Java堆的理解
堆的核心概述
- 所有的对象实例以及数组都应当在运行时分配在堆上
- 从实际实用角度看 --"几乎所有的对象实例都在堆中分配内存"
- 数组和对象可能永远不会存储在栈上,因为栈帧中保存引用,这个引用指向对象或者数组在堆中的位置
- 在方法结束后,堆中的对象不会马上被移除,仅仅在垃圾收集的时候才会被移除
- 堆,是GC执行垃圾回收的重点区域
内存细分

# 1. 堆空间的大小设置
-Xms 用来设置堆空间(年轻代+老年代)的初始内存大小
-X 是jvm的运行参数
ms 是memory start
-Xmx 用来设置堆空间(年轻代+老年代) 的最大内存大小
# 2. 默认堆空间的大小
初始内存大小:物理电脑内存大小/64
最大内存大小:物理电脑内存大小/4
# 3. 手动设置: -Xms600m -Xmx600m
开发中建议将初始堆内存和最大的堆内存设置成相同的值.
- 原因:值不同,当达到堆的初始内存大小后,堆会不断扩容,当空闲时又会释放内存,频繁的扩容与释放会造成不必要的系统压力.
# 4. 查看设置的参数:
方式一:在命令行中jps 查看进程号
jstat -gc 进程id
方式二: 增加参数 -XX:+PrintGCDetails
新生代与老年代
- 存储在JVM中的Java对象可以被划分为两类
- 一类是生命周期较短的瞬时对象,这类对象的创建和消亡都非常迅速
- 另一类对象的生命周期却非常长,在某些极端情况下还能与JVM的生命周期保持一致
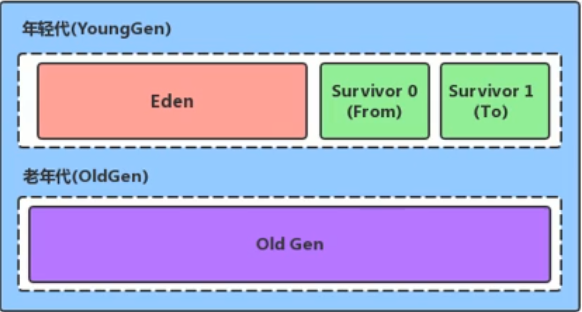
- Java堆区进一步细分的话,可以划分为年轻代(YoungGen)和老年代(OldGen)
- 几乎所有的Java对象都是在Eden区被new出来的.
- 绝大部分的Java对象的销毁都在新生代进行了
- 其中年轻代又可以划分为Eden空间,Survivor0空间和Survivor1空间(有时也叫做from区,to区)
# 新生代与老年代相关参数设置
> 配置新生代与老年代在堆结构的占比
> 默认:-XX:NewRatio=2,表示新生代占1,老年代占2,新生代占整个堆的1/3
>可以修改为:-XX:NewRatio=4,表示新生代占1,老年代占4,新生代占整个堆的1/5
- 如果程序很多对象生命周期比较长,可以考虑将老年代占比调大
> 在HotSpot中,Eden空间和另外两个Survivor空间缺省所占的比例是8:1:1
