Redis(二) 数据类型操作指令以及对应的RedisTemplate方法
1.Redis key值操作以及RedisTemplate对应的API
本文默认使用RedisTemplate,关于RedisTemplate和StringRedisTemplate的区别如下
RedisTemplate和StringRedisTemplate
二者主要区别是他们使用的序列化类不一样,RedisTemplate使用的是JdkSerializationRedisSerializer,
StringRedisTemplate使用的是StringRedisSerializer,两者的数据是不共通的。 1.RedisTemplate:
RedisTemplate使用的是JDK的序列化策略,向Redis存入数据会将数据先序列化成字节数组然后在存入Redis数据库,这个时候打开Redis查看的时候,
你会看到你的数据不是以可读的形式展现的,而是以字节数组显示,类似下面:\xAC\xED\x00\x05t\x05sr\x00。
所以使用RedisTemplate可以直接把一个java对象直接存储在redis里面。 2.StringRedisTemplate:
StringRedisTemplate默认采用的是String的序列化策略,保存的key和value都是采用此策略序列化保存的。
StringRedisTemplate是继承RedisTemplate的,这种对redis的操方式更优雅,
因为RedisTemplate以字节数组的形式存储不利于管理,也不通用。
如果存入的是简单的字符串使用StringRedisTemplate;
如果存入的是复杂的对象用RedisTemplate;
1.1 Key操作
1.1.1 常用的key操作
keys *查看当前库所有key (匹配:keys *1)
public Set<String> keys(String pattern) {
return redisTemplate.keys(pattern);
}
exists key判断某个key是否存在
public Boolean hasKey(String key) {
return redisTemplate.hasKey(key);
}
type key 查看你的key是什么类型
public DataType type(String key) {
return redisTemplate.type(key);
}
del key 删除指定的key数据
public void delete(String key) {
redisTemplate.delete(key);
}
unlink key 根据value选择非阻塞删除,仅将keys从keyspace元数据中删除,真正的删除会在后续异步操作。
public void unlink(String key) {
redisTemplate.unlink(key);
}
expire key 10 10秒钟:为给定的key设置过期时间
public Boolean expire(String key, long timeout, TimeUnit unit) {
return redisTemplate.expire(key, timeout, unit);
}
ttl key 查看还有多少秒过期,-1表示永不过期,-2表示已过期
public Long getExpire(String key) {
return redisTemplate.getExpire(key);
}
flushdb 清空当前库
public void flushdb() {
Set<String> keys = redisTemplate.keys("*");
redisTemplate.delete(keys);
}
dbsize 查看当前数据库的key的数量 // 令pattern = "*"
public Set<String> keys(String pattern) {
return redisTemplate.keys(pattern);
}
2.Redis 五大数据类型操作以及RedisTemplate对应的API
2.1 String类型
1.缓存结构体信息:
将结构体json序列化成字符串,然后将字符串保存在redis的value中,将结构体的业务唯一标示作为key;这种保存json的用法用的最多的场景就是缓存用户信息,
将用户bean信息转成json再序列化为字符串作为value保存在redis中,将用户id作为key。从代码中获取用户缓存信息就是一个逆过程,
根据userid作为key获取到结构体json,然后将json转成java bean。 2.计数功能:
我们都知道redis是单线程模式,并且redis将很多常用的事务操作进行了封装,这里我们最常用的就是数值自增或自减,redis的作者封装了incr可以进行自增,
没调用一次自增1,因为redis是单线程运行,所以就算client是多线程调用那么也是正确自增,因为incr命令中将read和write做了事务封装。
同样可以设置incr的step,每次根据step进行自增,当然如果要达到自减的效果,那么只要将step设置为负数就可以了。
计数功能使用的场景很多,我们之前经常用在实时计数统计场景,也用在过库存场景、限流计数场景等等,而且redis的性能也是非常高的,
对于一般的并发量没那么高的系统都是适用的。
2.1.1 String的数据结构
String的数据结构为简单动态字符串(Simple Dynamic String,缩写SDS)。是可以修改的字符串,内部结构实现上类似于Java的ArrayList,采用预分配冗余空间的方式来减少内存的频繁分配.

