大数据学习day28-----hive03------1. null值处理,子串,拼接,类型转换 2.行转列,列转行 3. 窗口函数(over,lead,lag等函数) 4.rank(行号函数)5. json解析函数 6.jdbc连接hive,企业级调优
1. null值处理,子串,拼接,类型转换
(1) 空字段赋值(null值处理)
当表中的某个字段为null时,比如奖金,当你要统计一个人的总工资时,字段为null的值就无法处理,这个时候就可以使用NVL函数
NVL:给值为NULL的数据赋值,它的格式是NVL( string1, replace_with)。它的功能是如果string1为NULL,则NVL函数返回replace_with的值,否则返回string1的值,如果两个参数都为NULL ,则返回NULL。
例:
创建dept表,并导入数据
create external table if not exists dept(
deptno int,
dname string,
loc int -------位置
)
row format delimited fields terminated by '\t';
load data local inpath "/root/hive/dept.txt" into table dept;
创建emp表,并导入数据
create external table if not exists emp(
empno int,
ename string,
job string,
mgr int, -------领导
hiredate string,
sal double,
comm double, ------奖金
deptno int)
row format delimited fields terminated by '\t';
load data local inpath '/hive/emp.txt' into table emp;
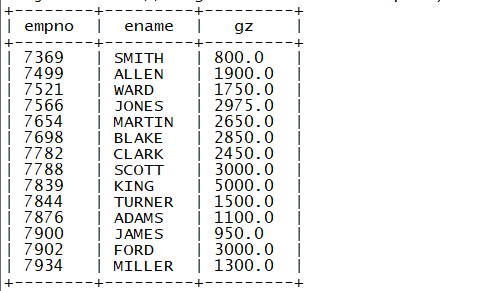
需求:统计员工的总工资
select empno ,ename ,(sal+nvl(comm,0)) gz from emp ;
结果
(2)substr(字段 , 起始位置1 , 长度) , substr(字段 , -n) 从后面开始获取n个字符的字符串
(3)cast() 数据类型转换
2. 行转换,列转换
2.1 行转列
(1)
collect_set(name) 将多行字段的值收集成数组 去重
collect_list(字段) 将多行的字段收集成数组 不去重
范围:全局范围的收集(若加上group by,则是组内收集)
(2)concat_ws 参数一 拼接符 参数二 集合 :将集合中的数据按参数一拼接
(3)concat 参数.... 多个元素直接拼接 :
concat(dname , "," , gender) ---这样拼接麻烦
案例: 数据:
创建表并导入数据
create table teacher(
name string ,
dname string ,
gender string
)
row format delimited fields terminated by "\t" ; load data local inpath "/hive/teacher.txt" into table teacher ;
需求:求每个部门的各种性别的人的(人名)列表
错误的写法:
select
dname,gender,
name -----此处一列会有多个name,这样必然会报错,此处要么写grou by的key或是聚合函数,如count
from
teacher
group by dname,gender ;
正确的写法:
select
dname,gender,
collect_set(name)
from
teacher
group by dname,gender ;
得到的结果

优化,将dname,gender合成一列
select
base_data ,
collect_set(name) -- 组内将name字段收集成一个数组
from
(select
name ,
concat(dname , "," , gender) base_data
from
teacher)t1
group by base_data;
结果(这种形式更加直观)

2.2 列转行
数据:

建表并导入数据
create table movie(
name string ,
category array<string>
)
row format delimited fields terminated by "\t"
collection items terminated by "," ; load data local inpath "/root/hive/movie.txt" into table movie ;
表格如下

2.2.1 函数说明
(1)EXPLODE(col):将hive一列中复杂的array或者map结构拆分成多行。 [爆炸, 炸裂]
select explode(category) from movie ;
结果

(2)Lateral View
lateralView: LATERAL VIEW udtf(expression) tableAlias AS columnAlias (',' columnAlias)*
注意:tableAlias表示虚拟表的别名,columnAlias(列的别名)对应这个虚拟表(一列)
hive官方描述
Lateral view is used in conjunction with user-defined table generating functions such as explode(). As mentioned in Built-in Table-Generating Functions, a UDTF generates zero or more output rows for each input row. A lateral view first applies the UDTF to each row of base table and then joins resulting output rows to the input rows to form a virtual table having the supplied table alias.
翻译:
Lateral view与用户定义的表生成函数(如explode())一起使用。正如在内置的表生成函数中提到的,UDTF为每个输入行生成零个或多个输出行。Lateral view首先将UDTF应用于基表的每一行,然后将产生的输出行连接到输入行,形成一个具有表别名的虚拟表。
例
select name,ty
from
movie
lateral view explode(category) temp_table as ty ;
结果

