梯度下降做做优化(batch gd、sgd、adagrad )
首先说明公式的写法
上标代表了一个样本,下标代表了一个维度;
然后梯度的维度是和定义域的维度是一样的大小;
1、batch gradient descent:
假设样本个数是m个,目标函数就是J(theta),因为theta 参数的维度是和 单个样本 x(i) 的维度是一致的,theta的维度j thetaj是如何更新的呢??

说明下 这个公式对于 xj(i)
需要说明,这个代表了样本i的第j个维度;这个是怎么算出来的,要考虑 htheta
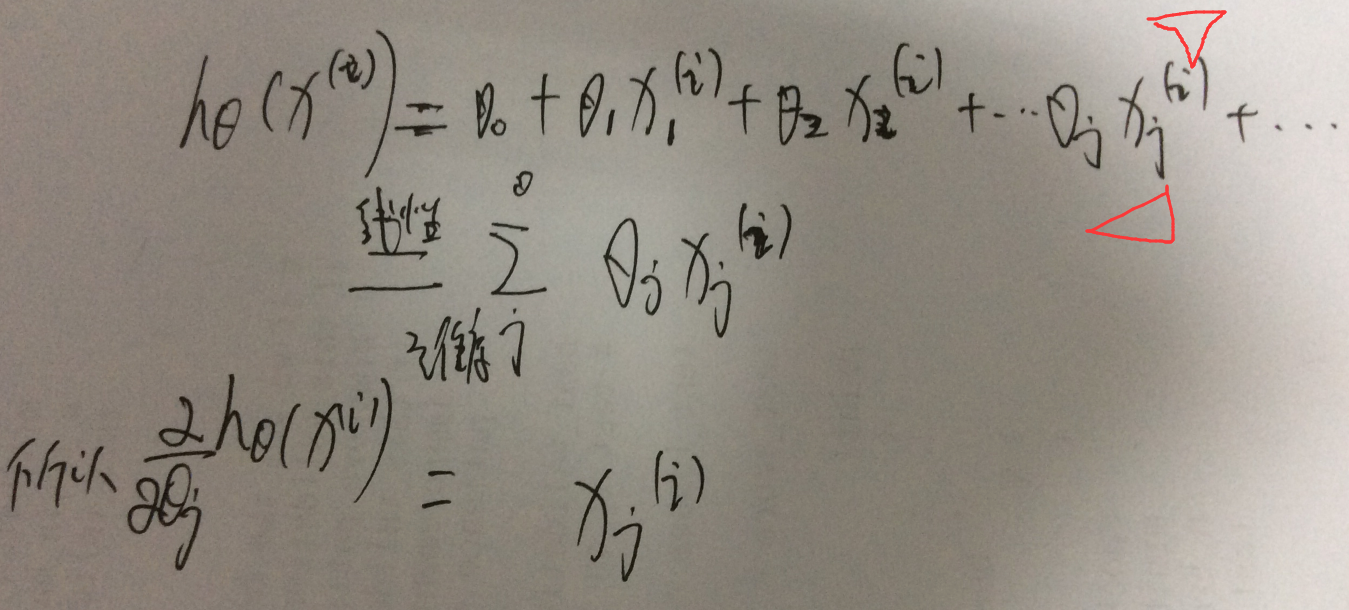
2、SGD
可以看到 theta的一个维度j的一次更新是要遍历所有样本的,这很不科学

转换为 单个样本更新一次,就是sgd

3、什么是adagrad
就是 自适应sgd,是在sgd上的改进
3.1、首先总结sgd的缺点

就是参数 theta的第t+1次更新的时候
使用theta的上一次取值-learning rate* 目标函数C在theta的上一个取值时候的梯度;-----其实梯度是一个向量既有大小也要方向(一维的时候,斜率就是梯度越大代表月陡峭 变化快)----梯度大小代表了变化快慢程度,梯度越大代表变化越快
但是learning raste eta是固定的,这会有问题的,实际希望 eta是可以动态变化的

也就是说如果梯度 steep,那么希望eta 可以小一点,不要走那么快吗!如果梯度 很平滑,那么可以走快一点
3.2、adagrad具体推理过程


4、具体实现:关于sempre中是如何做的?这里传入的梯度是没有做L1之前的梯度
所以总共有三种情况,这里的实现主要是2这种情况;
》》最早的解决L1就是sgd-l1(naive) 是用次梯度
缺点 不能compact 更新所有特征
》》sgd-l1(clipping) 做剪枝
》》sgd-l1(clipping+lazy_update)<=====>sgd-l1(cumulative penalty) 做懒更新
4.1、实现 sgd-l1(clipping)
首先看下 sgd-l1 nonlazy的操作,就是 做 clipping sgd-l1(clipping),所谓cliping就是对于penalty 做拉成0的操作。
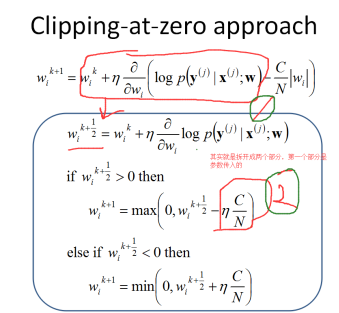
就是简单看下 wi是正还是负,然后取值{1,0,-1},然后那个参数C是控制 the strength of regularization。这种对应的就是 sempre的 nonlzay的情况:
Params.opts.l1Reg = "nonlazy" will reduce the sizes of all parameter weights for each training example, which takes a lot of time.

Adagrad如何计算梯度呢?