如上图中所示,内部为当前字符串实际分配的空间capacity一般要高于实际字符串长度len。当字符串长度小于1M时,扩容都是加倍现有的空间,如果超过1M,扩容时一次只会多扩1M的空间。需要注意的是字符串最大长度为512M。
2.1.2 String常用指令
set <key><value>添加键值对
public void set(String key, String value) {
redisTemplate.opsForValue().set(key, value);
}
set ... nx:当数据库中key不存在时,可以将key-value添加数据库
public boolean setIfAbsent(String key, String value) {
return redisTemplate.opsForValue().setIfAbsent(key, value);
}
set ... xx:当数据库中key存在时,可以将key-value添加数据库,与nx参数互斥
public boolean setIfPresent(String key, String value) {
return redisTemplate.opsForValue().setIfPresent(key, value);
}
set ... ex:设置key的超时秒数
set ... px:设置key的超时毫秒数 public void setEx(String key, String value, long timeout, TimeUnit unit) {
redisTemplate.opsForValue().set(key, value, timeout, unit);
}
get <key>查询对应键值
public Object get(String key) {
return redisTemplate.opsForValue().get(key);
}
append <key><value>将给定的<value> 追加到原值的末尾
public Integer append(String key, String value) {
return redisTemplate.opsForValue().append(key, value);
}
strlen <key>获得值的长度
public Long size(String key) {
return redisTemplate.opsForValue().size(key);
}
incr <key> 将 key 中储存的数字值增1,只能对数字值操作,如果为空,新增值为1
decr <key> 将 key 中储存的数字值减1,只能对数字值操作,如果为空,新增值为-1
incrby / decrby <key><步长>将 key 中储存的数字值增减。自定义步长。 public Long incrBy(String key, long increment) {
return redisTemplate.opsForValue().increment(key, increment);
}
mset <key1><value1><key2><value2> ..... 同时设置一个或多个 key-value对
public void multiSet(Map<String, String> maps) {
redisTemplate.opsForValue().multiSet(maps);
}
mget <key1><key2><key3> ..... 同时获取一个或多个 value
public List<Object> multiSet(Collection<String> keys) {
return redisTemplate.opsForValue().multiGet(keys);
}
msetnx <key1><value1><key2><value2> ..... 同时设置一个或多个 key-value 对,当且仅当所有给定 key 都不存在。原子性,有一个失败则都失败
public boolean multiSetIfAbsent(Map<String, String> maps) {
return redisTemplate.opsForValue().multiSetIfAbsent(maps);
}
getrange <key><起始位置><结束位置>获得值的范围,类似java中的substring,前包,后包
public Object getRange(String key, long start, long end) {
return redisTemplate.opsForValue().get(key, start, end);
}
setrange <key><起始位置><value> 用 <value> 覆写<key>所储存的字符串值,从<起始位置>开始(索引从0开始)。
public void setRange(String key, String value, long offset) {
redisTemplate.opsForValue().set(key, value, offset);
}
getset <key><value> 以新换旧,设置了新值同时获得旧值。
public Object getAndSet(String key, String value) {
return redisTemplate.opsForValue().getAndSet(key, value);
}
2.2 List类型
Redis 列表List类型是简单的字符串列表,按照插入顺序排序。你可以添加一个元素到列表的头部(左边)或者尾部(右边)。它的底层实际是个双向链表,对两端的操作性能很高,通过索引下标的操作中间的节点性能会较差。

