Python第三周 数据类型:集合set、文件的读写、追加操作。
集合
知识点:集合是无序的
格式:{1,2,3,"str_test"}
set_1 = set(list1)#将列表转换为集合
集合关系测试:
集合的逻辑判断、取交集、并集、差集、子集、父集
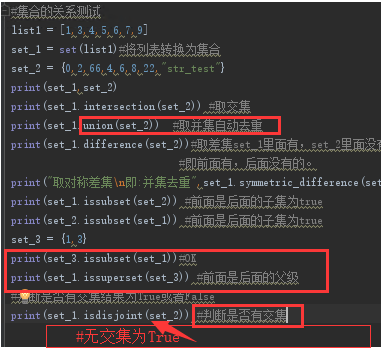
用数学运算符进行关系测试。

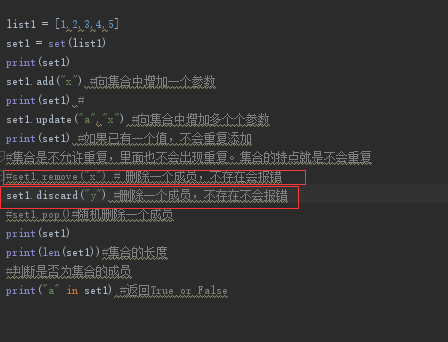
集合的增删
文件操作
先了解下文件描述符
https://www.cnblogs.com/zhangmingda/p/11715113.html
读。open(“文件名”,encoding="utf-8")默认为只读模式即 = open(“文件名”,“r”,encoding="utf-8")
open 详解如下
'''
函数语法
open(name[, mode[, buffering]])
参数说明: name : 一个包含了你要访问的文件名称的字符串值。 mode : mode 决定了打开文件的模式:只读,写入,追加等。所有可取值见如下的完全列表。这个参数是非强制的,默认文件访问模式为只读(r)。 buffering : 如果 buffering 的值被设为 0,就不会有寄存。
如果 buffering 的值取 1,访问文件时会寄存行。
如果将 buffering 的值设为大于 1 的整数,表明了这就是的寄存区的缓冲大小。
如果取负值,寄存区的缓冲大小则为系统默认。
------------------------ mode 详细模式区别
'''
不同模式打开文件的完全列表: 模式 描述
r 以只读方式打开文件。文件的指针将会放在文件的开头。这是默认模式。
rb 以二进制格式打开一个文件用于只读。文件指针将会放在文件的开头。这是默认模式。
r+ 打开一个文件用于读写。文件指针将会放在文件的开头。
rb+ 以二进制格式打开一个文件用于读写。文件指针将会放在文件的开头。
w 打开一个文件只用于写入。如果该文件已存在则打开文件,并从开头开始编辑,即原有内容会被删除。如果该文件不存在,创建新文件。
wb 以二进制格式打开一个文件只用于写入。如果该文件已存在则打开文件,并从开头开始编辑,即原有内容会被删除。如果该文件不存在,创建新文件。
w+ 打开一个文件用于读写。如果该文件已存在则打开文件,并从开头开始编辑,即原有内容会被删除。如果该文件不存在,创建新文件。
wb+ 以二进制格式打开一个文件用于读写。如果该文件已存在则打开文件,并从开头开始编辑,即原有内容会被删除。如果该文件不存在,创建新文件。
a 打开一个文件用于追加。如果该文件已存在,文件指针将会放在文件的结尾。也就是说,新的内容将会被写入到已有内容之后。如果该文件不存在,创建新文件进行写入。
ab 以二进制格式打开一个文件用于追加。如果该文件已存在,文件指针将会放在文件的结尾。也就是说,新的内容将会被写入到已有内容之后。如果该文件不存在,创建新文件进行写入。
a+ 打开一个文件用于读写。如果该文件已存在,文件指针将会放在文件的结尾。文件打开时会是追加模式。如果该文件不存在,创建新文件用于读写。
ab+ 以二进制格式打开一个文件用于追加。如果该文件已存在,文件指针将会放在文件的结尾。如果该文件不存在,创建新文件用于读写。
'''
arwb+
'''

