Flume(一)【概述】
一.Flume定义
Flume是Cloudera公司提供的一个高可用、高可靠、分布式的海量日志采集、聚合和传输的系统。Flume基于流式架构,灵活简单。
Flume最主要的作用就是,实时读取服务器的本地磁盘的数据,将数据写入到HDFS。
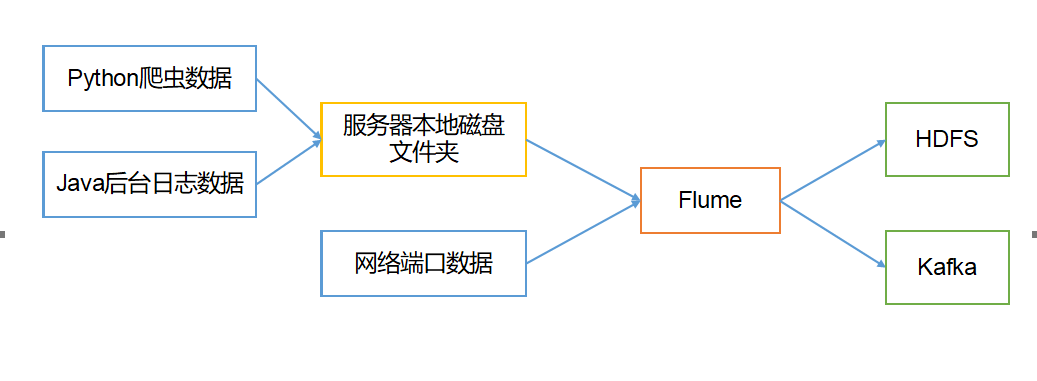
二.Flume基础架构
Flume基本组成架构如下图所示
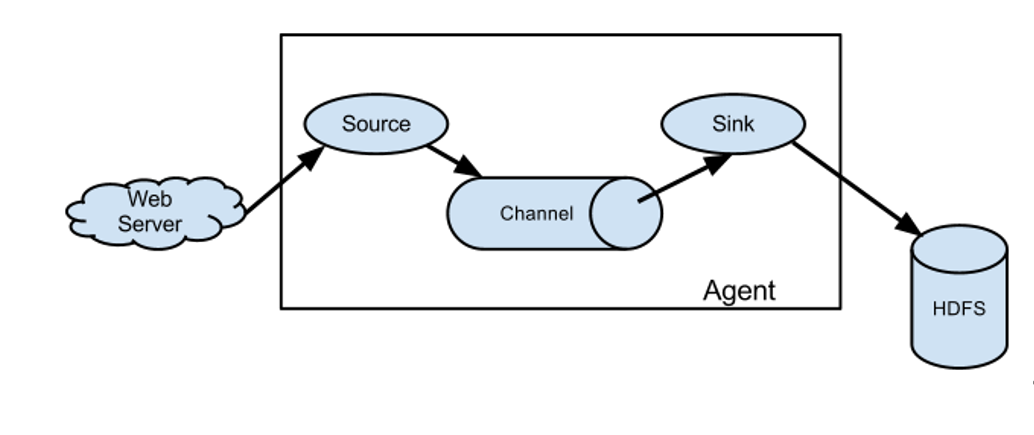
各个组件介绍
1.Agent
Agent是一个JVM进程,它以事件的形式将数据从源头送至目的。
Agent主要有3个部分组成:Source、Channel、Sink。
2.Source
Source是负责接收数据到Flume Agent的组件。Source组件可以处理各种类型、各种格式的日志数据,包括avro、thrift、exec、jms、spooling directory、taildir、netcat、sequence generator、syslog、http、legacy。
taildir source 详解
Taildir Source维护了一个json格式的position File,其会定期的往position File中更新每个文件读取到的最新的位置,因此能够实现断点续传。Position File的格式如下:
{"inode":2496272,"pos":12,"file":"/opt/module/flume/files/file1.txt"}
{"inode":2496275,"pos":12,"file":"/opt/module/flume/files/file2.txt"}
注:Linux中储存文件元数据的区域就叫做inode,每个inode都有一个号码,操作系统用inode号码来识别不同的文件,Unix/Linux系统内部不使用文件名,而使用inode号码来识别文件。
3.Sink
Sink不断地轮询Channel中的事件且批量地移除它们,并将这些事件批量写入到存储或索引系统、或者被发送到另一个Flume Agent。
Sink组件目的地包括hdfs、logger、avro、thrift、ipc、file、hbase、solr、自定义。
4.Channel
Channel是位于Source和Sink之间的缓冲区。因此,Channel允许Source和Sink运作在不同的速率上。Channel是线程安全的,可以同时处理几个Source的写入操作和几个Sink的读取操作。
Flume自带两种Channel:Memory Channel和File Channel。
Memory Channel是内存中的队列。Memory Channel在不需要关心数据丢失的情景下适用。如果需要关心数据丢失,那么Memory Channel就不应该使用,因为程序死亡、机器宕机或者重启都会导致数据丢失。
File Channel将所有事件写到磁盘。因此在程序关闭或机器宕机的情况下不会丢失数据。
5.Event
传输单元,Flume数据传输的基本单元,以Event的形式将数据从源头送至目的地。Event由Header和Body两部分组成,Header用来存放该event的一些属性,为K-V结构,Body用来存放该条数据,形式为字节数组。

Flume(一)【概述】的更多相关文章
- 1.1-1.5 flume架构概述及安装使用
一.flume架构概述 1.flume简介 Flume是一种分布式,可靠且可用的服务,用于有效地收集,聚合和移动大量日志数据.它具有基于流数据流的简单灵活的架构.它具有可靠的可靠性机制和许多故障转移和 ...