此处不能如下(个人理解:temp_table为表,所以不能select)
select
name,
temp_table
from
movie
lateral view explode(category) temp_table ;
此处若换成如下命令:
select
name
from
movie
lateral view explode(category) temp_table ;
结果如下

可见Lateral view可将产生的输出行连接到输入行
3. 窗口函数(over( ))
我们都知道在sql中有一类函数叫做聚合函数,例如sum()、avg、max()等等,这类函数可以将多行数据按照规则聚集为一行,一般来讲聚集后的行数是要少于聚集前的行数的。但是有时我们想要既显示聚集前的数据,又要显示聚集后的数据,这时我们便引入了窗口函数(*).
在深入研究Over字句之前,一定要注意:在sql处理中,窗口函数都是最后一步执行,而且仅位于Order by字句之前。
此处以练习0为例 解释上面打“*”号的这句话
该例中若想获取聚集前的数据(name,createtime,cost),聚集后的数据(此处以count(*)为例),当使用以下sql语句查询聚集前后的数据时
SELECT
name,createtime,cost,
count(*)
FROM
orders
会报错(count后只有一条结果,其不是逐行运算的,与聚合前的数据不能放在一起)

但就是想要得到聚合前后的数据该怎么办呢========>窗口函数,如下
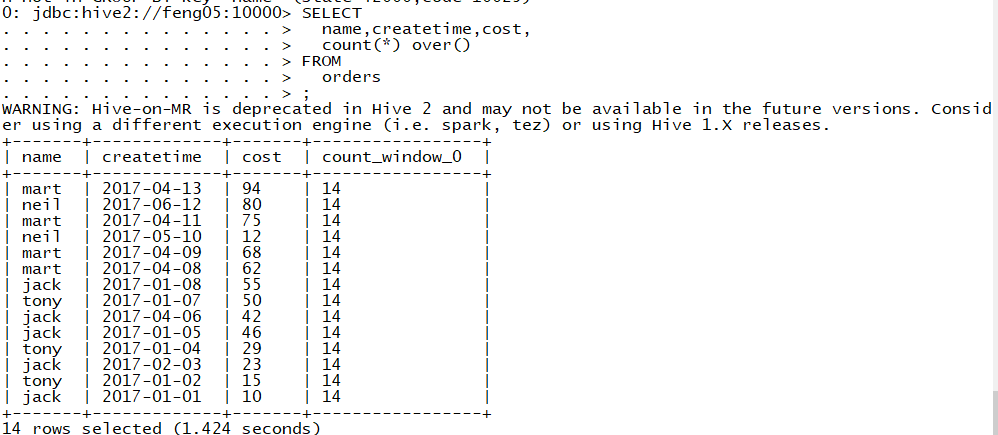
此处的over()可以指定count(*)工作的数据窗口大小,如下sql语句
SELECT
name,createtime,cost,
count(*) over(partition by name) //此处的over()指定count()函数工作的数据窗口大小为同一个人的数据
FROM
orders
运行结果

3.1 相关函数的说明
over():窗口函数,指定分析函数、聚合函数等工作的数据窗口大小,这个数据窗口大小可能会随着行的变化而变化(若直接over(),则是分析函数执行前,表格的行数) CURRENT ROW:当前行 current row n PRECEDING:往前n行数据 n preceding n FOLLOWING:往后n行数据 n following UNBOUNDED:起点,UNBOUNDED PRECEDING 表示从前面的起点, UNBOUNDED FOLLOWING表示到后面的终点 unbound preceding unbound following
LAG(col, n):相对某运算的行,往前第n行数据 lag 参数一 字段 n --------见练习(4)
LEAD(col,n):相对某运算的行,往后第n行数据 lead------------见练习(4)
NTILE(n):把有序分区中的行分发到指定数据的组中,各个组有编号,编号从1开始,对于每一行,NTILE返回此行所属的组的编号。注意:n必须为int类型。 ntile(5) ----见练习(5)

