Flume(一)【概述】
一.Flume定义
Flume是Cloudera公司提供的一个高可用、高可靠、分布式的海量日志采集、聚合和传输的系统。Flume基于流式架构,灵活简单。
Flume最主要的作用就是,实时读取服务器的本地磁盘的数据,将数据写入到HDFS。
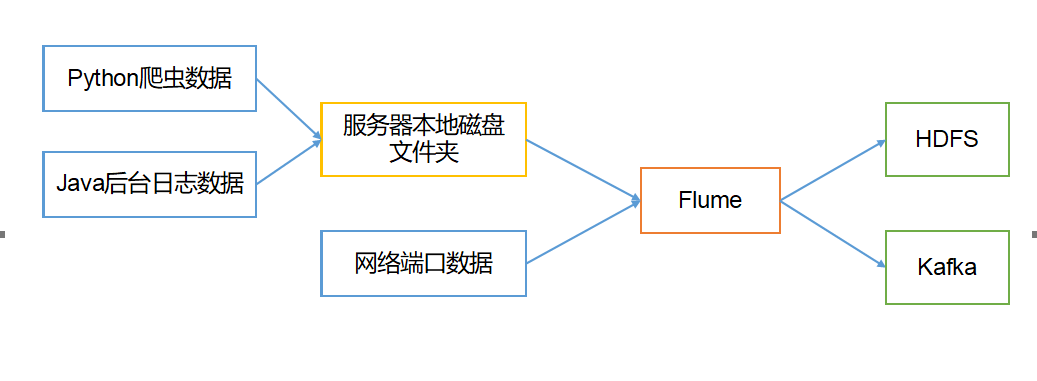
二.Flume基础架构
Flume基本组成架构如下图所示
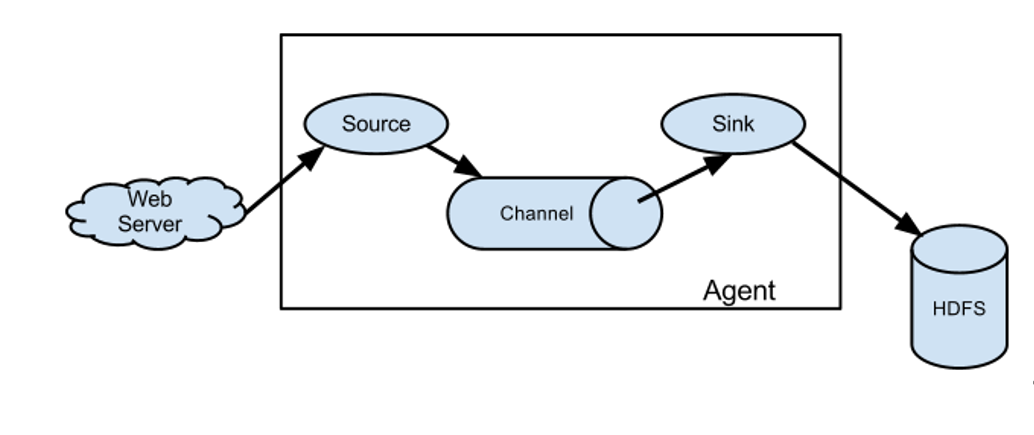
各个组件介绍
1.Agent
Agent是一个JVM进程,它以事件的形式将数据从源头送至目的。
Agent主要有3个部分组成:Source、Channel、Sink。
2.Source
Source是负责接收数据到Flume Agent的组件。Source组件可以处理各种类型、各种格式的日志数据,包括avro、thrift、exec、jms、spooling directory、taildir、netcat、sequence generator、syslog、http、legacy。
taildir source 详解
Taildir Source维护了一个json格式的position File,其会定期的往position File中更新每个文件读取到的最新的位置,因此能够实现断点续传。Position File的格式如下:
{"inode":2496272,"pos":12,"file":"/opt/module/flume/files/file1.txt"}
{"inode":2496275,"pos":12,"file":"/opt/module/flume/files/file2.txt"}
注:Linux中储存文件元数据的区域就叫做inode,每个inode都有一个号码,操作系统用inode号码来识别不同的文件,Unix/Linux系统内部不使用文件名,而使用inode号码来识别文件。
3.Sink
Sink不断地轮询Channel中的事件且批量地移除它们,并将这些事件批量写入到存储或索引系统、或者被发送到另一个Flume Agent。
Sink组件目的地包括hdfs、logger、avro、thrift、ipc、file、hbase、solr、自定义。
4.Channel
Channel是位于Source和Sink之间的缓冲区。因此,Channel允许Source和Sink运作在不同的速率上。Channel是线程安全的,可以同时处理几个Source的写入操作和几个Sink的读取操作。
Flume自带两种Channel:Memory Channel和File Channel。
Memory Channel是内存中的队列。Memory Channel在不需要关心数据丢失的情景下适用。如果需要关心数据丢失,那么Memory Channel就不应该使用,因为程序死亡、机器宕机或者重启都会导致数据丢失。
File Channel将所有事件写到磁盘。因此在程序关闭或机器宕机的情况下不会丢失数据。
5.Event
传输单元,Flume数据传输的基本单元,以Event的形式将数据从源头送至目的地。Event由Header和Body两部分组成,Header用来存放该event的一些属性,为K-V结构,Body用来存放该条数据,形式为字节数组。

Flume(一)【概述】的更多相关文章
- 1.1-1.5 flume架构概述及安装使用
一.flume架构概述 1.flume简介 Flume是一种分布式,可靠且可用的服务,用于有效地收集,聚合和移动大量日志数据.它具有基于流数据流的简单灵活的架构.它具有可靠的可靠性机制和许多故障转移和 ...
