共享内存 & Actor并发模型哪个更快?
HI,前几天被.NET圈纪检委@懒得勤快问到
共享内存和Actor并发模型哪个速度更快。

前文传送门:
说实在,我内心10w头羊驼跑过......
先说结论
- 首先两者对于并发的风格模型不一样。
共享内存利用多核CPU的优势,使用强一致的锁机制控制并发, 各种锁交织,稍不注意可能出现死锁,更适合熟手。
Actor模型易于控制和管理,以消息触发,流水线挨个处理, 思路清晰。
- 真要说性能,
求100000 以内的素数的个数]场景&我电脑8c 16g的配置, 我根据这个示例拍脑袋对比。。。。。
2.1 理论上如果以默认的Actor并发模型来做这个事情,Actor的性能是逊于共享内存模型的;
2.2 上文中我对于Actor做了多线程优化,性能慢慢追上来了。
默认Actor模型
计算[100_000内素数的个数], 分为两步:
(1) 迭代判断当前数字是不是素数
(2) 如果是素数,执行sum++
共享内存完成以上两步, 均能充分利用CPU多核心。
Actor模型:与TPL中的原语不同,TPL datflow中的所有块默认是单线程的,这就意味着完成以上两步的TransfromBlock和ActionBlock都是以一个线程挨个处理消息数据(这也是Dataflow的设计初衷,形成清晰单纯的流水线)。
猜测起来也是共享内存相比默认的Actor模型更具优势。
使用NUnit做单元测试,数据量从小到大: 10_000,50_000,100_000,200_000,300_000,500_000
using NUnit.Framework;
using System;
using System.Threading.Tasks;
using System.Collections.Generic;
using System.Threading;
using System.Threading.Tasks.Dataflow;
namespace TestProject2
{
public class Tests
{
[TestCase(10_000)]
[TestCase(50_000)]
[TestCase(100_000)]
[TestCase(200_000)]
[TestCase(300_000)]
[TestCase(500_000)]
public void ShareMemory(int num)
{
var sum = 0;
Parallel.For(1, num + 1, (x, state) =>
{
var f = true;
if (x == 1)
f = false;
for (int i = 2; i <= x / 2; i++)
{
if (x % i == 0) // 被[2,x/2]任一数字整除,就不是质数
f = false;
}
if (f == true)
{
Interlocked.Increment(ref sum);// 共享了sum对象,“++”就是调用sum对象的成员方法
}
});
Console.WriteLine($"1-{num}内质数的个数是{sum}");
}
[TestCase(10_000)]
[TestCase(50_000)]
[TestCase(100_000)]
[TestCase(200_000)]
[TestCase(300_000)]
[TestCase(500_000)]
public async Task Actor(int num)
{
var linkOptions = new DataflowLinkOptions { PropagateCompletion = true };
var bufferBlock = new BufferBlock<int>();
var transfromBlock = new TransformBlock<int, bool>(x =>
{
var f = true;
if (x == 1)
f = false;
for (int i = 2; i <= x / 2; i++)
{
if (x % i == 0) // 被[2,x/2]任一数字整除,就不是质数
f = false;
}
return f;
}, new ExecutionDataflowBlockOptions { EnsureOrdered = false });
var sum = 0;
var actionBlock = new ActionBlock<bool>(x =>
{
if (x == true)
sum++;
}, new ExecutionDataflowBlockOptions { EnsureOrdered = false });