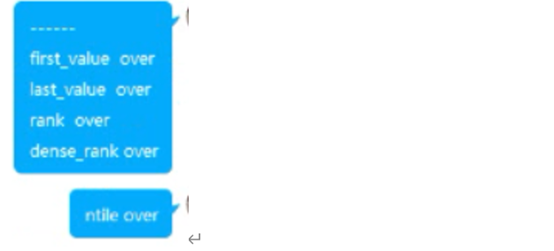
3.2 案例和练习
案例:以1中的emp,dept表为例(over()函数)
此时count(*) over()计算的表格为第一个count()执行后得到的数据

当去掉count(*)后,此时,count(*) over()计算的数据为原始数据,得到的结果如下

练习0:
数据如下
建表并导入数据
create table orders(
name string ,
createtime string ,
cost double
)
row format delimited fields terminated by "," ;
load data local inpath "/root/hive/orders.txt" into table orders ;
得到如下表

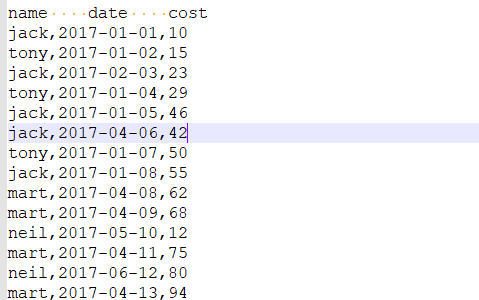
(1)查询在2017年4月份购买过的顾客即总人数
第一步
select
name ,
createtime
from
orders
group by name , createtime
having substr(createtime ,1 , 7) = "2017-04" ;
结果

第二步
select
name ,
count(*) ,
count(*) over() tatol_num
from
(select
name ,
createtime
from
orders
group by name , createtime
having substr(createtime ,1 , 7) = "2017-04")t
group by name ;
结果

第三步(最终结果)
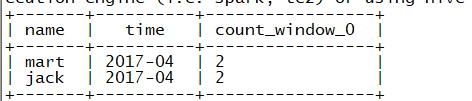
(2)查询顾客的购买明细及月购买总额
select
name ,
createtime,
cost ,
sum(cost) over(partition by name, month(createtime))
from
orders ;
结果
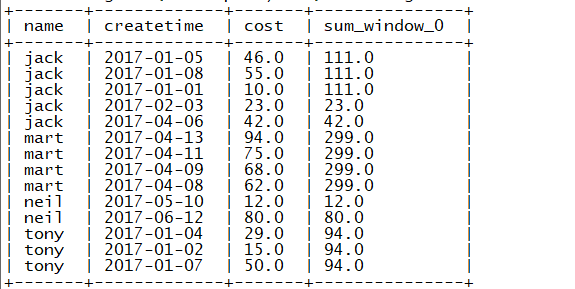
(3)上述的场景,要将cost按照日期进行累加
select
name ,
createtime,
cost ,
sum(cost) over(partition by name) month_total,
sum(cost) over(partition by name order by createtime ) --每个人按时间累加
from
orders ;
结果
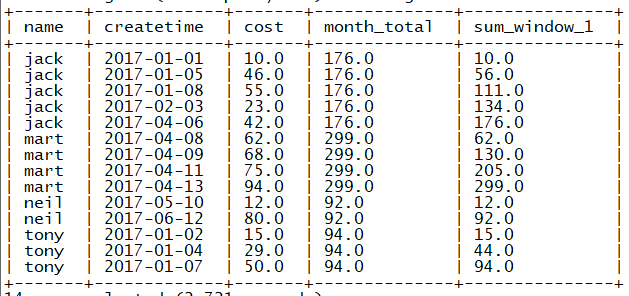
(4)查询顾客上次的购买时间(使用lag)
select
* ,
lag(createtime ,1 , "首次购买") over(partition by name order by createtime) ,
lead(createtime ,1) over(partition by name order by createtime)
from
orders ;
结果
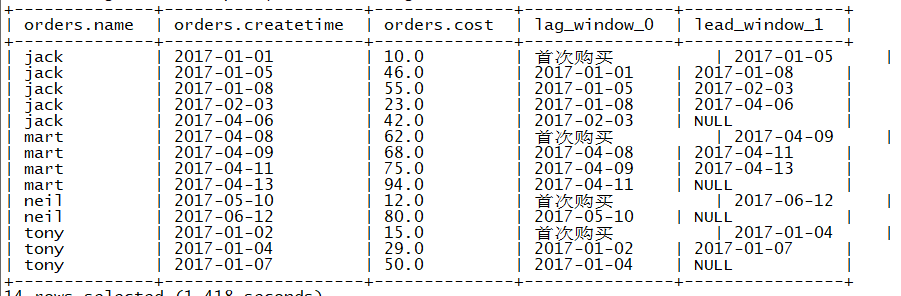
(5)查询前20%时间的订单信息(使用lead)
select
*
from
(select
* ,
ntile(5) over(order by createtime) n
from
orders)t
where n = 1
;
结果
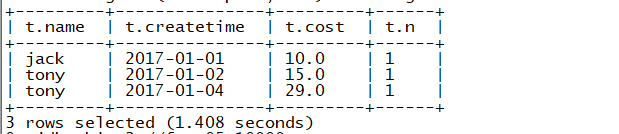
4.rank(行号函数)
4.1 函数说明
RANK() 排序相同时会重复,总数不会变
DENSE_RANK() 排序相同时会重复,总数会减少
ROW_NUMBER() 会根据顺序计算--------见练习
案例
数据