>可以通过选项 -XX:SurvivorRatio=x 调整这个空间比例
> 但是会有个问题,实际的比例并不足8:1:1,实际是6:1:1
可以通过 -XX:-UseAdaptiveSizePolicy 关闭自适应的内存分配策略(实测无用)
最好还是直接设置-XX:SurvivorRatio=8
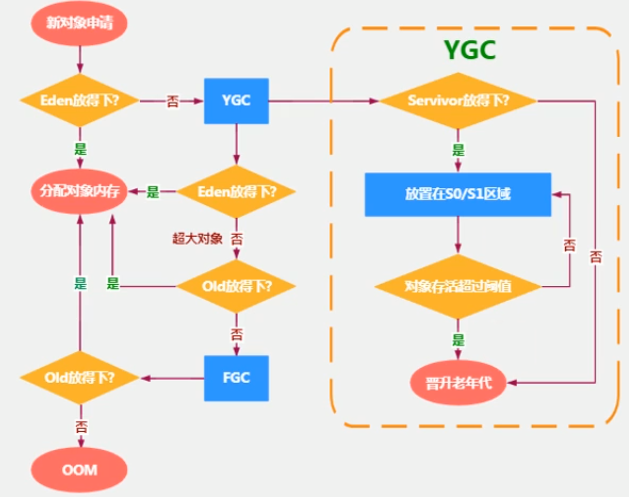
对象分配的一般过程
new的对象先放在伊甸园区,此区有大小限制
当伊甸园的空间填满时,程序有需要创建对象,JVM的垃圾回收器将对伊甸园区进行垃圾回收(Minor GC),将伊甸园区中的不再被其他对象所引用的对象进行销毁,再加载新的对象放到伊甸园区
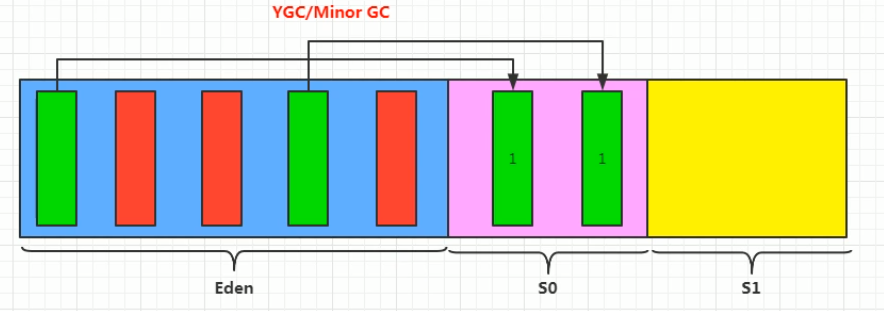
然后将伊甸园中的剩余对象移动到幸存者0区
如果再次触发垃圾回收,此时上次幸存下来的放到幸存者0区的,如果没有回收,就会放到幸存者1区
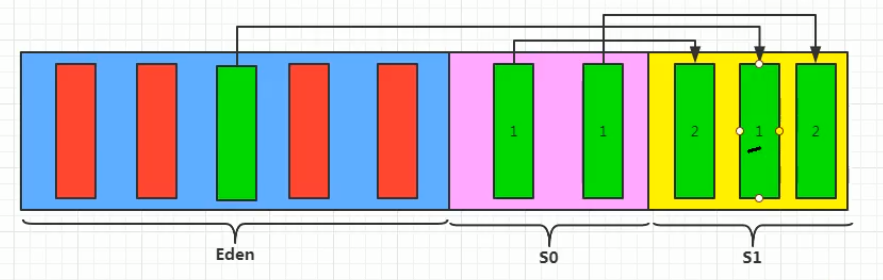
如果再次经历垃圾回收,此时会重新放回幸存者0区,接着再去幸存者1区
直到这个对象存活了15次,这个对象就可以去养老区了
- 可以通过设置参数:
-XX:MaxTenuringThreshold=<N>进行设置
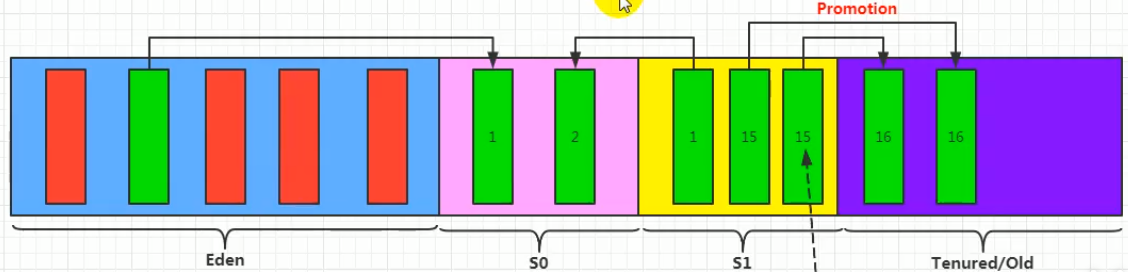
- 可以通过设置参数:
具体流程图:
常用调优工具
- JDK命令行 (jsp,jstat)
- Jconsole
- JVisualVM
- Jprofiler
- Java Flight Recorder
- GCViewer
- GC Easy
Minor GC,Major GC,Full GC
JVM再进行GC时,并非每次都对上面三个内存(新生代,老年代,方法区)区域一起回收的,大部分时候回收的都是指新生代
正如HotSpot VM的实现,它里面的GC按照回收区域又分为两大种类型:一种是部分收集(Partial GC),一种是整堆收集(Full GC)
- 部分收集:不是完整收集整个Java对的垃圾收集.其中又分为:
- 新生代收集(Young GC):只是新生代(Eden,S0,S1)的垃圾收集
- 老年代收集(Major GC/Old GC):只是老年代的垃圾收集
- 混合收集(Mixed GC):收集整个新生代以及部分老年代的垃圾收集
- 整堆收集(Full GC):收集整个Java堆和方法区的垃圾收集.