transfromBlock.LinkTo(actionBlock, linkOptions);
// 准备从pipeline头部开始投递
try
{
var list = new List<int> { };
for (int i = 1; i <= num; i++)
{
var b = await transfromBlock.SendAsync(i);
if (b == false)
{
list.Add(i);
}
}
if (list.Count > 0)
{
Console.WriteLine($"md,num post failure,num:{list.Count},post again");
// 再投一次
foreach (var item in list)
{
transfromBlock.Post(item);
}
}
transfromBlock.Complete(); // 通知头部,不再投递了; 会将信息传递到下游。
actionBlock.Completion.Wait(); // 等待尾部执行完
Console.WriteLine($"1-{num} Prime number include {sum}");
}
catch (Exception ex)
{
Console.WriteLine($"1-{num} cause exception.",ex);
}
}
}
}
测试结果如下:
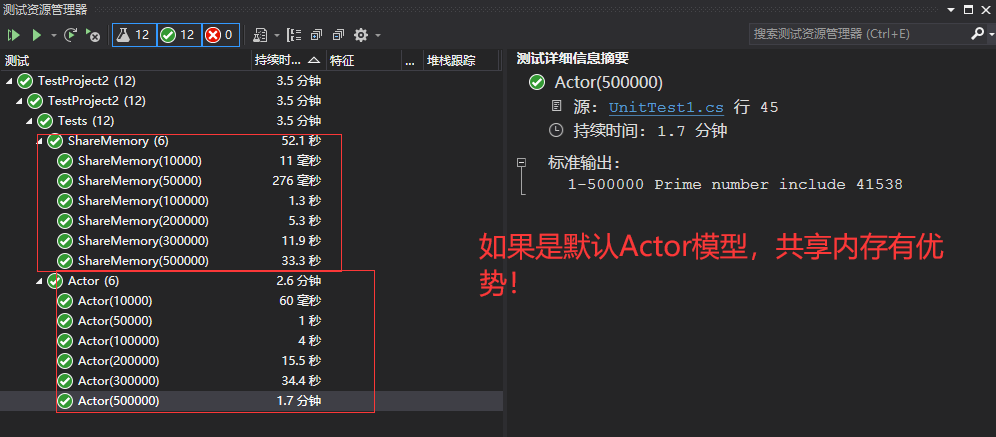
测试结果印证我说的结论2.1
优化后的Actor模型
那后面我对Actor做了什么优化呢?能产生下图的结论。

请重新回看《三分钟掌握》 TransformBlock块的细节:
var transfromBlock = new TransformBlock<int, bool>(x =>
{
var f = true;
if (x == 1)
f = false;
for (int i = 2; i <= x / 2; i++)
{
if (x % i == 0) // 被[2,x/2]任一数字整除,就不是质数
f = false;
}
return f;
}, new ExecutionDataflowBlockOptions { MaxDegreeOfParallelism=50, EnsureOrdered = false });
上面说到默认的Actor是单线程处理输入的消息, 此时我们设置了MaxDegreeOfParallelism参数,参数能在Actor中开启多线程并发执行,但是这里面就不能有共享变量(否则你又得加锁),恰好我们完成 (1) 迭代判断当前数字是不是素数这一步并不依赖共享对象,所以这一步性能与共享内存模型基本没差别。
那为什么总体性能慢慢超过共享内存?
这是因为执行第二步(2) 如果是素数,执行sum++, 共享内存要加解锁,线程上下文切换,而Actor单线程挨个处理, 总体就略胜共享内存模型了。
这里再次强调,Actor模型执行第二步
(2) 如果是素数,执行sum++,不可开启MaxDegreeOfParallelism,因为依赖了共享变量sum

结束语
请大家仔细对比结论和上图,脱离场景和硬件环境谈性能就是耍流氓,理解不同并发模型的风格和能力是关键,本文仅针对这个示例拍脑袋对比。
实际要针对场景和未来的拓展性、可维护性、可操作性做技术选型 。
That's All, 感谢.NET圈纪检委@懒得勤快促使我重温了单元测试的写法 & 深度分析Actor模型。
共享内存 & Actor并发模型哪个更快?的更多相关文章
- 三分钟掌握共享内存 & Actor并发模型
吃点好的,很有必要.今天介绍常见的两种并发模型: 共享内存&Actor 共享内存 面向对象编程中,万物都是对象,数据+行为=对象: 多核时代,可并行多个线程,但是受限于资源对象,线程之间存在对 ...
- Java并发模型(一)
学习资料来自http://ifeve.com/java-concurrency-thread-directory/ 一.多线程 进程和线程的区别: 一个程序运行至少一个进程,一个进程至少包含一个线程. ...
- 【CUDA 基础】5.1 CUDA共享内存概述
title: [CUDA 基础]5.1 CUDA共享内存概述 categories: - CUDA - Freshman tags: - CUDA共享内存模型 - CUDA共享内存分配 - CUDA共 ...
- TensorRT 3:更快的TensorFlow推理和Volta支持
TensorRT 3:更快的TensorFlow推理和Volta支持 TensorRT 3: Faster TensorFlow Inference and Volta Support 英伟达Tens ...