应用场景
1.list列表结构常用来做异步队列使用
将需要延后处理的任务结构体序列化成字符串塞进 Redis 的列表,另一个线程从这个列表中轮询数据进行处理。 2.list可用于秒杀抢购场景
在商品秒杀场景最怕的就是商品超卖,为了解决超卖问题,我们经常会将库存商品缓存到类似MQ的队列中,多线程的购买请求都是从队列中取,
取完了就卖完了,但是用MQ处理的化有点重,这里就可以使用redis的list数据类型来实现,在秒杀前将本场秒杀的商品放到list中,
因为list的pop操作是原子性的,所以即使有多个用户同时请求,也是依次pop,list空了pop抛出异常就代表商品卖完了。
2.2.1 List的数据结构
List的数据结构为快速链表quickList。首先在列表元素较少的情况下会使用一块连续的内存存储,这个结构是ziplist,也即是压缩列表。它将所有的元素紧挨着一起存储,分配的是一块连续的内存。当数据量比较多的时候才会改成quicklist。因为普通的链表需要的附加指针空间太大,会比较浪费空间。比如这个列表里存的只是int类型的数据,结构上还需要两个额外的指针prev和next。

Redis将链表和ziplist结合起来组成了quicklist。也就是将多个ziplist使用双向指针串起来使用。这样既满足了快速的插入删除性能,又不会出现太大的空间冗余。
2.2.2 List常用的指令
lpush/rpush <key><value1><value2><value3> .... 从左边/右边插入一个或多个值。
public Long lLeftPush(String key, String value) {
return redisTemplate.opsForList().leftPush(key, value);
}
public Long lLeftPushAll(String key, String... value) {
return redisTemplate.opsForList().leftPushAll(key, value);
}
public Long lLeftPushAll(String key, Collection<String> value) {
return redisTemplate.opsForList().leftPushAll(key, value);
}
lpop/rpop <key>从左边/右边吐出一个值。值在键在,值光键亡。
public Object lLeftPop(String key) {
return redisTemplate.opsForList().leftPop(key);
}
rpoplpush <key1><key2> 从<key1>列表右边吐出一个值,插到<key2>列表左边。
public Object lRightPopAndLeftPush(String sourceKey, String destinationKey) {
return redisTemplate.opsForList().rightPopAndLeftPush(sourceKey, destinationKey);
}
lrange <key><start><stop>按照索引下标获得元素(从左到右)
lrange <key> 0 -1 0左边第一个,-1右边第一个,(0-1表示获取所有)
public List<Object> lRange(String key, long start, long end) {
return redisTemplate.opsForList().range(key, start, end);
}
lindex <key><index>按照索引下标获得元素(从左到右)
public Object lIndex(String key, long index) {
return redisTemplate.opsForList().index(key, index);
}
llen <key>获得列表长度
public Long lLen(String key) {
return redisTemplate.opsForList().size(key);
}
lset<key><index><value>将列表key下标为index的值替换成value
public void lSet(String key, long index, String value) {
redisTemplate.opsForList().set(key, index, value);
}
linsert <key> before <value><newvalue> 在<value>的前面插入<newvalue>插入值
public Long lLeftPush(String key, String pivot, String value) {
return redisTemplate.opsForList().leftPush(key, pivot, value);
}
lrem <key><n><value> n>0 从左边到右删除n个value, n<0从右到左删除n个value
public Long lRemove(String key, long index, String value) {
return redisTemplate.opsForList().remove(key, index, value);
}
2.3 Set类型
Redis set对外提供的功能与list类似是一个列表的功能,特殊之处在于set是可以自动排重的,当你需要存储一个列表数据,又不希望出现重复数据时,set是一个很好的选择,并且set提供了判断某个成员是否在一个set集合内的重要接口,这个也是list所不能提供的。
