_000,300_000,500_000
using NUnit.Framework;
using System;
using System.Threading.Tasks;
using System.Collections.Generic;
using System.Threading;
using System.Threading.Tasks.Dataflow;
namespace TestProject2
{
public class Tests
{
[TestCase(10_000)]
[TestCase(50_000)]
[TestCase(100_000)]
[TestCase(200_000)]
[TestCase(300_000)]
[TestCase(500_000)]
public void ShareMemory(int num)
{
var sum = 0;
Parallel.For(1, num + 1, (x, state) =>
{
var f = true;
if (x == 1)
f = false;
for (int i = 2; i <= x / 2; i++)
{
if (x % i == 0) // 被[2,x/2]任一数字整除,就不是质数
f = false;
}
if (f == true)
{
Interlocked.Increment(ref sum);// 共享了sum对象,“++”就是调用sum对象的成员方法
}
});
Console.WriteLine($"1-{num}内质数的个数是{sum}");
}
[TestCase(10_000)]
[TestCase(50_000)]
[TestCase(100_000)]
[TestCase(200_000)]
[TestCase(300_000)]
[TestCase(500_000)]
public async Task Actor(int num)
{
var linkOptions = new DataflowLinkOptions { PropagateCompletion = true };
var bufferBlock = new BufferBlock<int>();
var transfromBlock = new TransformBlock<int, bool>(x =>
{
var f = true;
if (x == 1)
f = false;
for (int i = 2; i <= x / 2; i++)
{
if (x % i == 0) // 被[2,x/2]任一数字整除,就不是质数
f = false;
}
return f;
}, new ExecutionDataflowBlockOptions { EnsureOrdered = false });
var sum = 0;
var actionBlock = new ActionBlock<bool>(x =>
{
if (x == true)
sum++;
}, new ExecutionDataflowBlockOptions { EnsureOrdered = false });
transfromBlock.LinkTo(actionBlock, linkOptions);
// 准备从pipeline头部开始投递
try
{
var list = new List<int> { };
for (int i = 1; i <= num; i++)
{
var b = await transfromBlock.SendAsync(i);
if (b == false)
{
list.Add(i);
}
}
if (list.Count > 0)
{
Console.WriteLine($"md,num post failure,num:{list.Count},post again");
// 再投一次
foreach (var item in list)
{
transfromBlock.Post(item);
}
}
transfromBlock.Complete(); // 通知头部,不再投递了; 会将信息传递到下游。
actionBlock.Completion.Wait(); // 等待尾部执行完
Console.WriteLine($"1-{num} Prime number include {sum}");
}
catch (Exception ex)
{
Console.WriteLine($"1-{num} cause exception.",ex);
}
}
}
}
测试结果如下:
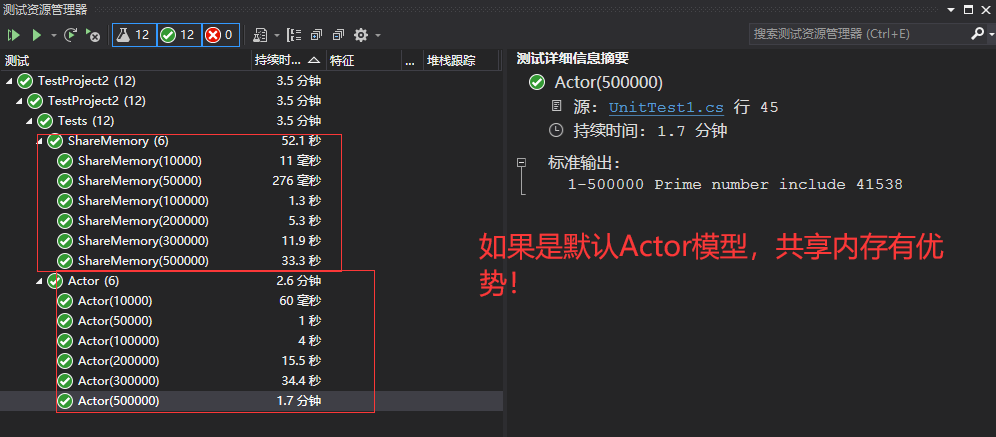
测试结果印证我说的结论2.1
优化后的Actor模型
那后面我对Actor做了什么优化呢?能产生下图的结论。

请重新回看《三分钟掌握》 TransformBlock块的细节:
var transfromBlock = new TransformBlock<int, bool>(x =>
{
var f = true;
if (x == 1)
f = false;
for (int i = 2; i <= x / 2; i++)
{
if (x % i == 0) // 被[2,x/2]任一数字整除,就不是质数
f = false;
}
return f;
}, new ExecutionDataflowBlockOptions { MaxDegreeOfParallelism=50, EnsureOrdered = false });
上面说到默认的Actor是单线程处理输入的消息, 此时我们设置了MaxDegreeOfParallelism参数,参数能在Actor中开启多线程并发执行,但是这里面就不能有共享变量(否则你又得加锁),恰好我们完成 (1) 迭代判断当前数字是不是素数这一步并不依赖共享对象,所以这一步性能与共享内存模型基本没差别。
那为什么总体性能慢慢超过共享内存?