- Linux系统编程之命名管道与共享内存
在上一篇博客中,我们已经熟悉并使用了匿名管道,这篇博客我们将讲述进程间通信另外两种常见方式--命名管道与共享内存. 1.命名管道 管道是使用文件的方式,进行进程之间的通信.因此对于管道的操作,实际上还 ...
- SharePoint 2010中使用SPListItemCollectionPosition更快的结果
转:http://www.16kan.com/article/detail/318657.html Introduction介绍 In this article we will explore the ...
- UnixIPC之共享内存
Unix-IPC之共享内存 一,共享内存的概念 共享内存通信技术是一种最快的可用IPC形式,它是针对其他通信机制运行效率低和设计的新型通信技术(其他的如:信号量,管道,套接字等).这种通信技术往往与其 ...
- 利用共享内存实现比NCCL更快的集合通信
作者:曹彬 | 旷视 MegEngine 架构师 简介 从 2080Ti 这一代显卡开始,所有的民用游戏卡都取消了 P2P copy,导致训练速度显著的变慢.针对这种情况下的单机多卡训练,MegEng ...
- Akka系列(四):Akka中的共享内存模型
前言...... 通过前几篇的学习,相信大家对Akka应该有所了解了,都说解决并发哪家强,JVM上面找Akka,那么Akka到底在解决并发问题上帮我们做了什么呢? 共享内存 众所周知,在处理并发问题上 ...
随机推荐
- .NET Core/.NET5/.NET6 开源项目汇总1:常用必备组件
系列目录 [已更新最新开发文章,点击查看详细] 开源项目是众多组织与个人分享的组件或项目,作者付出的心血我们是无法体会的,所以首先大家要心存感激.尊重.请严格遵守每个项目的开源协议后再使用.尊 ...
- ubuntu初识
简单的Linux系统理解 Ubuntu ctrl+alt 可以令虚拟机释放鼠标,回到主系统中. 如果ubuntu有问题,如何重装? -------直接删除目录.虚拟机内的操作不会影响到宿主机. 1.挂 ...
- 【模板】 RMQ求区间最值
RMQ RMQ简单来说就是求区间的最大值(最小值) 核心算法:动态规划 RMQ(以下以求最大值为例) F[i,j]表示 从 i 开始 到i+2j -1这个区间中的最大值 状态转移方程 F[i,j]=m ...
- SVN分支的创建与使用
首先放出右键菜单点击Branch/tag... 所示位置输入想新建分支的路径 然后ok就完成了 之后就是切换分支上传代码了 点击Switch... 在里面就可以切换分支了To path
- Local dimming algorithm in matlab
LED局部背光算法的matlab仿真 最近公司接了华星光电(TCL)的一个项目LCD-BackLight-Local-Diming-Algorithm-IP ,由于没有实际的硬件,只能根据客户给的论文 ...
- 关于Kubernetes(简称K8S)的开启及基本使用,基于Docker Desktop & WSL2
背景介绍 Kubernetes(简称k8s)已成为目前业界容器编排的事实标准,其搭配Docker可建立非常高效便捷的高可扩展.高可用应用服务架构. Kubernetes的名字来自希腊语,意思是&quo ...
- [Usaco2018 Dec]Teamwork 题解
题目描述 题目描述 在Farmer John最喜欢的节日里,他想要给他的朋友们赠送一些礼物.由于他并不擅长包装礼物,他想要获得他的 奶牛们的帮助.你可能能够想到,奶牛们本身也不是很擅长包装礼物,而Fa ...
- activiti版本下载
activiti工作流历史各个版本下载地址修改版本号后在浏览器地址栏回车即可 例如: https://github.com/Activiti/Activiti/releases/download/ac ...
- 使用gitlab自带的ci/cd实现.net core应用程序的部署
这两天在折腾持续集成和交付,公司考虑使用gitlab自带的ci/cd来处理,特此记下来整个流程步骤. 好记性不如一支烂笔头---尼古拉斯-古人言 第一步: 安装gitlab,这个自然不用多说 第二步: ...
- POJ 1410 判断线段与矩形交点或在矩形内
这个题目要注意的是:给出的矩形坐标不一定是按照左上,右下这个顺序的 #include <iostream> #include <cstdio> #include <cst ...