Redis的Set是string类型的无序集合。它底层其实是一个value为null的hash表,所以添加,删除,查找的复杂度都是O(1)。一个算法,随着数据的增加,执行时间的长短,如果是O(1),数据增加,查找数据的时间不变.使用场景也是比较单一的,就是用在一些去重的场景里,例如每个用户只能参与一次活动、一个用户只能中奖一次等等去重场景。
2.3.1 Set的数据结构
Set数据结构是dict字典,字典是用哈希表实现的。
Java中HashSet的内部实现使用的是HashMap,只不过所有的value都指向同一个对象。Redis的set结构也是一样,它的内部也使用hash结构,所有的value都指向同一个内部值。
2.3.2 Set常用的指令
sadd <key><value1><value2> ..... 将一个或多个 member 元素加入到集合 key 中,已经存在的 member 元素将被忽略
public Long sAdd(String key, String... values) {
return redisTemplate.opsForSet().add(key, values);
}
smembers <key> 取出该集合的所有值。
public Set<Object> setMembers(String key) {
return redisTemplate.opsForSet().members(key);
}
sismember <key><value> 判断集合<key>是否为含有该<value>值,有1,没有0
public Boolean sIsMember(String key, Object value) {
return redisTemplate.opsForSet().isMember(key, value);
}
scard<key> 返回该集合的元素个数。
public Long sSize(String key) {
return redisTemplate.opsForSet().size(key);
}
srem <key><value1><value2> .... 删除集合中的某个元素。
public Long sRemove(String key, Object... values) {
return redisTemplate.opsForSet().remove(key, values);
}
spop <key> 随机从该集合中吐出一个值。
public Object sPop(String key) {
return redisTemplate.opsForSet().pop(key);
}
srandmember <key><n> 随机从该集合中取出n个值。不会从集合中删除 。
public List<Object>sRandomMembers(String key, long count) {
return redisTemplate.opsForSet().randomMembers(key, count);
}
smove <source><destination>value 把集合中一个值从一个集合移动到另一个集合
public Boolean sMove(String key, String value, String destKey) {
return redisTemplate.opsForSet().move(key, value, destKey);
}
sinter <key1><key2> 返回两个集合的交集元素。
public Set<Object> sIntersect(String key, String otherKey) {
return redisTemplate.opsForSet().intersect(key, otherKey);
}
sunion <key1><key2> 返回两个集合的并集元素。
public Set<Object> sUnion(String key, String otherKeys) {
return redisTemplate.opsForSet().union(key, otherKeys);
}
sdiff <key1><key2> 返回两个集合的差集元素(key1中的,不包含key2中的)
public Set<Object> sDifference(String key, String otherKey) {
return redisTemplate.opsForSet().difference(key, otherKey);
}
2.4 Hash类型
Redis hash 是一个键值对集合。Redis hash是一个string类型的field和value的映射表,hash特别适合用于存储对象。类似Java里面的Map<String,Object>用户ID为查找的key,存储的value用户对象包含姓名,年龄,生日等信息,如果用普通的key/value结构来存储
主要有以下2种存储方式:
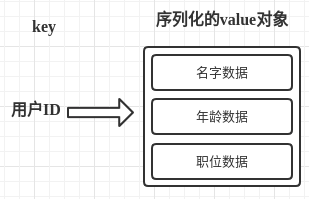
第一种方式将用户ID作为查找key,把其他信息封装成一个对象以序列化的方式存储,这种方式的缺点是,增加了序列化/反序列化的开销,并且在需要修改其中一项信息时,需要把整个对象取回,并且修改操作需要对并发进行保护,引入CAS等复杂问题。
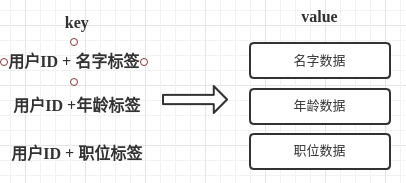
第二种方法是这个用户信息对象有多少成员就存成多少个key-value对儿,用用户ID+对应属性的名称作为唯一标识来取得对应属性的值,虽然省去了序列化开销和并发问题,但是用户ID为重复存储,如果存在大量这样的数据,内存浪费还是非常吓人的。