read()读取全部内容:
read(数字)读取文件的前XXX个字符。
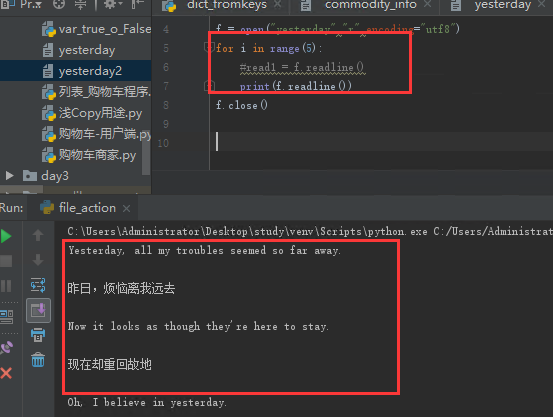
readline()读取一行,然后文件指针向下走一行,
读取前5行,通过readline(),+for 循环
readlines() 将文件内容每行作为一个列表key,制作一个列表出来。会读到内存中只适合小文件。
通过for循环取出这个列表的所有内容,即可打印文件全部内容

注意:readlines()的坑(缺点,耗能耗内存)

如下直接for循环open()的迭代器的方法为最高效的方法。
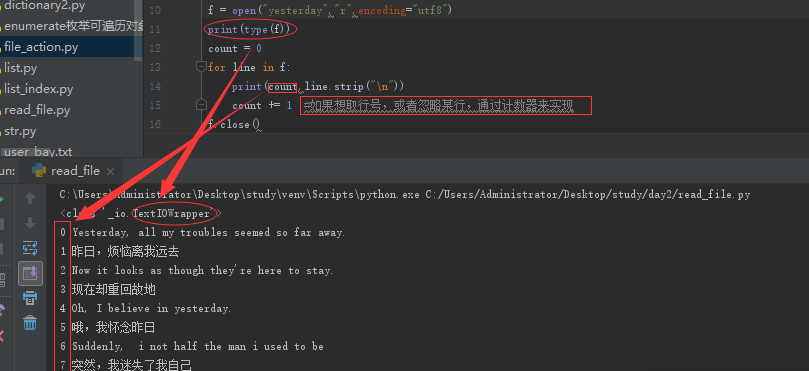
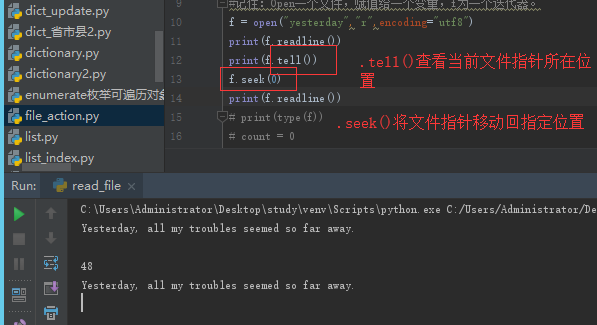
文件指针移动方法:seek(指针位置=数字);.tell查看当前指针位置
判断:是否可读、可写、可移动文件指针

刷新flush() 作用:即时将文件修改写入硬盘。否则会暂时存在内存中,数据到达指定值再写入磁盘。

 发现没有写入到文件
发现没有写入到文件
flush()后再看:

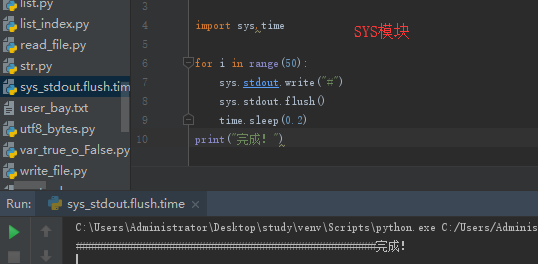
flush()第二个应用:进度条
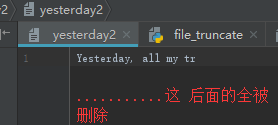
截断文件内容:truncate,只保留文件内容的前XXXX个字符

