梯度下降做做优化(batch gd、sgd、adagrad )
首先说明公式的写法
上标代表了一个样本,下标代表了一个维度;
然后梯度的维度是和定义域的维度是一样的大小;
1、batch gradient descent:
假设样本个数是m个,目标函数就是J(theta),因为theta 参数的维度是和 单个样本 x(i) 的维度是一致的,theta的维度j thetaj是如何更新的呢??

说明下 这个公式对于 xj(i)
需要说明,这个代表了样本i的第j个维度;这个是怎么算出来的,要考虑 htheta
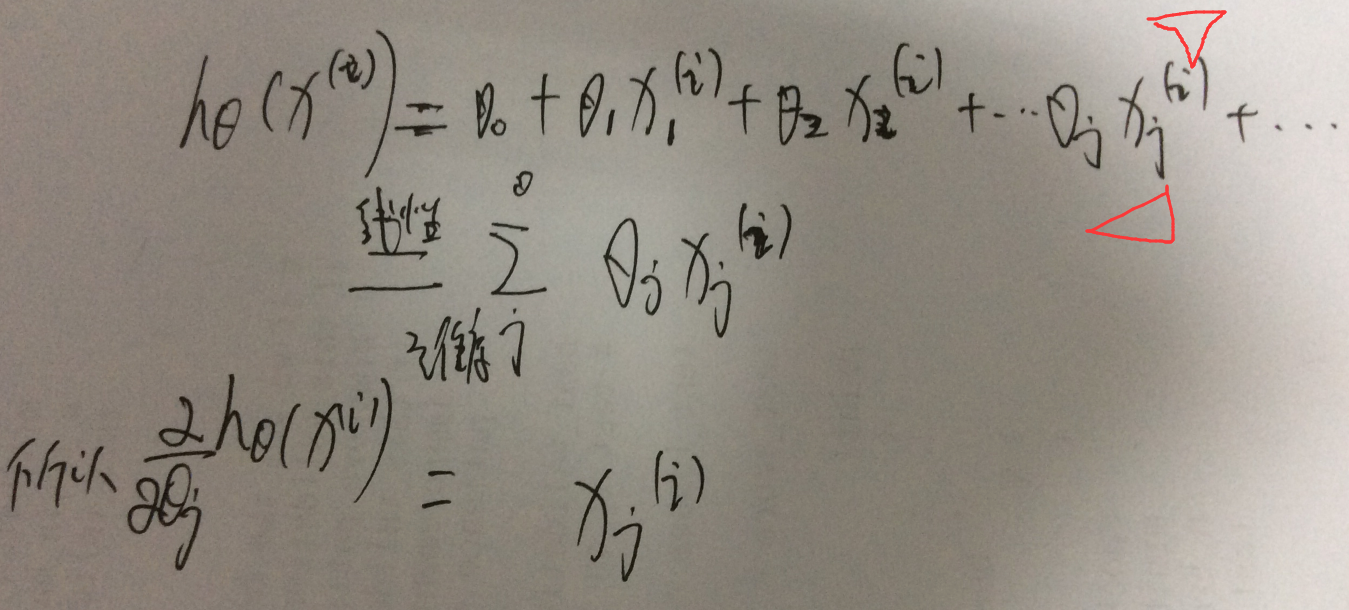
2、SGD
可以看到 theta的一个维度j的一次更新是要遍历所有样本的,这很不科学

转换为 单个样本更新一次,就是sgd

3、什么是adagrad
就是 自适应sgd,是在sgd上的改进
3.1、首先总结sgd的缺点

就是参数 theta的第t+1次更新的时候
使用theta的上一次取值-learning rate* 目标函数C在theta的上一个取值时候的梯度;-----其实梯度是一个向量既有大小也要方向(一维的时候,斜率就是梯度越大代表月陡峭 变化快)----梯度大小代表了变化快慢程度,梯度越大代表变化越快
但是learning raste eta是固定的,这会有问题的,实际希望 eta是可以动态变化的

也就是说如果梯度 steep,那么希望eta 可以小一点,不要走那么快吗!如果梯度 很平滑,那么可以走快一点
3.2、adagrad具体推理过程


4、具体实现:关于sempre中是如何做的?这里传入的梯度是没有做L1之前的梯度
所以总共有三种情况,这里的实现主要是2这种情况;
》》最早的解决L1就是sgd-l1(naive) 是用次梯度
缺点 不能compact 更新所有特征
》》sgd-l1(clipping) 做剪枝
》》sgd-l1(clipping+lazy_update)<=====>sgd-l1(cumulative penalty) 做懒更新
4.1、实现 sgd-l1(clipping)
首先看下 sgd-l1 nonlazy的操作,就是 做 clipping sgd-l1(clipping),所谓cliping就是对于penalty 做拉成0的操作。
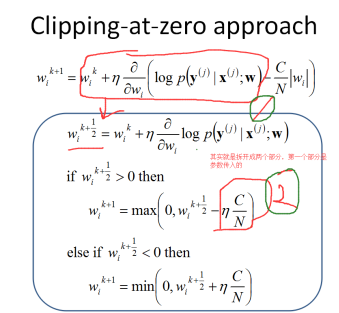
就是简单看下 wi是正还是负,然后取值{1,0,-1},然后那个参数C是控制 the strength of regularization。这种对应的就是 sempre的 nonlzay的情况:
Params.opts.l1Reg = "nonlazy" will reduce the sizes of all parameter weights for each training example, which takes a lot of time.

Adagrad如何计算梯度呢?