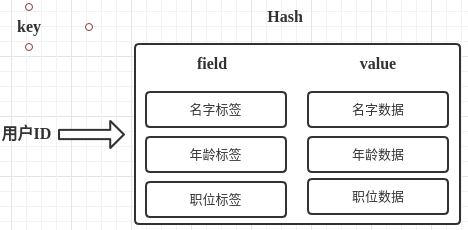
那么Redis提供的Hash很好的解决了这个问题,Redis的Hash实际是内部存储的Value为一个HashMap,并提供了直接存取这个Map成员的接口,通过key(用户ID) + field(属性标签) 就可以操作对应属性数据了,既不需要重复存储数据,也不会带来序列化和并发修改控制的问题,如下图:
常用使用场景
(1)保存结构体信息
hash字典类型也是比较适合保存结构体信息的,不同于字符串一次序列化整个对象,hash可以对用户结构中的每个字段单独存储。这样当我们需要获取结构体信息时可以进行部分获取,而不用序列化所有字段,而将整个字符串保存的结构体信息只能一次性全部读取。
2.4.1 Hash的数据结构
Hash类型对应的数据结构是两种:ziplist(压缩列表),hashtable(哈希表)。当field-value长度较短且个数较少时,使用ziplist,否则使用hashtable。
2.4.2 Hash常用的指令
hset <key><field><value> 给<key>集合中的 <field>键赋值<value>
public void hPut(String key, String hashKey, String value) {
redisTemplate.opsForHash().put(key, hashKey, value);
}
hget <key1><field> 从<key1>集合<field>取出 value
public Object hGet(String key, String field) {
return redisTemplate.opsForHash().get(key, field);
}
hmset <key1><field1><value1><field2><value2>... 批量设置hash的值
public void hPutAll(String key, Map<String, String> maps) {
redisTemplate.opsForHash().putAll(key, maps);
}
hexists<key1><field> 查看哈希表 key 中,给定域 field 是否存在。
public boolean hExists(String key, String field) {
return redisTemplate.opsForHash().hasKey(key, field);
}
hkeys <key> 列出该hash集合的所有field
public Set<Object> hKeys(String key) {
return redisTemplate.opsForHash().keys(key);
}
hvals <key> 列出该hash集合的所有value
public List<Object> hValues(String key) {
return redisTemplate.opsForHash().values(key);
}
hincrby <key><field><increment> 为哈希表 key 中的域 field 的值加上增量 1 -1
public Double hIncrByFloat(String key, Object field, double delta) {
return redisTemplate.opsForHash().increment(key, field, delta);
}
hsetnx <key><field><value> 将哈希表 key 中的域 field 的值设置为 value ,当且仅当域 field 不存在 .
public Boolean hPutIfAbsent(String key, String hashKey, String value) {
return redisTemplate.opsForHash().putIfAbsent(key, hashKey, value);
}
2.5 Zset类型
Redis有序集合zset与普通集合set非常相似,是一个没有重复元素的字符串集合。不同之处是有序集合的每个成员都关联了一个评分(score),这个评分(score)被用来按照从最低分到最高分的方式排序集合中的成员。集合的成员是唯一的,但是评分可以是重复了 。
因为元素是有序的, 所以你也可以很快的根据评分(score)或者次序(position)来获取一个范围的元素。访问有序集合的中间元素也是非常快的,因此你能够使用有序集合作为一个没有重复成员的智能列表。
常用使用场景
(1)各类热门排序场景
例如热门歌曲榜单列表,value值是歌曲ID,score是播放次数,这样就可以对歌曲列表按播放次数进行排序。
当然还有类似微博粉丝列表、评论列表等等,可以将value定义为用户ID、评论ID,score定义为关注时间、评论点赞次数等等。
2.5.1 Zset的数据结构
SortedSet(zset)是Redis提供的一个非常特别的数据结构,一方面它等价于Java的数据结构Map<String, Double>,可以给每一个元素value赋予一个权重score,另一方面它又类似于TreeSet,内部的元素会按照权重score进行排序,可以得到每个元素的名次,还可以通过score的范围来获取元素的列表。
zset底层使用了两个数据结构
(1)hash,hash的作用就是关联元素value和权重score,保障元素value的唯一性,可以通过元素value找到相应的score值。
(2)跳跃表,跳跃表的目的在于给元素value排序,根据score的范围获取元素列表。
2.5.2 Zset常用的指令