梯度下降做做优化(batch gd、sgd、adagrad )的更多相关文章
- 几种梯度下降方法对比(Batch gradient descent、Mini-batch gradient descent 和 stochastic gradient descent)
https://blog.csdn.net/u012328159/article/details/80252012 我们在训练神经网络模型时,最常用的就是梯度下降,这篇博客主要介绍下几种梯度下降的变种 ...
- 各种梯度下降 bgd sgd mbgd adam
转载 https://blog.csdn.net/itchosen/article/details/77200322 各种神经网络优化算法:从梯度下降到Adam方法 在调整模型更新权重和偏差 ...
- 批量梯度下降(BGD)、随机梯度下降(SGD)以及小批量梯度下降(MBGD)的理解
梯度下降法作为机器学习中较常使用的优化算法,其有着三种不同的形式:批量梯度下降(Batch Gradient Descent).随机梯度下降(Stochastic Gradient Descent ...
- 采用梯度下降优化器(Gradient Descent optimizer)结合禁忌搜索(Tabu Search)求解矩阵的全部特征值和特征向量
[前言] 对于矩阵(Matrix)的特征值(Eigens)求解,采用数值分析(Number Analysis)的方法有一些,我熟知的是针对实对称矩阵(Real Symmetric Matrix)的特征 ...
- Pytorch_第七篇_深度学习 (DeepLearning) 基础 [3]---梯度下降
深度学习 (DeepLearning) 基础 [3]---梯度下降法 Introduce 在上一篇"深度学习 (DeepLearning) 基础 [2]---神经网络常用的损失函数" ...
- 优化-最小化损失函数的三种主要方法:梯度下降(BGD)、随机梯度下降(SGD)、mini-batch SGD
优化函数 损失函数 BGD 我们平时说的梯度现将也叫做最速梯度下降,也叫做批量梯度下降(Batch Gradient Descent). 对目标(损失)函数求导 沿导数相反方向移动参数 在梯度下降中, ...
- 深度学习必备:随机梯度下降(SGD)优化算法及可视化
补充在前:实际上在我使用LSTM为流量基线建模时候,发现有效的激活函数是elu.relu.linear.prelu.leaky_relu.softplus,对应的梯度算法是adam.mom.rmspr ...
- 【DeepLearning】优化算法:SGD、GD、mini-batch GD、Moment、RMSprob、Adam
优化算法 1 GD/SGD/mini-batch GD GD:Gradient Descent,就是传统意义上的梯度下降,也叫batch GD. SGD:随机梯度下降.一次只随机选择一个样本进行训练和 ...
- 梯度下降优化算法综述与PyTorch实现源码剖析
现代的机器学习系统均利用大量的数据,利用梯度下降算法或者相关的变体进行训练.传统上,最早出现的优化算法是SGD,之后又陆续出现了AdaGrad.RMSprop.ADAM等变体,那么这些算法之间又有哪些 ...
随机推荐
- 两人团队项目-石家庄地铁查询系统(web版)psp表
结对开发_石家庄地铁查询_博客地址:https://www.cnblogs.com/Aduorisk/p/10652917.html 队友:冯利伟 PSP: PSP0 Personal Softwar ...
- python + pytest基本使用方法(拓展库)
一.测试钩子配置文件 import pytest# conftest.py 是pytest特有的本地测试配置文件;# 既可以用来设置项目级别的Fixture,也可用来导入外部插件,还可以指定钩子函数# ...
- python + Excel数据读取(更新)
data.xlsx 数据如下: import xlrd#1.读取Excel数据# table = xlrd.open_workbook("data.xlsx","r&qu ...
- Ubuntu 18.04 开启 root 账号并允许远程连接
转载:https://blog.csdn.net/u010766726/article/details/105376461 以普通用户登录系统 通过 "终端" 操作 普通用户 – ...
- 扩展欧几里得(exgcd)-求解不定方程/求逆元
贝祖定理:即如果a.b是整数,那么一定存在整数x.y使得ax+by=gcd(a,b).换句话说,如果ax+by=m有解,那么m一定是gcd(a,b)的若干倍.(可以来判断一个这样的式子有没有解)有一个 ...
- Linux 数据库操作(一)
我们可以将用于数据服务的数据库分为关系型数据库和非关系型数据库,关系型数据库最典型的就是Mysql,以及和他同源的MariaDB数据库,oracle等,非关系型数据库则有redis数据库,mongod ...
- 一个故事看懂HTTPS
我是一个浏览器,每到夜深人静的时候,主人就打开我开始学习. 为了不让别人看到浏览记录,主人选择了"无痕模式". 但网络中总是有很多坏人,他们通过抓包截获我和服务器的通信,主人干了什 ...
- web浏览器知识点
网页是怎么形成的 前端的代码(英文字母)---->浏览器渲染 ------- > 客户眼中的效果 浏览器(显示代码) 游览器是网页显示,运行的平台,常用的的游览器有IE(Edge).火狐 ...
- BUUCTF-[SUCTF 2019]CheckIn(.user.ini利用+exif_imagetype绕过)
目录 分析 .user.ini使用条件 解题 参考链接 记一道.user.ini利用+exif_imagetype绕过的文件上传的题. 分析 先正经上传一张图片.回显了存储路径,同时发现还包含了一个i ...
- 腾讯云TDSQL PostgreSQL版 -最佳实践 |优化 SQL 语句
查看是否为分布键查询 postgres=# explain select * from tbase_1 where f1=1; QUERY PLAN ------------------------- ...