需求:计算每门学科的成绩排名
创建表并导入数据
create table stu(
name string ,
subject string ,
score int
)
row format delimited fields terminated by "\t" ;
load data local inpath "/root/hive/stu.txt" into table stu ;
得到如下表

sql语句
select
* ,
rank() over(partition by subject order by score desc) , -- 总数量不变
dense_rank() over(partition by subject order by score desc) -- 总数减少
from
stu ;
结果
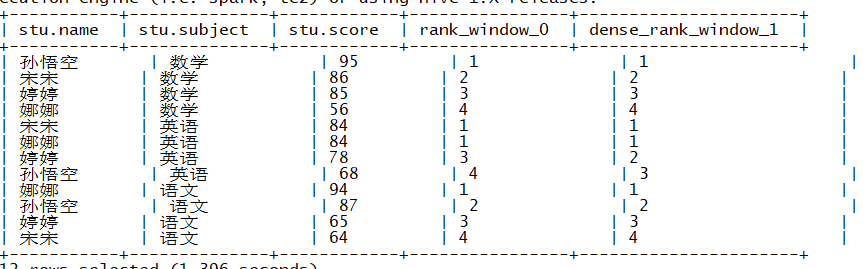
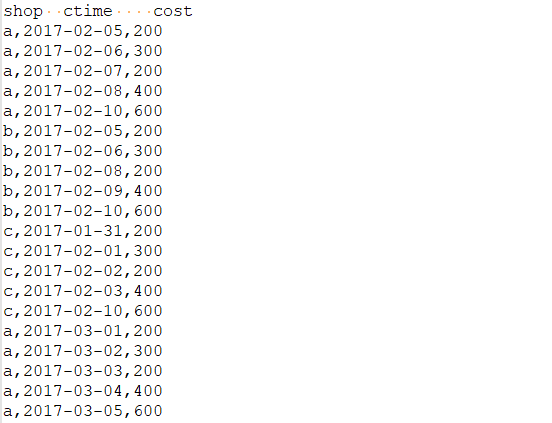
练习1
数据如下,求有连续4天销售记录的店铺
第一步:使用row_number()求出各店铺所有销售数
select
*,
row_number() over(partition by name order by ctime)
from
shop ;
结果
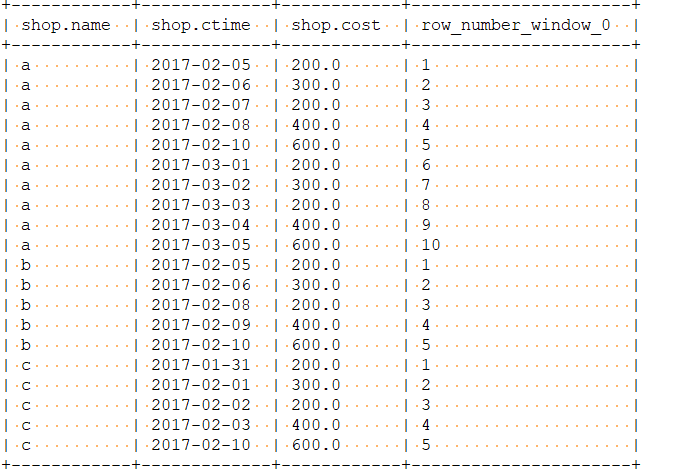
第二步:使用date_sub函数,并统计差值相同值的个数(此处统计差值大于4)
select
name ,
diff,
count(*) cc
from
(select
*,
date_sub(ctime , n) diff
from
(select
*,
row_number() over(partition by name order by ctime) n
from
shop)t1)t2
group by name , diff having cc >=4 ;
结果
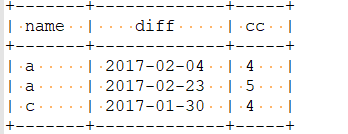
第三步:最终结果
select
distinct name
from
(select
name ,
diff,
count(*) cc
from
(select
*,
date_sub(ctime , n) diff
from
(select
*,
row_number() over(partition by name order by ctime) n
from
shop)t1)t2
group by name , diff having cc >=4)t3 ;
结果