zadd <key><score1><value1><score2><value2>… 将一个或多个 member 元素及其 score 值加入到有序集 key 当中。
public Boolean zAdd(String key, String value, double score) {
return redisTemplate.opsForZSet().add(key, value, score);
}
public Long zAdd(String key, Set<TypedTuple<Object>> values) {
return redisTemplate.opsForZSet().add(key, values);
}
zrange <key><start><stop> [WITHSCORES] 返回有序集 key 中,下标在<start><stop>之间的元素 带WITHSCORES,可以让分数一起和值返回到结果集。
public Set<TypedTuple<Object>> zRangeWithScores(String key, long start,long end) {
return redisTemplate.opsForZSet().rangeWithScores(key, start, end);
}
zrangebyscore key min max [withscores] [limit offset count] 返回有序集 key 中,所有 score 值介于 min 和 max 之间(包括等于 min 或 max )的成员。有序集成员按 score 值递增(从小到大)次序排列。
public Set<TypedTuple<Object>> zRangeByScoreWithScores(String key,double min, double max, long start, long end) {
return redisTemplate.opsForZSet().rangeByScoreWithScores(key, min, max,start, end);
}
zrevrangebyscore key max min [withscores] [limit offset count] 同上,改为从大到小排列。
public Set<TypedTuple<Object>> zReverseRangeWithScores(String key,long start, long end) {
return redisTemplate.opsForZSet().reverseRangeWithScores(key, start,end);
}
zincrby <key><increment><value> 为元素的score加上增量
public Double zIncrementScore(String key, String value, double delta) {
return redisTemplate.opsForZSet().incrementScore(key, value, delta);
}
zrem <key><value> 删除该集合下,指定值的元素
public Long zRemove(String key, Object... values) {
return redisTemplate.opsForZSet().remove(key, values);
}
zcount <key><min><max> 统计该集合,分数区间内的元素个数
public Long zCount(String key, double min, double max) {
return redisTemplate.opsForZSet().count(key, min, max);
}
zrank <key><value> 返回该值在集合中的排名,从0开始。
public Long zReverseRank(String key, Object value) {
return redisTemplate.opsForZSet().reverseRank(key, value);
}
全部redis指令可查看:http://www.redis.cn/commands.html
Redis(二) 数据类型操作指令以及对应的RedisTemplate方法的更多相关文章
- Redis的数据类型操作(二)
1.String:key-value(做缓存) Redis中所有的数据都是字符串.命令不区分大小写,key是区分大小写的.Redis是单线程的.Redis中不适合保存内容大的数据. get.set.i ...
- redis的数据类型和指令
1.全局key操作: 测试指令: 全局key操作命令:忽略与key关联的value的类型 删 flushdb 清空当前选择的数据库 del mykey mykey2 删除了两个 Keys 改 move ...
- Redis hash数据类型操作
Redis hash是一个string类型的field和value的映射表.一个key可对应多个field,一个field对应一个value.将一个对象存储 为hash类型,较于每个字段都存储成str ...
- Redis的数据类型及其常用命令
快速入门Redis 首先安装redis: windows下安装redis Linux下安装redis 1. 什么是redis Redis属于nosql(非关系型数据库) 关系型数据库是基于关系表的数据 ...
- Redis 学习(二) —— 数据类型及操作
Redis支持string.list.set.zset.hash等数据类型,这一篇学习redis的数据类型.命令及某些使用场景. 一.String,字符串 字符串是 Redis 最基本的数据类型.一个 ...