文件读写指针:读写、写读、追加读写、文件句柄二进制文件

以二进制形式写入文件

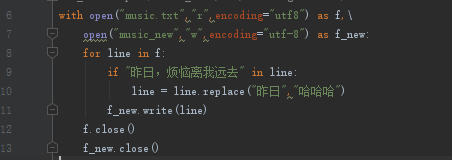
修改文件内容(读取一个文件,写入一个新的文件)
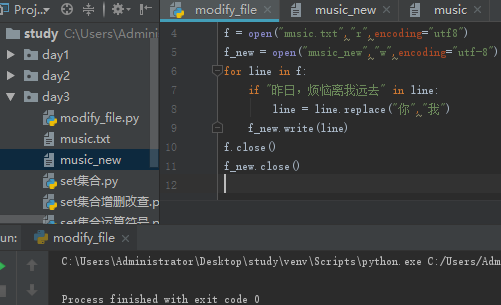
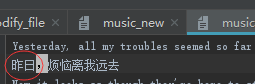
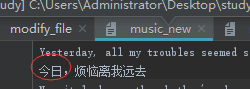
自动关闭打开的文件的小技巧:with XXXX as 变量名称:
跳过某行不打印可以用enumerate() 来枚举index。
例如:跳过第二行(用“===”代替)
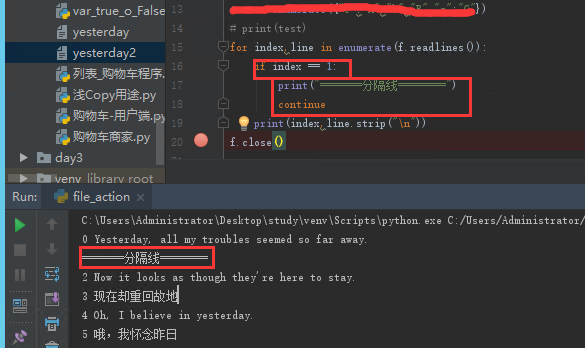
=写入=========================================================================
写= 新建文件/覆盖原有文件,写入不能读
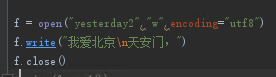

