kafka的安装及使用
前言花絮
今天听了kafka开发成员之一的饶军老师的讲座,讲述了kafka的前生今世。干货的东西倒是没那么容易整理出来,还得刷一遍视频整理,不过两个比较八卦的问题,倒是很容易记住了。
Q:为什么kafka使用了Scala进行开发?
A:因为当年主R正在学习Scala,所以就用Scala开发了。并且这是他的第一个Scala项目。也正是因为他也在学习阶段,所以写出来的代码都是按照Java的写法实现的,这也是为什么Java开发者也能很容易读懂源码的原因。
Q:为什么kafka叫kafka?
A:因为主R在开发kafka的时候正在看卡夫卡的《变形记》,所以没有多想就用了kafka这个名字。同时,因为kafka实际上是以日志的形式记录消息的,属于一个书写者,所以用一位作家的名字命名也是很契合的。
思考:大佬们开发东西真随意。
先来说下kafka是个什么东西,它是一个消息中间件框架,只负责发布--订阅(帮忙存东西的)
接着给大家看一张大致的kafka流程图

首先打个比方,kafka好比就是中央电视台,而中央电视台下面有很多节目,生产者就是制作节目的团队,而消费者就是我们观看这个节目的人,一开始在zookeeper创建一个节目,假设就叫cctv1,有了这个节目名后,我们就得请一个团队来填充这个节目,比如拉广告啊,放电视剧之类的数据,而我们消费者要观看这个节目的话就得需要zookeeper来授权给我们。中央电视台则只是存数据的,相当于一个中间人,和现在中介差不多个意思。
1. 下载kafka的安装包到电脑上并传输到Linux中的hadoop用户下
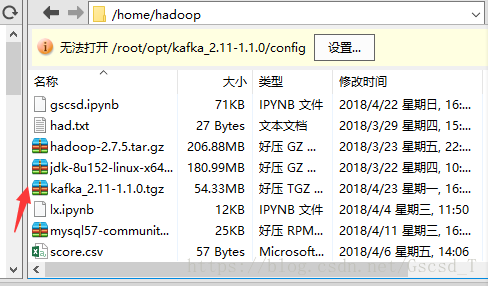
2. 将这个压缩包解压到hadoop用户的opt目录下

接着就会在opt目录下看到这个文件夹(/opt: 这是给主机额外安装软件所摆放的目录。比如你安装一个ORACLE数据库就可以放到这个目录下。默认是空的。)
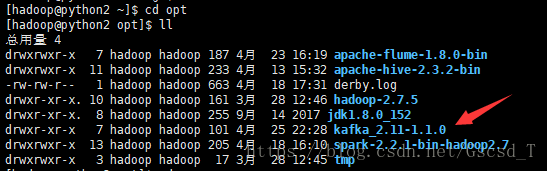
3. 进入到该目录下 /home/hadoop/opt/kafka_2.11-1.1.0/config目录,将 zookeeper.properties 中的信息筛选出来并将筛选出来的数据给一个新建的文件zk.properties
 #把非注释行信息筛选出来
#把非注释行信息筛选出来
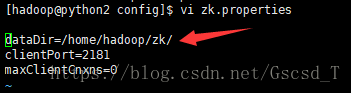
接着vi zk.properties这个文件,修改dataDir,将来zookeeper的信息都记录在这个目录下,即dataDir=/home/hadoop/zk/
4. 启动zookeeper
要在该/home/hadoop/opt/kafka_2.11-1.1.0目录下启动
./bin/zookeeper-server-start.sh config/zk.properties

接着我们复制该窗口,jps一下,就会看到新开的服务QuorumPeerMain(仲裁的一个机制的东西),这个东西就是zookeeper的进程
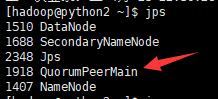 #jps 用于查看当前服务器中的java进程,类似于ps -ef | grep java,不同之处是它是由jdk提供的,可以输出JVM中运行的进程状态信息,因此它也可以用于jvm的监控和调优
#jps 用于查看当前服务器中的java进程,类似于ps -ef | grep java,不同之处是它是由jdk提供的,可以输出JVM中运行的进程状态信息,因此它也可以用于jvm的监控和调优
5. 启动broker(kafka)
我们这个是单机模式:
进入该目录/home/hadoop/opt/kafka_2.11-1.1.0/config,和上面一样,将一个文件的数据重定向到另一个新目录,将带有#注释的代码去掉
cat server.properties | grep -v '#' >>kafka1.properties

然后启动kafka,要在bin目录下,和上面一样
./bin/kafka-server-start.sh config/kafka1.properties

启动了后,jps一下,就会发现启动了一个名叫Kafka的进程,说明我们已经启动成功了
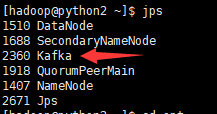
6. 创建一个主题
这里相当于中央电视台创建了一个叫cctv1的节目
还是在/home/hadoop/opt/kafka_2.11-1.1.0目录下启动创建
sh ./bin/kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 1 --partitions 1 --topic cctv1 #创建到 zookeeper上地址是localhost:2181,cctv1是主题名