- Redis系列(二):Redis的数据类型及命令操作
原文链接(转载请注明出处):Redis系列(二):Redis的数据类型及命令操作 Redis 中常用命令 Redis 官方的文档是英文版的,当然网上也有大量的中文翻译版,例如:Redis 命令参考.这 ...
- redis 从0到1 linux下的安装使用 数据类型 以及操作指令 一
安装 redis 到 /usr/目录下 我这里安装的是redis-3.2.9.tar.gz tar zxvf redis-3.2.9.tar.gz -C /usr 然后进行 执行编译命令 mak ...
- Redis数据类型Strings、Lists常用操作指令
Redis数据类型Strings.Lists常用操作指令 Strings常用操作指令 GET.SET相关操作 # GET 获取键值对 127.0.0.1:6379> get name (nil) ...
- Redis数据类型:Hashes、Geo操作指令
Redis数据类型:Hashes.Geo操作指令 Hashes常用操作指令 Redis Hashes是一个键值对的映射表,最对能存储2^32-1(约40亿)个键值对. HSET HGET HSET:将 ...
随机推荐
- Standalone模式下,通过Systemd管理Flink1.11.1的启停及异常退出
Flink以Standalone模式运行时,可能会发生jobmanager(以下简称jm)或taskmanager(以下简称tm)异常退出的情况,我们可以使用Linux自带的Systemd方式管理jm ...
- 1-web 服务器 框架。
1.静态网页与动态网页 1.静态网页:无法与服务器进行交互的网页. 2.动态网页:能够与服务器进行交互的网页. 2.web与服务器 1.web:网页(HTML,CSS,JS) 2.服务器:能够给用户提 ...
- 多维数据处理之主成分分析(PCA)
在灵巧手与假手理论中,为了研究人手的运动协同关系,需要采集各个关节的运动学量或者多个采集点的肌电信号,然而由于人手关节数目或者EMG采集点数量较多,加上多次采样,导致需要过多的数据需要处理.然而事实上 ...
- Oracle 数据库裸设备扩容处理
前段时间,我管理的一台Oracle数据库表空间容量不足了,由于本人以前没有接触过Oracle的使用所以,就自己查资料来研究如何扩容,网上的文档多数都是在物理机上扩容,而偏偏我的数据文件是存储在裸设备上 ...
- hdu4915 判断括号匹配
题意: 问你括号匹配是否唯一,三种字符'(','?',')',问号可以变成任何字符. 思路: 首先我们要学会判断当前串是否成立?怎么判断?我的方法是跑两遍,开三个变变量 s1 ...
- Windows核心编程 第七章 线程的调度、优先级和亲缘性(上)
第7章 线程的调度.优先级和亲缘性 抢占式操作系统必须使用某种算法来确定哪些线程应该在何时调度和运行多长时间.本章将要介绍Microsoft Windows 98和Windows 2000使用的一些算 ...
- 在AWS Glue中使用Apache Hudi
1. Glue与Hudi简介 AWS Glue AWS Glue是Amazon Web Services(AWS)云平台推出的一款无服务器(Serverless)的大数据分析服务.对于不了解该产品的读 ...
- SSM框架MavenWeb项目的测试
由于SSM项目的类都是由Spring容器托管,所以直接进行用new对象调用方法进行测试是不行不通的,会出现空指针异常NullPointExpection. 因为我们的对象由spring进行托管,调用的 ...
- Xshell6连Linux
一.安装 文件 链接: 提取码:8rmr 二.连Linux 名称填自己喜欢的.续之前,我们保持一样的名字.主机填IP,根据之前Linux填的静态IP去连接. 然后双击,连接 我们用最高权限,填root ...
- ubuntu中执行可执行文件时报错“没有那个文件或目录”的解决办法(非权限问题)
问题:可执行文件明明存在,也有可执行权限(x),但执行时就提示"没有那个文件或目录". 原因:这个程序的是32位的程序(比如arm-linux-gcc),而系统是64位的,运行时需 ...