这是因为执行第二步(2) 如果是素数,执行sum++, 共享内存要加解锁,线程上下文切换,而Actor单线程挨个处理, 总体就略胜共享内存模型了。
这里再次强调,Actor模型执行第二步
(2) 如果是素数,执行sum++,不可开启MaxDegreeOfParallelism,因为依赖了共享变量sum

结束语
请大家仔细对比结论和上图,脱离场景和硬件环境谈性能就是耍流氓,理解不同并发模型的风格和能力是关键,本文仅针对这个示例拍脑袋对比。
实际要针对场景和未来的拓展性、可维护性、可操作性做技术选型 。
That's All, 感谢.NET圈纪检委@懒得勤快促使我重温了单元测试的写法 & 深度分析Actor模型。
共享内存 & Actor并发模型哪个更快?的更多相关文章
- 三分钟掌握共享内存 & Actor并发模型
吃点好的,很有必要.今天介绍常见的两种并发模型: 共享内存&Actor 共享内存 面向对象编程中,万物都是对象,数据+行为=对象: 多核时代,可并行多个线程,但是受限于资源对象,线程之间存在对 ...
- Java并发模型(一)
学习资料来自http://ifeve.com/java-concurrency-thread-directory/ 一.多线程 进程和线程的区别: 一个程序运行至少一个进程,一个进程至少包含一个线程. ...
- 【CUDA 基础】5.1 CUDA共享内存概述
title: [CUDA 基础]5.1 CUDA共享内存概述 categories: - CUDA - Freshman tags: - CUDA共享内存模型 - CUDA共享内存分配 - CUDA共 ...
- TensorRT 3:更快的TensorFlow推理和Volta支持
TensorRT 3:更快的TensorFlow推理和Volta支持 TensorRT 3: Faster TensorFlow Inference and Volta Support 英伟达Tens ...
- Linux系统编程之命名管道与共享内存
在上一篇博客中,我们已经熟悉并使用了匿名管道,这篇博客我们将讲述进程间通信另外两种常见方式--命名管道与共享内存. 1.命名管道 管道是使用文件的方式,进行进程之间的通信.因此对于管道的操作,实际上还 ...
- SharePoint 2010中使用SPListItemCollectionPosition更快的结果
转:http://www.16kan.com/article/detail/318657.html Introduction介绍 In this article we will explore the ...
- UnixIPC之共享内存
Unix-IPC之共享内存 一,共享内存的概念 共享内存通信技术是一种最快的可用IPC形式,它是针对其他通信机制运行效率低和设计的新型通信技术(其他的如:信号量,管道,套接字等).这种通信技术往往与其 ...
- 利用共享内存实现比NCCL更快的集合通信
作者:曹彬 | 旷视 MegEngine 架构师 简介 从 2080Ti 这一代显卡开始,所有的民用游戏卡都取消了 P2P copy,导致训练速度显著的变慢.针对这种情况下的单机多卡训练,MegEng ...
- Akka系列(四):Akka中的共享内存模型
前言...... 通过前几篇的学习,相信大家对Akka应该有所了解了,都说解决并发哪家强,JVM上面找Akka,那么Akka到底在解决并发问题上帮我们做了什么呢? 共享内存 众所周知,在处理并发问题上 ...
随机推荐
- Java IO学习笔记七:多路复用从单线程到多线程
作者:Grey 原文地址:Java IO学习笔记七:多路复用从单线程到多线程 在前面提到的多路复用的服务端代码中, 我们在处理读数据的同时,也处理了写事件: public void readHandl ...
- HDFS 07 - HDFS 性能调优之 合并小文件
目录 1 - 为什么要合并小文件 2 - 合并本地的小文件,上传到 HDFS 3 - 合并 HDFS 的小文件,下载到本地 4 - 通过 Java API 实现文件合并和上传 版权声明 1 - 为什么 ...
- 管理后台Vue
管理后台 遇到的问题 搭建 基于vue 3.0 Vue CLI 4.x Ant Design Vue 2.0 搭建后台管理系统 Ant Design Vue 2.0 npm i --save ant- ...
- JAVA设计模式(6:单例模式详解)
单例模式作为一种创建型模式,在日常开发中用处极广,我们先来看一一段代码: // 构造函数 protected Calendar(TimeZone var1, Locale var2) { this.l ...
- vue项目使用Echarts制作项目工期甘特图
目录 1,前言 2,布局和数据部分 3,制作甘特图 1,前言 项目迭代过程中,碰上一个需求,要求用甘特图的方式显示项目的工期进度,开完会我赶紧搜索一下甘特图是啥东东,大概了解之后,做出了如下样式 Ec ...
- Java并发之ReentrantLock源码解析(二)
在了解如何加锁时候,我们再来了解如何解锁.可重入互斥锁ReentrantLock的解锁方法unlock()并不区分是公平锁还是非公平锁,Sync类并没有实现release(int arg)方法,这里会 ...
- 玩转STM32MP157- 在应用层中使用 fbtft
fbtft使用的是framebuffer框架,这种框架将显示设备抽象为帧缓冲区,对framebuffer设备(/dev/fbx(0.1.2..))进行相关操作可以反应到LCD上. 现在尝试下在用户空间 ...
- centos7安装kubernetes1.18.5
一.设置hosts 修改主机名 [root@localhost kubernetes]# hostnamectl set-hostname master69 四台服务器安装kebernetes,一个m ...
- 关于 Index '8' specified is out of bounds.
报类似这样的错误暂时我只发现了两个原因: 1, 数组超出了界线,这个自己多多注意,加判断,在循环的时候看看是不是有结束条件 2, 你需要提交的网页不存在.有可能是因为你没有这个文件.可能是你的文件名错 ...
- html的题库(含答案)
该题库仅供巩固自身HTML知识 Tip:<为< 单选题 1.下面标记中,用来显示段落的标记是( D ). A.<h1> B.<br /> C.<img / ...