然后就可以用命令查看一下该主题是否已经创建,看到这个cctv1就说明创建成功了
sh ./bin/kafka-topics.sh --list --zookeeper localhost:2181

到这里就已经完成了kafka在zookeeper上创建了一个cctv1的主题,然后就需要一个生产者来制作节目,并往cctv1中灌入数据
7. 发布消息(生产者)
./bin/kafka-console-producer.sh --broker-list localhost:9092 --topic cctv1

这是一个kafka自带的控制台的消息者,这里要注意的一点是端口号为9092,说明这个东西默认监控的端口号是9092,我们可以来看下这个端口
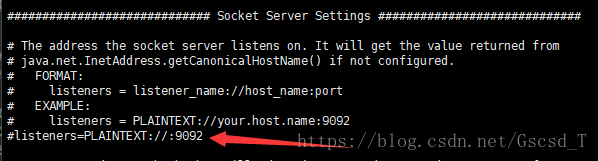
查看server.properties这个文件

会看到箭头指向的地方有个注释,如果不想用这个端口,可以把这句前面的#去掉,然后将端口号改为自己想监控的端口号
也可以来查看下这个端口号,发现正在监控
 #Linux netstat 命令用于显示网络状态。利用 netstat 指令可让你得知整个 Linux 系统的网络情况。
#Linux netstat 命令用于显示网络状态。利用 netstat 指令可让你得知整个 Linux 系统的网络情况。
随机输入两条数据,并没有什么变化,因为这个数据borker(经理人)帮忙存着,但这个数据看不到,必须要有一个消费者帮忙消费才能看到

8. 启动消费者
相当于订阅了cctv1这个频道
./bin/kafka-console-consumer.sh--bootstrap-server localhost:9092 --topic cctv1

启动消费者后,并没有发生什么变化,这时候我们就在生产者中再输入几条消息
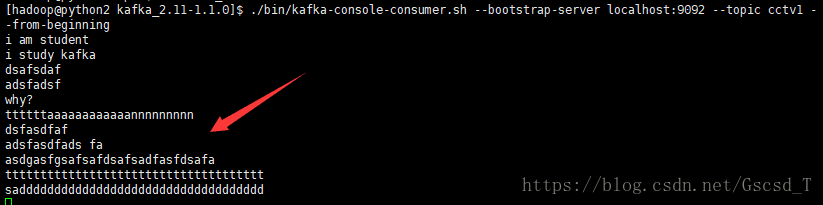
接着就会看到消费者那边出来了数据,但看到的数据只有刚刚输入的

那之前输入的数据怎么看?
输入这个命令就行了
./bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic cctv1 --from-beginning
就是在启动消费者时后面加了一个 --from-beginning,就是说明这个cctv1电视台成数字电视台了,可以点播,可以看之前所有的信息,--from-beginning表示从开头开始看,其实它可以从任意一个偏移量开始看

随后再来实验一下,我们在生产者那里接着再输入多条数据
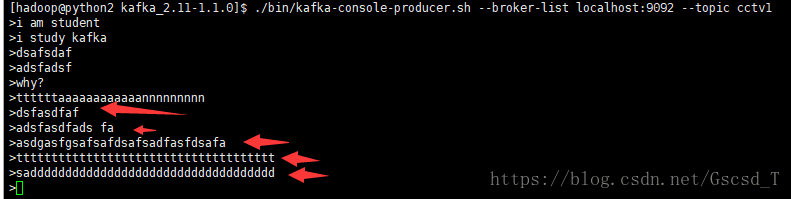
随后发现消费者也出来对应的数据