- Flume 学习笔记之 Flume NG概述及单节点安装
Flume NG概述: Flume NG是一个分布式,高可用,可靠的系统,它能将不同的海量数据收集,移动并存储到一个数据存储系统中.轻量,配置简单,适用于各种日志收集,并支持 Failover和负载均 ...
- Flume的概述和安装部署
一.Flume概述 Flume是一种分布式.可靠且可用的服务,用于有效的收集.聚合和移动大量日志文件数据.Flume具有基于流数据流的简单灵活的框架,具有可靠的可靠性机制和许多故障转移和恢复机制,具有 ...
- Flume(1)-概述与组成架构
一. 定义 Flume是Cloudera提供的一个高可用的,高可靠的,分布式的海量日志采集.聚合和传输的系统.Flume基于流式架构,灵活简单. 二. 优点 1. 可以和任意集中式存储进程集成. 2. ...
- Hadoop学习笔记—19.Flume框架学习
START:Flume是Cloudera提供的一个高可用的.高可靠的开源分布式海量日志收集系统,日志数据可以经过Flume流向需要存储终端目的地.这里的日志是一个统称,泛指文件.操作记录等许多数据. ...
- 日志采集框架Flume以及Flume的安装部署(一个分布式、可靠、和高可用的海量日志采集、聚合和传输的系统)
Flume支持众多的source和sink类型,详细手册可参考官方文档,更多source和sink组件 http://flume.apache.org/FlumeUserGuide.html Flum ...
- 日志采集框架 Flume
日志采集框架 Flume 1 概述 Flume是一个分布式.可靠.和高可用的海量日志采集.聚合和传输的系统. Flume可以采集文件,socket数据包等各种形式源数据,又可以将采集到的数据输出到H ...
- 【Hadoop离线基础总结】日志采集框架Flume
日志采集框架Flume Flume介绍 概述 Flume是一个分布式.可靠.和高可用的海量日志采集.聚合和传输的系统.它可以采集文件,socket数据包.文件.文件夹.kafka等各种形式源数据,又可 ...
- Flume 详解&实战
Flume 1. 概述 Flume是一个高可用,高可靠,分布式的海量日志采集.聚合和传输的系统.Flume基于流式架构,灵活简单. Flume的作用 Flume最主要的作用就是,实时读取服务器本地磁盘 ...
- Hadoop相关笔记
一. Zookeeper( 分布式协调服务框架 ) 1. Zookeeper概述和集群搭建: (1) Zookeeper概述: Zookeeper 是一个分布式 ...
随机推荐
- (转)Linux中的文件描述符与打开文件之间的关系
转:http://blog.csdn.net/cywosp/article/details/38965239 1. 概述 在Linux系统中一切皆可以看成是文件,文件又可分为:普通文件.目录文 ...
- hdu 5090 Game with Pearls (额,, 想法题吧 / 二分图最大匹配也可做)
题意: 给你N个数,a1,,,,an.代表第i个管子里有ai个珍珠. 规定只能往每根管里增加k的倍数个珍珠. 如果存在一套操作,操作完毕后可以得到1~N的一个排列,则Jerry赢,否则Tom赢. 问谁 ...
- 使用google zxing生成二维码图片
生成二维码工具类: 1 import java.awt.geom.AffineTransform; 2 import java.awt.image.AffineTransformOp; 3 impor ...
- 执行新程序 execve()
新程序的执行 一:execve() 之所以叫新程序的执行,原因是这部分内容一般发生在fork()和vfork()之后,在子进程中通过系统调用execve()可以将新程序加载到子进程的内存空间.这个操作 ...
- MySQL到底能否解决幻读问题
先说结论,MySQL 存储引擎 InnoDB 在可重复读(RR)隔离级别下是解决了幻读问题的. 方法:是通过next-key lock在当前读事务开启时,1.给涉及到的行加写锁(行锁)防止写操作:2. ...
- LeetCode 重排链表 OPPO笔试
重排链表 几个关键点: 1. 双指针(快慢指针找中点)(用于反转后一部分) 2. 反转后一部分 (reverse函数) 3. 合并链表 合并的时候在笔试的时候想了一种比我之前想的简单的方法 从slow ...
- node.js中模块和包
node.js中模块和包 什么是模块 如何创建并加载模块 1. 创建模块 2. 单次加载 3. 覆盖 exports 如何创建一个包 1. 作为文件夹的模块 2. package.json 如何使用包 ...
- redis数据存储的细节
redis是一个K-V NoSql非关系型数据库,redis有物种数据类型,分别是String,Hash,list,set,zset:这五种类型都是针对K-V中的V设计的. 1.总体介绍:关于redi ...
- 第三天 while循环 及其用法
(1)语法格式:while 条件: ..... 语法二:while 条件: break # 跳出当前循环 语法三:while 条件: else # 当while循环正常结束时执行该语句:只有程 ...
- Android 有意思的脚本(打印温度)
https://github.com/LineageOS/android_hardware_google_pixel/blob/lineage-18.1/thermal/device.mk #!/sy ...