梯度下降做做优化(batch gd、sgd、adagrad )的更多相关文章
- 几种梯度下降方法对比(Batch gradient descent、Mini-batch gradient descent 和 stochastic gradient descent)
https://blog.csdn.net/u012328159/article/details/80252012 我们在训练神经网络模型时,最常用的就是梯度下降,这篇博客主要介绍下几种梯度下降的变种 ...
- 各种梯度下降 bgd sgd mbgd adam
转载 https://blog.csdn.net/itchosen/article/details/77200322 各种神经网络优化算法:从梯度下降到Adam方法 在调整模型更新权重和偏差 ...
- 批量梯度下降(BGD)、随机梯度下降(SGD)以及小批量梯度下降(MBGD)的理解
梯度下降法作为机器学习中较常使用的优化算法,其有着三种不同的形式:批量梯度下降(Batch Gradient Descent).随机梯度下降(Stochastic Gradient Descent ...
- 采用梯度下降优化器(Gradient Descent optimizer)结合禁忌搜索(Tabu Search)求解矩阵的全部特征值和特征向量
[前言] 对于矩阵(Matrix)的特征值(Eigens)求解,采用数值分析(Number Analysis)的方法有一些,我熟知的是针对实对称矩阵(Real Symmetric Matrix)的特征 ...
- Pytorch_第七篇_深度学习 (DeepLearning) 基础 [3]---梯度下降
深度学习 (DeepLearning) 基础 [3]---梯度下降法 Introduce 在上一篇"深度学习 (DeepLearning) 基础 [2]---神经网络常用的损失函数" ...
- 优化-最小化损失函数的三种主要方法:梯度下降(BGD)、随机梯度下降(SGD)、mini-batch SGD
优化函数 损失函数 BGD 我们平时说的梯度现将也叫做最速梯度下降,也叫做批量梯度下降(Batch Gradient Descent). 对目标(损失)函数求导 沿导数相反方向移动参数 在梯度下降中, ...
- 深度学习必备:随机梯度下降(SGD)优化算法及可视化
补充在前:实际上在我使用LSTM为流量基线建模时候,发现有效的激活函数是elu.relu.linear.prelu.leaky_relu.softplus,对应的梯度算法是adam.mom.rmspr ...
- 【DeepLearning】优化算法:SGD、GD、mini-batch GD、Moment、RMSprob、Adam
优化算法 1 GD/SGD/mini-batch GD GD:Gradient Descent,就是传统意义上的梯度下降,也叫batch GD. SGD:随机梯度下降.一次只随机选择一个样本进行训练和 ...
- 梯度下降优化算法综述与PyTorch实现源码剖析
现代的机器学习系统均利用大量的数据,利用梯度下降算法或者相关的变体进行训练.传统上,最早出现的优化算法是SGD,之后又陆续出现了AdaGrad.RMSprop.ADAM等变体,那么这些算法之间又有哪些 ...
随机推荐
- Jmeter性能测试指标分析
一.Aggregate Report 是 JMeter 常用的一个 Listener,中文被翻译为"聚合报告 如果大家都是做Web应用的性能测试,例如访问百度请求为例,线程10,循环10次, ...
- 每天五分钟Go - 循环语句
带条件的for循环 for init; condition; post { } 示例代码 for i:=0;i<10;i++{ fmt.Println("current:", ...
- 笛卡尔树-P2659 美丽的序列
P2659 美丽的序列 tag 笛卡尔树 题意 找出一个序列的所有子段中子段长度乘段内元素最小值的最大值. 思路 我们需要找出所有子段中贡献最大的,并且一个子段的贡献为其长度乘区间最小值. 这--不就 ...
- 【Linux服务器双IP配置】如何实现不同IP的双网卡同时上网?
一.环境和知识预备 我遇到问题的生产机器是CentOS release 6.8系统,不过这并不影响问题的解决,本质上都是一样的. 网关:一个网络连接到另一个网络的关口,也就是实现网络互连,俗称网络连接 ...
- 构建前端第6篇之---内嵌css样式 <el-button style="width:100%"> 登录 </el-button>
张艳涛写于2021-1-20日 What: 如何让button的长度和input长度一致呢 最先想到的是给这个button加一个class ="buttonclass",然后在vu ...
- 手撸一个SpringBoot-Starter
1. 简介 通过了解SpringBoot的原理后,我们可以手撸一个spring-boot-starter来加深理解. 1.1 什么是starter spring官网解释 starters是一组方便的依 ...
- Netty 源码分析系列(二)Netty 架构设计
前言 上一篇文章,我们对 Netty做了一个基本的概述,知道什么是Netty以及Netty的简单应用. Netty 源码分析系列(一)Netty 概述 本篇文章我们就来说说Netty的架构设计,解密高 ...
- JAVAWEB过滤器、监听器的作用及使用>从零开始学JAVA系列
目录 JAVAWEB过滤器.拦截器的作用及使用 过滤器Filter 什么是过滤器 为什么要使用过滤器(过滤器所能解决的问题) 配置一个过滤器完成编码的过滤 编写一个EncodingFilter(名称自 ...
- Mybatis源码解析1—— JDBC
在之前的文章中,我为大家介绍了 Mybatis 的详细用法,算是基础教程. 详细链接:Mybatis 基础教程 言归正传,只懂基础可不行,接下来将给大家带来高阶的源码解析教程,从浅入深,通过源码解析, ...
- Windows协议 NTLM篇
NTLM 基础 介绍 LM Hash & NTLM Hash Windows本身是不会存储明文密码的,只保存密码的hash 其中本机用户的密码hash是放在本地的SAM文件里面,域内用户的密码 ...