而我们刚刚启动查询所有的信息的那个服务里面也显示出相应的信息
注意:
zookeeper只能启动奇数,比如1台 、3台、7台等等,不能偶数台,偶数台的话假设有两台,那么只有一台机器再运行,因为如果是偶数的话,选举出来的管理者有可能两个borker得到的票数相同,奇数的话就不会出现这个情况。
上面演示的是简单的操作,我们也可以在kafka上写如何放数据,如何读数据,全部用代码来实现。
参考:
https://blog.csdn.net/gscsd_t/java/article/details/80089269
https://blog.csdn.net/u011291072/article/details/80009928
kafka的安装及使用的更多相关文章
- Kafka的安装和部署及测试
1.简介 大数据分析处理平台包括数据的接入,数据的存储,数据的处理,以及后面的展示或者应用.今天我们连说一下数据的接入,数据的接入目前比较普遍的是采用kafka将前面的数据通过消息的方式,以数据流的形 ...
- Linux下Kafka单机安装配置方法(图文)
Kafka是一个分布式的.可分区的.可复制的消息系统.它提供了普通消息系统的功能,但具有自己独特的设计.这个独特的设计是什么样的呢 介绍 Kafka是一个分布式的.可分区的.可复制的消息系统.它提供了 ...
- kafka的安装以及基本用法
kafka的安装 kafka依赖于ZooKeeper,所以在运行kafka之前需要先部署ZooKeeper集群,ZooKeeper集群部署方式分为两种,一种是单独部署(推荐),另外一种是使用kafka ...
- kafka manager安装配置和使用
kafka manager安装配置和使用 .安装yum源 curl https://bintray.com/sbt/rpm/rpm | sudo tee /etc/yum.repos.d/bintra ...
- kafka 的安装部署
Kafka 的简介: Kafka 是一款分布式消息发布和订阅系统,具有高性能.高吞吐量的特点而被广泛应用与大数据传输场景.它是由 LinkedIn 公司开发,使用 Scala 语言编写,之后成为 Ap ...
- Kafka学习之路 (四)Kafka的安装
一.下载 下载地址: http://kafka.apache.org/downloads.html http://mirrors.hust.edu.cn/apache/ 二.安装前提(zookeepe ...
- centos php Zookeeper kafka扩展安装
如题,系统架构升级引入消息机制,php 安装还是挺麻烦的,网上各种文章有的东拼西凑这里记录下来做个备忘,有需要的同学可以自行参考安装亲测可行 1 zookeeper扩展安装 1.安装zookeeper ...
- Linux下Kafka单机安装配置方法
Kafka是一个分布式的.可分区的.可复制的消息系统.它提供了普通消息系统的功能,但具有自己独特的设计.这个独特的设计是什么样的呢? 首先让我们看几个基本的消息系统术语: •Kafka将消息以topi ...
- Kafka Manager安装部署及使用
为了简化开发者和服务工程师维护Kafka集群的工作,yahoo构建了一个叫做Kafka管理器的基于Web工具,叫做 Kafka Manager.本文对其进行部署配置,并安装配置kafkatool对k ...
- 【kafka】安装部署kafka集群(kafka版本:kafka_2.12-2.3.0)
3.2.1 下载kafka并安装kafka_2.12-2.3.0.tgz tar -zxvf kafka_2.12-2.3.0.tgz 3.2.2 配置kafka集群 在config/server.p ...
随机推荐
- 软件案例分析——VS和VS Code
软件案例分析--VS和VS Code 项目 内容 这个作业属于哪个课程/ 2020年春季计算机学院软件工程(罗杰 任健) 这个作业的要求在哪里? 软件案例分析 我在这个课程的目标是? 提高代码水平,熟 ...
- 嵌入式单片机stm32之DMA实验
一. 对于大容量的STM32芯片有2个DMA控制器,控制器1有7个通道,控制器2有5个通道 每个通道都可以配置一些外设的地址. 二. 通道的配置过程: 1. 首先设置CPARx寄存器和CMARx寄存器 ...
- C++ map操作——插入、查找、遍历
c++ map 操作学习 #include <iostream> #include <map> #include <string> #include <vec ...
- analysis_screencap
#!/usr/bin/env pythonfrom PIL import Imageimg = Image.open("./screen.png")maps = [[] for i ...
- [WPF] 使用三种方式实现弧形进度条
1. 需求 前天看到有人问弧形进度条怎么做,我模仿了一下,成果如下图所示: 当时我第一反应是可以用 Microsoft.Toolkit.Uwp.UI.Controls 里的 RadialGauge 实 ...
- Redis源码分析(intset)
源码版本:4.0.1 源码位置: intset.h:数据结构的定义 intset.c:创建.增删等操作实现 1. 整数集合简介 intset是Redis内存数据结构之一,和之前的 sds. skipl ...
- MySQL新建用户并赋予权限:解决命令行与Navicat展示数据库不一致问题
1.创建新用户 'xiaoxiao'密码'123456' mysql> CREATE USER 'xiaoxiao'@'localhost' IDENTIFIED BY '123456'; 2. ...
- yum设置取消代理
unset http_proxy unset https_proxy 暂时取消代理,若永久取消代理,需要修改/etc/yum.conf 去掉 proxy=http://proxyhost:8080
- loto示波器实践——超声波测距模块
我们这里用到的超声波测距模块,一般是用于arduino智能小车自动避障的.经常见到的应用是使用单片机或者stm32和这种模块结合进行开发的. 我们使用LOTO示波器可以更直观和快速的看到超声波测量距离 ...
- 猿猿有责,维持整洁的 Git 提交记录,三个锦囊送给你
背景 大家都有学习如何规范简洁的编写代码,但却很少学习如何规范简洁的提交代码.现在大家基本上都用 Git 作为源码管理的工具,Git 提供了极大的灵活性,我们按照各种 workflow 来提交/合并 ...