练习2
数据
uid seq m
u01,1,1
u01,2,0
u01,3,1
u01,4,1
u01,5,0
u01,6,1
u02,1,1
u02,2,1
u02,3,0
u02,4,1
u02,5,1
u02,6,0
u02,7,0
u02,8,1
u02,9,1
u03,1,1
u03,2,1
u03,3,1
u03,4,1
u03,5,1
u03,6,0
uid:用户;seq:用户第几次打地鼠;m:是否击中,1表示击中,0没击中
需求:求连续打中地鼠3次的用户
(1)建表并导入数据
create table ds(
uid string ,
seq int ,
m int
)
row format delimited fields terminated by "," ;
load data local inpath "/root/hive/ds.txt" into table ds ;
(2)sql
select
distinct uid
from
(select
uid,diff,
count(*) chit
from
(select
*,
(seq-n) diff
from
(select
*,
row_number() over(partition by uid order by seq) n
from
ds
where m = 1) t1)t2
group by
uid,diff
having chit>=3)t3;
结果

5. json解析函数:表生成函数(json_tuple())
需求:有如下json格式的电影评分数据

求电影的均分
(1)创建表并导入数据
create table json(
content string
);
load data local inpath "/root/hive/rating.json" into table json ;
(2)通过表生成函数,解析json得到另一张表
create table mm as
select
json_tuple(content , "movie" , "rate","timeStamp","uid") as (mid ,rate ,times ,uid)
from
json ;
结果