- Flume 学习笔记之 Flume NG概述及单节点安装
Flume NG概述: Flume NG是一个分布式,高可用,可靠的系统,它能将不同的海量数据收集,移动并存储到一个数据存储系统中.轻量,配置简单,适用于各种日志收集,并支持 Failover和负载均 ...
- Flume的概述和安装部署
一.Flume概述 Flume是一种分布式.可靠且可用的服务,用于有效的收集.聚合和移动大量日志文件数据.Flume具有基于流数据流的简单灵活的框架,具有可靠的可靠性机制和许多故障转移和恢复机制,具有 ...
- Flume(1)-概述与组成架构
一. 定义 Flume是Cloudera提供的一个高可用的,高可靠的,分布式的海量日志采集.聚合和传输的系统.Flume基于流式架构,灵活简单. 二. 优点 1. 可以和任意集中式存储进程集成. 2. ...
- Hadoop学习笔记—19.Flume框架学习
START:Flume是Cloudera提供的一个高可用的.高可靠的开源分布式海量日志收集系统,日志数据可以经过Flume流向需要存储终端目的地.这里的日志是一个统称,泛指文件.操作记录等许多数据. ...
- 日志采集框架Flume以及Flume的安装部署(一个分布式、可靠、和高可用的海量日志采集、聚合和传输的系统)
Flume支持众多的source和sink类型,详细手册可参考官方文档,更多source和sink组件 http://flume.apache.org/FlumeUserGuide.html Flum ...
- 日志采集框架 Flume
日志采集框架 Flume 1 概述 Flume是一个分布式.可靠.和高可用的海量日志采集.聚合和传输的系统. Flume可以采集文件,socket数据包等各种形式源数据,又可以将采集到的数据输出到H ...
- 【Hadoop离线基础总结】日志采集框架Flume
日志采集框架Flume Flume介绍 概述 Flume是一个分布式.可靠.和高可用的海量日志采集.聚合和传输的系统.它可以采集文件,socket数据包.文件.文件夹.kafka等各种形式源数据,又可 ...
- Flume 详解&实战
Flume 1. 概述 Flume是一个高可用,高可靠,分布式的海量日志采集.聚合和传输的系统.Flume基于流式架构,灵活简单. Flume的作用 Flume最主要的作用就是,实时读取服务器本地磁盘 ...
- Hadoop相关笔记
一. Zookeeper( 分布式协调服务框架 ) 1. Zookeeper概述和集群搭建: (1) Zookeeper概述: Zookeeper 是一个分布式 ...
随机推荐
- Luogu P1084 疫情控制 | 二分答案 贪心
题目链接 观察题目,答案明显具有单调性. 因为如果用$x$小时能够控制疫情,那么用$(x+1)$小时也一定能控制疫情. 由此想到二分答案,将问题转换为判断用$x$小时是否能控制疫情. 对于那些在$x$ ...
- Hdu P1394 Minimum Inversion Number | 权值线段树
题目链接 题目翻译: 约定数字序列a1,a2,...,an的反转数是满足i<j和ai>aj的数对(ai,aj)的数量. 对于给定的数字序列a1,a2,...,an,如果我们将第1到m个数字 ...
- LCA-离线tarjan模板
/* *算法引入: *树上两点的最近公共祖先; *对于有根树的两个结点u,v,最近公共祖先LCA(T,u,v)表示一个结点x,满足x是u,v的祖先且x的深度尽可能大; *对于x来说,从u到v的路径一定 ...
- Linux ps -ef 命令输出解释
UID: 程序拥有者PID:程序的 IDPPID:程序父级程序的 IDC: CPU 使用的百分比STIME: 程序的启动时间TTY: 登录终端TIME : 程序使用掉 CPU 的时间CMD: 下达的 ...
- 阿里云ECI如何6秒扩容3000容器实例?
引言 根据最新CNCF报告,有超过90%的用户在生产环境使用容器,并且有超过80%的用户通过Kubernetes管理容器.是不是我们的生产环境上了K8s就完美解决了应用部署的问题?IT界有句俗语,没有 ...
- 议题解析与复现--《Java内存攻击技术漫谈》(二)无文件落地Agent型内存马
无文件落地Agent型内存马植入 可行性分析 使用jsp写入或者代码执行漏洞,如反序列化等,不需要上传agent Java 动态调试技术原理及实践 - 美团技术团队 (meituan.com) 首先, ...
- CSS 海盗船加载特效
CSS 海盗船加载特效 <!DOCTYPE html> <html lang="en"> <head> <meta charset=
- 使用Adobe Acrobat进行Word转PDF遇到的问题及解决方法
软件版本:Adobe Acrobat 9 Pro 使用场景:Word转PDF 问题1: 我以为先要在Adobe Acrobat 9 Pro中打开Word文件,然后在执行类似转换/导出操作.但是始终无法 ...
- xpath的chrome插件安装,xpath基本语法
xpath插件安装: 注意:提前安装xpath插件 (1)打开chrome浏览器 (2)点击右上角小圆点 (3)更多工具 (4)扩展程序 (5)拖拽xpath插件到扩展程序中 (6)如果crx文件失效 ...
- 痞子衡嵌入式:再测i.MXRT1060,1170上的普通GPIO与高速GPIO极限翻转频率
大家好,我是痞子衡,是正经搞技术的痞子.今天痞子衡给大家介绍的是i.MXRT1060/1170上的普通GPIO与高速GPIO极限翻转频率. 按照上一篇文章 <实测i.MXRT1010上的普通GP ...