年轻代GC(Minor GC)触发机制:
- 当年轻代空间不足时,就会触发Minor GC 这里的年轻代满指的时Eden代满,Survivor满不会引发GC.
- 因为Java对象大多都具备朝生夕灭的特性,所以MinorGC非常频繁,一般回收速度也比较快
- Minor GC会引发STW(Stop The World),暂停其他用户的线程,等垃圾回收结束,用户线程才恢复运行
老年代GC(Major GC/Full GC)触发机制:
- 发生在老年代的GC,对象从老年代消失时,我们说"Major GC"或"Full GC"就发生了.
- 出现了Major GC,进场会伴随至少一次的Minor GC
- 也就是在老年代空间不足时.会先尝试触发Minor GC,如果之后空间还不足,则出发Major GC
- Major GC的速度一般会比Minor GC慢10倍以上,STW的时间更长
- 如果Major GC后,内存还不足,就会出现OOM.
Full GC触发机制
- 调用System.gc()时,系统建议执行Full GC,但是不必然执行
- 老年代空间不足
- 方法区空间不足
- 通过Minor GC进入老年代的平均大小大于老年代的可用内存
- 由Eden区,Survivor0区向Survivor1区复制时,对象大小大于Survivor1区可用内存,则把该对象转存到老年代,且老年代的可用内存小于该对象大小
为什么需要Java堆分代?
分代的唯一理由就是优化GC性能,如果没有分代,那所有的对象都在一块,Gc的时候要找到哪些对象没用,这里就会对堆的所有区域进行扫描.而很多对象生命周期都很短,如果分代的话,把新创建的对象放到一块,当GC的时候先把这块存储"朝生夕死"对象的区域进行回收,这样就会腾出很大的空间出来
内存分配策略
如果对象再Eden出生并经过第一次MinorGC后仍然存活,并且能被Survivor容纳的话,将被移动到Survivor空间中,并将对象年龄设为1.对象在Survivor区中每熬过一次MinorGC,年龄就增加1岁,当他的年龄增加到一定程度(默认为15岁)时,就会被晋升到老年代中
对象晋升老年代的年龄阈值可以通过设置参数:-XX:MaxTenuringThreshold=<N>进行设置
针对不同年龄段的对象分配原则如下所示:
- 优先分配到Eden
- 大对象直接分配到老年代
- 尽量避免程序中出现过多的大对象
- 长期存活的对象分配到老年代
- 动态对象年龄判断
- 如果Survivor区中相同年龄的所有对象大小的总和大于Survivor空间的一半,年龄大于或等于该年龄的对象可以直接进入老年代,无需等到MaxTenuringThreshold中要求的年龄
- 空间分配担保
-XX:HandlePromotionFailure
TLAB(Thread Local Allocation Buffer)
为什么有TLAB?
- 堆区是线程共享区域,任何线程都可以访问到堆区中的共享数据
- 由于对象实例的创建在JVM中非常频繁,因此在并发环境下从堆区中划分内存空间是线程不安全的
- 为避免多个线程操作同一地址,需要使用加锁等机制,进而影响分配速度
什么是TLAB?
- 从内存模型而不是垃圾收集的角度,对Eden区域继续进行划分,JVM为每个线程分配了一个私有缓存区域,它包含在Eden空间内
- 多线程同时分配内存时,使用TLAB可以避免一系列的非线程安全问题,同时还能够提升内存分配的吞吐量,因此我们可以将这种内存分配方式称之为 快速分配策略
堆空间的常用参数设置总结
** -XX:+PrintFlagsInitial:查看所有的参数的默认初始值
-xx:+PrintFlagsFinal:查看所有的参数的最终值
具体查看某个参数的指令:
jps:查看当前运行中的进程
jinfo -flag SurvivorRatio 进程id
-Xms:初始堆空间内存(默认为物理内存的1/64)
-Xmx:最大堆空间内存(默认为物理内存的1/4)
-Xmn:设置新生代的大小(初始值及最大值)
-XX:NewRatio:配置新生代与老年代在堆结构的占比
-XX:SurvivorRatio:设置新生代中Eden和S0/S1空间的比例
-XX:MaxTenuringThreshold:设置新生代垃圾的最大年龄
-XX:PrintGCDetails:输出详细的GC处理日志
-XX:PrintGC:打印GC简要信息
-XX:HandlePromotionFailure:是否设置空间分配担保
堆是分配对象存储的唯一选择么?