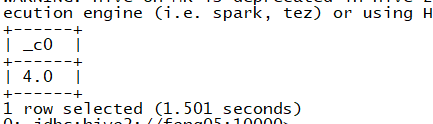
(3)sql
select avg(rate) from mm where uid =1 ;
结果
6.jdbc连接hive,企业级调优
见hive文档
大数据学习day28-----hive03------1. null值处理,子串,拼接,类型转换 2.行转列,列转行 3. 窗口函数(over,lead,lag等函数) 4.rank(行号函数)5. json解析函数 6.jdbc连接hive,企业级调优的更多相关文章
- 大数据技术之_08_Hive学习_04_压缩和存储(Hive高级)+ 企业级调优(Hive优化)
第8章 压缩和存储(Hive高级)8.1 Hadoop源码编译支持Snappy压缩8.1.1 资源准备8.1.2 jar包安装8.1.3 编译源码8.2 Hadoop压缩配置8.2.1 MR支持的压缩 ...
- 大数据学习day26----hive01----1hive的简介 2 hive的安装(hive的两种连接方式,后台启动,标准输出,错误输出)3. 数据库的基本操作 4. 建表(内部表和外部表的创建以及应用场景,数据导入,学生、分数sql练习)5.分区表 6加载数据的方式
1. hive的简介(具体见文档) Hive是分析处理结构化数据的工具 本质:将hive sql转化成MapReduce程序或者spark程序 Hive处理的数据一般存储在HDFS上,其分析数据底 ...
- Hive参数与性能企业级调优
Hive作为大数据平台举足轻重的框架,以其稳定性和简单易用性也成为当前构建企业级数据仓库时使用最多的框架之一. 但是如果我们只局限于会使用Hive,而不考虑性能问题,就难搭建出一个完美的数仓,所以Hi ...
- 大数据学习系列之五 ----- Hive整合HBase图文详解
引言 在上一篇 大数据学习系列之四 ----- Hadoop+Hive环境搭建图文详解(单机) 和之前的大数据学习系列之二 ----- HBase环境搭建(单机) 中成功搭建了Hive和HBase的环 ...
- 大数据学习系列之四 ----- Hadoop+Hive环境搭建图文详解(单机)
引言 在大数据学习系列之一 ----- Hadoop环境搭建(单机) 成功的搭建了Hadoop的环境,在大数据学习系列之二 ----- HBase环境搭建(单机)成功搭建了HBase的环境以及相关使用 ...
- 大数据学习系列之七 ----- Hadoop+Spark+Zookeeper+HBase+Hive集群搭建 图文详解
引言 在之前的大数据学习系列中,搭建了Hadoop+Spark+HBase+Hive 环境以及一些测试.其实要说的话,我开始学习大数据的时候,搭建的就是集群,并不是单机模式和伪分布式.至于为什么先写单 ...
- 大数据学习系列之九---- Hive整合Spark和HBase以及相关测试
前言 在之前的大数据学习系列之七 ----- Hadoop+Spark+Zookeeper+HBase+Hive集群搭建 中介绍了集群的环境搭建,但是在使用hive进行数据查询的时候会非常的慢,因为h ...
- 通过JDBC连接hive
hive是大数据技术簇中进行数据仓库应用的基础组件,是其它类似数据仓库应用的对比基准.基础的数据操作我们可以通过脚本方式以hive-client进行处理.若需要开发应用程序,则需要使用hive的jdb ...
- 大数据学习(16)—— HBase环境搭建和基本操作
部署规划 HBase全称叫Hadoop Database,它的数据存储在HDFS上.我们的实验环境依然基于上个主题Hive的配置,参考大数据学习(11)-- Hive元数据服务模式搭建. 在此基础上, ...
随机推荐
- JAVA笔记15__TCP服务端、客户端程序 / ECHO程序 /
/** * TCP:传输控制协议,采用三方握手的方式,保证准确的连接操作. * UDP:数据报协议,发送数据报,例如:手机短信或者是QQ消息. */ /** * TCP服务器端程序 */ public ...
- js实现日期格式化封装-八种格式
封装一个momentTime.js文件,包含8种格式. 需要传两个参数: 时间戳:stamp 格式化的类型:type, 日期补零的方法用到es6语法中的padStart(length,'字符'): 第 ...
- html5的Message信息提示框
1.定义dialog <dialog id="showDialog"> <div>您没有权限访问本页面!</div> </dialog&g ...
- Tomcat 内存马(一)Listener型
一.Tomcat介绍 Tomcat的主要功能 tomcat作为一个 Web 服务器,实现了两个非常核心的功能: Http 服务器功能:进行 Socket 通信(基于 TCP/IP),解析 HTTP 报 ...
- 『学了就忘』Linux基础命令 — 33、管道符
目录 1.管道符介绍 2.管道符应用 (1)例子1: (2)例子2: (3)例子3: 1.管道符介绍 管道符|,也是Shell命令. 管道符的作用是链接多个命令,把命令1的结果作为命令2的操作对象. ...
- Java多线程| 01 | 线程概述
Java多线程| 01 | 线程概述 线程相关概念 进程与线程 进程:进程(Process)是计算机中的程序关于某数据集合上的一次运行活动,是操作系统进行资源分配与调度的基本单位.可以把进程简单的理解 ...
- 到底谁才需要Service Mesh?
本文是Service Mesh系列第1篇 随着云原生时代的来临,使用微服务架构的朋友们开始听到一个新的技术名词--Service Mesh(现在来说已经不算新了). 对于一项新技术的学习,总归绕不过两 ...
- 体验.NET Core使用IKVM对接Java
前言 与第三方对接最麻烦的是语言不同,因语言不同内置实现相关标准加密算法还是略微有所差异,对接单点登录场景再寻常不过,由于时间紧迫且对接方使用Java,所以留给我对接开发和联调的时间本就不多,于是乎, ...
- robotframework-autoitlibrary离线安装
由于AutoItLibrary需要依赖pywin32库.所以要使用AutoItLibrary必须要先安装好pywin32 1.pywin32下载地址安装:http://sourceforge.net/ ...
- Django 项目配置拆分独立
目录 一.创建配置目录 二.创建基础配置文件 三.创建各个环境的配置 四.调整settings.py 五.程序使用 六.目录结构 Django 项目中,我们默认的配置是都在 settings.py 文 ...