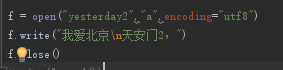
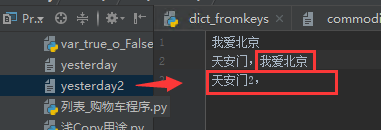
向已有文件中追加内容。“a”方式打开
Python第三周 数据类型:集合set、文件的读写、追加操作。的更多相关文章
- python第三周:集合、函数、编码、文件
1.集合: 集合的创建: list_1 = set([1,2,3,4,5]) list_2 = set([2,3,44,7,8]) 集合的特性:集合是无序的,集合可以去掉重复的元素 集合的操作:求交集 ...
- java对excel文件内容读写修改操作
Read.java package domain; import java.io.FileInputStream; import java.io.InputStream; import jxl.Cel ...
- python第二周数据类型 字符编码 文件处理
第一数据类型需要学习的几个点: 用途 定义方式 常用操作和内置的方法 该类型总结: 可以存一个值或者多个值 只能存储一个值 可以存储多个值,值都可以是什么类型 有序或者无序 可变或者不可变 二:数字整 ...
- Python 函数基础、有序集合、文件操作(三)
一.set 特点: set是一个无序且不重复的元素集合访问速度快:天生解决元素重复问题 方法: 初始化 >>> s1 = set()>>> print(type(s ...
- python第三周文件处理和函数-----下
#默认参数的值是在一开始定义的时候就传给了函数, # 在后来的修改中不会被修改. #默认参数的值必须放到位置形参参数的最后面 #默认参数使用的场景是一个参数不经常变得场景,所以参数一般是不可变类型.字 ...
- 人生苦短我用Python 第三周 函数周
函数的定义: 1,def 函数名(参数1,参数2......): "注释:函数的作用和参数,增加可读性", 2,函数体 3,返回值 最简单的函数: def func(): prin ...
- Python Web-第三周-Networks and Sockets(Using Python to Access Web Data)
1.Networked Programs 1.Internet 我们现在学习Internet部分,即平时我们浏览器做的事情,之后再学习客服端这部分 2.TCP 传输控制协议 3.Socket HTTP ...
- Python第三周第一次作业中关于工程目录各种导入的模拟学习
目录 Python工程目录 导入自定义模块, 包 记录的缘由 模块搜索路径 模块: 导入模块 导入函数 导入类 多个类 @(Python第三周第一次作业中工程目录,模拟学习) Python工程目录 导 ...
- python第三课——数据类型2
day03: 1.列表:list 特点:有序的(有索引.定义和显示顺序是一致的).可变的(既可以改变元素内容也可以自动扩容).可重复的. 可以存储任何的数据类型数据 定义个列表如下: lt = ['宋 ...
随机推荐
- spring boot 动态生成接口实现类
目录 一: 定义注解 二: 建立动态代理类 三: 注入spring容器 四: 编写拦截器 五: 新建测试类 在某些业务场景中,我们只需要业务代码中定义相应的接口或者相应的注解,并不需要实现对应的逻辑. ...
- bilibili动画下载视频批量改名(python)
bilib应用 在微软商店中下载哔哩哔哩动画,虽然软件UI古老,但是贵在稳定和支持下载 安装以后搜索自己想要的视频,然后缓存下载 下载后进入下载的路径 视频文件重命名 打开自动命令的程序或者py脚本, ...
- Apache发布支持Java EE微服务的Meecrowave服务器
Apache OpenWebBeans团队希望通过使服务器适应用户来消除复杂性.所以,该团队发布了Apache Meecrowave项目1.0版. Apache Meecrowave是一款小型服务器, ...
- 洛谷 P4292 - [WC2010]重建计划(长链剖分+线段树)
题面传送门 我!竟!然!独!立!A!C!了!这!道!题!incredible! 首先看到这类最大化某个分式的题目,可以套路地想到分数规划,考虑二分答案 \(mid\) 并检验是否存在合法的 \(S\) ...
- jenkins原理简析
持续集成Continuous Integration(CI) 原理图: Gitlab作为git server.Gitlab的功能和Github差不多,但是是开源的,可以用来搭建私有git server ...
- Perl哈希%hash
哈希是 key/value 键/值对的集合. Perl中哈希变量以百分号 (%) 标记开始. 访问哈希元素格式:${key}. 以下是一个简单的哈希实例: 实例 #!/usr/bin/perl %da ...
- 【Reverse】DLL注入
DLL注入就是将dll粘贴到指定的进程空间中,通过dll状态触发目标事件 DLL注入的大概流程 https://uploader.shimo.im/f/CXFwwkEH6FPM0rtT.png!thu ...
- Oracle中的索引
1.Oracle 索引简介 在Oracle数据库中,存储的每一行数据都有一个rowID来标识.当Oracle中存储着大量的数据时,意味着有大量的rowID,此时想要快速定位指定的rowID, ...
- RecyclerView实现侧滑删除、置顶、滑动
1.首先在build.gradle里添加 compile 'com.github.mcxtzhang:SwipeDelMenuLayout:V1.2.1' 2.设置recyclerView的item布 ...
- tomcat 之 httpd session stiky
# 注释中心主机 [root@nginx ~]# vim /etc/httpd/conf/httpd.conf #DocumentRoot "/var/www/html" #:配置 ...