在《深入理解Java虚拟机》中关于Java堆内存有这样一段描述:
随着JIT编译期的发展与逃逸分析技术逐渐成熟,栈上分配,标量替换优化技术将会导致一些微妙的变化,所有的对象都分配到堆上也渐渐变得不那么"绝对"了.
在Java虚拟机中,对象是在Java堆中分配内存的,这是一个普遍的常识.但是,有一种特殊情况,那就是如果经过逃逸分析后发现,一个对象并没有逃逸出方法的话,那么就可能被优化成栈上分配.这样就无需在堆上分配内存,也无需进行垃圾回收了,这也是最常见的堆外存储技术
此外,TaoBaoVM,其中创新的GCIH(GC invisible heap)技术实现off-heap,将生命周期较长的Java对象从heap中移至heap外,并且GC不能管理GCIH内部的对象,以此达到降低GC的回收频率和提升GC的回收效率的目的
举个栗子:
pubilc static StringBuffer createStringBuffer(String s1,String s2){
StringBuffer sb = new StringBuffer();
sb.append(s1);
sb.append(s2);
//这个方法内新建的对象sb可能会被其他方法调用,即这个变量可能会逃逸,因此不能采用栈上分配的策略
return sb;
}
pubilc static String createStringBuffer(String s1,String s2){
StringBuffer sb = new StringBuffer();
sb.append(s1);
sb.append(s2);
//此时StringBuffer没有逃逸,但是toString()方法新建的String对象逃逸了.....
return sb.toString();
}
开发中能使用局部变量,就不要使用在方法外定义
逃逸分析:代码优化
使用逃逸分析,编译器可以对代码做如下优化:
- 栈上分配.将堆分配转换为栈分配.如果一个对象在子程序中被分配,要使指向该对象的指针永远不会逃逸,对象可能是栈分配的候选,而不是堆分配
- 同步省略.如果一个对象被发现只能从一个线程被访问到,那么对于这个对象的操作可以不考虑同步
- 分离对象或标量替换.有的对象可能不需要作为一个连续的内存结构存在也可以本访问到,那么对象的部分或全部可以不存储在内存,而是存储在CPU寄存器中
逃逸分析并不成熟
关于逃逸分析的论文在1999年就已经发表了,但直到JDK 1.6才有实现,而且这项技术到如今也并不是十分成熟的。
其根本原因就是无法保证逃逸分析的性能消耗一定能高于他的消耗。虽然经过逃逸分析可以做标量替换、栈上分配、和锁消除。但是逃逸分析自身也是需要进行一系列复杂的分析的,这其实也是一个相对耗时的过程。
一个极端的例子,就是经过逃逸分析之后,发现没有一个对象是不逃逸的。那这个逃逸分析的过程就白白浪费掉了.
有一些观点,认为通过逃逸分析,JVM会在栈上分配那些不会逃逸的对象,这在理论上是可行的,但是取决于JVM设计者的选择,Oracle HotspotJVM中并未这么做,所以可以明确所有的对象实例都是创建在堆上.
总结
- 年轻代是对象的诞生,成长,消亡的区域,一个对象在这里产生,应用,最后被垃圾回收器收集,结束生命
- 老年代放置长生命周期的对象,通常都是从Survivor区域筛选拷贝过来的Java对象,也有例外:如果对象太大,完全无法在新生代找到足够长的连续空闲空间,JVM就会直接分配到老年代.
- 当GC只发生在年轻代中,回收年轻代对象的行为被称为MinorGC,当GC发生在老年代时则被称为MajorGC或者FullGC.一般的,MinorGC的发生频率要比MajorGC高很多
Java堆的理解的更多相关文章
- 深入理解JVM(八)——java堆分析
上一节介绍了针对JVM的监控工具,包括JPS可以查看当前所有的java进程,jstack查看线程栈可以帮助你分析是否有死锁等情况,jmap可以导出java堆文件在MAT工具上进行分析等等.这些工具都非 ...
- 深入理解JVM一java堆分析
上一节介绍了针对JVM的监控工具,包括JPS可以查看当前所有的java进程,jstack查看线程栈可以帮助你分析是否有死锁等情况,jmap可以导出java堆文件在MAT工具上进行分析等等.这些工具都非 ...
- Java堆、栈和常量池以及相关String的详细讲解(经典中的经典) (转)
原文链接 : http://www.cnblogs.com/xiohao/p/4296088.html 一:在JAVA中,有六个不同的地方可以存储数据: 1. 寄存器(register). 这是最快的 ...
- Java堆、栈和常量池以及相关String的详细讲解
一:在JAVA中,有六个不同的地方可以存储数据: 1. 寄存器(register). 这是最快的存储区,因为它位于不同于其他存储区的地方——处理器内部.但是寄存器的数量极其有限,所以寄存器由编译器根据 ...
- java堆内存和栈内存的处理
前段时间学习二叉树在处理删除操作的时候遇到一个头疼的问题:删除节点的时候明明已经置null了可树上该节点依旧存在,还必须执行node.father.left = null;才可以删除node节点,寻找 ...
- 从几个sample来学习JAVA堆、方法区、JAVA栈和本地方法栈
最近在看<深入理解Java虚拟机>,书中给了几个例子,比较好的说明了几种OOM(OutOfMemory)产生的过程,大部分的程序员在写程序时不会太关注Java运行时数据区域的结构: 感觉有 ...
- java常量池理解
String类两种不同的创建方式 String s1 = "zheng"; //第一种创建方式 String s2 = new String("junxiang" ...
- JAVA堆与栈
数据类型: Java虚拟机中,数据类型可以分为两类:基本类型和引用类型.基本类型的变量保存原始值,即:他代表的值就是数值本身:而引用类型的变量保存引用值.“引用值”代表了某个对象的引用,而不是对象本身 ...
- 优化Java堆大小5温馨提示
总结:Java没有足够的堆大小可能会导致性能非常大的影响,这无疑将给予必要的程序,并不能带来麻烦.本文总结了影响Java居前五位的能力不足,并整齐地叠优化? 笔者Pierre有一个10高级系统架构师有 ...
随机推荐
- TEB 、TIB、PEB--Vista 32
TEB struct TEB typedef struct _TEB { NT_TIB NtTib; PVOID EnvironmentPointer; CLIENT_ID ClientId; PVO ...
- 利用Navicat premium实现将数据从Oracle导入到MySQL
背景:我们给用户提供了新的直播系统,但客户之前的老系统用的数据库是Oracle,我们提供的新系统用的是MySQL 客户诉求:将老系统中的所有直播数据导入到MySQL中: 思路:我知道Navicat有数 ...
- 阿里最强 Python 自动化工具开源了!
1. 前言 大家好,我是安果! 最近,阿里内部开源了一个 iOS 端由 Python 编写的自动化工具,即:tidevice 它是一款跨平台的自动化开源工具,不依赖 Xcode 就可以启动 WebDr ...
- [LeetCode]1. 两数之和(难度:简单)
题目: 给定一个整数数组nums和一个整数目标值target,请你在该数组中找出和为目标值的那两个整数,并返回它们的数组下标.你可以假设每种输入只会对应一个答案.但是,数组中同一个元素在答案里不能重复 ...
- 通过Dapr实现一个简单的基于.net的微服务电商系统(五)——一步一步教你如何撸Dapr之状态管理
状态管理和上一章的订阅发布都算是Dapr相较于其他服务网格框架来讲提供的比较特异性的内容,今天我们来讲讲状态管理. 目录:一.通过Dapr实现一个简单的基于.net的微服务电商系统 二.通过Dapr实 ...
- @Transactional+@Autowired出现的lateinit property xx has not been initialized错误
1 问题描述 用Kotlin编写Spring Boot,在业务层中使用@Transactional+@Autowired时出现如下错误: lateinit property dao has not b ...
- linux下Mysql 8.0.19 编译安装
1 前言 linux下安装MySQL的方式有很多种,包括以仓库的方式安装(yum,apt,zypper),以包的方式安装(rpm,deb),以docker方式安装,从压缩包解压安装,从源码编译安装,这 ...
- IDEA通过Maven打包JavaFX工程(OpenJFX11)
1 概述 最近研究JFX,写出来了但是打包不了,这...尴尬... IDEA的文档说只支持Java8打成jar包: 尝试过直接使用Maven插件的package,不行,也尝试过Build Artifa ...
- UT之最后一测
经过前面几次文章的分享的UT的相关知识,今天接着分享UT相关最后一测文章,希望对大家在UT的学习中有一点点的帮助. Spring集成测试 有时候我们需要在跑起来的Spring环境中验证,Spring ...
- UVA10391复合词
题意: 给定一个词典,然后问里面那些是复合词,复合词就是当前这个单词正好是有两个单词拼接而成. 思路: 用map来标记是否出现过,然后先按长短排序,把每个单体拆分成任意两个可能的 ...