WEB页面采集器编写经验之一:静态页面采集器
严格意义来说,采集器和爬虫不是一回事:采集器是对特定结构的数据来源进行解析、结构化,将所需的数据从中提取出来;而爬虫的主要目标更多的是页面里的链接和页面的TITLE。
采集器也写过不少了,随便写一点经验吧,算是给自己的一个备忘。
首先是最简单的:静态页面采集器。即所采集的数据来源页面是静态的,至少采集器所关心的那部分数据是静态的,可以通过直接访问页面URL的方式获取到包含目标数据的全部页面代码。这种采集器是最为常用,也是最为基础的。目前已经有很多成熟的商业化的采集器产品,不过对我来说感觉用着有些过于复杂。一些我自己编写采集器时会注意的问题在这些产品上似乎没有,或者名字不是我拟的那个,找不到。用了几次,干脆不如自己写了,还更省时间效率更高。
准备知识:HTTP协议基础、HTML语言基础、正则表达式和任意支持正则表达式的编程工具(.net、java、php、Python、ruby等等都可以)
首先第一步,是下载目标页面HTML。
这一步并没有什么太难的,.net里有HttpWebRequest和HttpWebResponse等类专门处理,其他语言里也有类似的东西。不过需要注意的是,为采集器编写下载器的时候,参数配置一定要灵活:User-Agent、Refer、Cookie等字段都得做成可配,还得支持使用代理服务器,这是为了突破目标服务器的访问限制策略或机器人识别策略。有关常见的反机器人以及反“反机器人”等相关技术会在后续文章里专门编写。
页面代码下载到本地之后,就得开始对其进行解析。有两种解析方法
1、将其当做HTML解析
熟悉HTML的人可以将下载到的HTML页面直接当做HTML来解析,这样做也是最快和最有效率的。遍历HTML元素和属性之后,直接找到关注部分数据内容,通过访问其元素、元素属性和子元素的方式获取数据。.net里原生没有HTML解析库,可以找第三方库,大多数比较好用,至少当一般拿来解析个页面提个数据之类的够用了。唯一需要注意的是需要考虑页面代码下载不完全或者目标页面结构存在错误的情况。
2、将其当做字符串,用正则表达式解析
正则表达式的好处就是灵活,在方法1失效或者实现麻烦(比如目标数据的HTML元素路径可能不固定)的时候可以考虑。使用正则表达式的思路就是寻找目标数据及其上下文的特征或者特征串,然后编写正则表达式将其匹配提取出来即可。
以下以解析bing的搜索结果页为例,介绍静态采集器工作的基本原理。
首先是页面获取。点击两下就能发现页面参数的规律,举例:
http://cn.bing.com/search?q=MOLLE+II&first=31
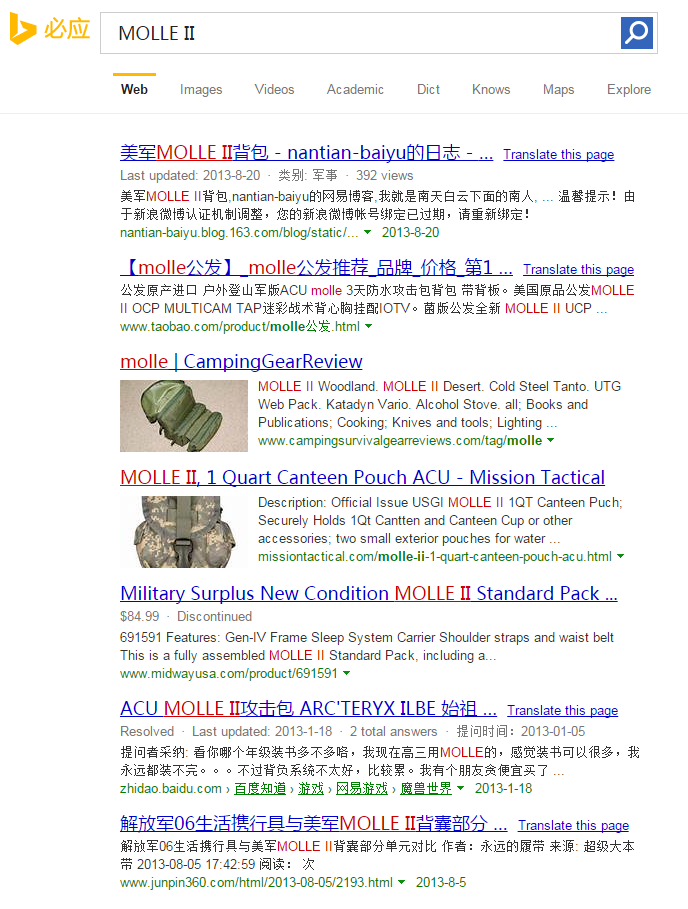
这个URL代表以“MOLLE”“II”两个关键词搜索,当前页面是是第四页。FIRST参数指的是本页第一个显示的搜索结果的索引号,第四页显示31-40个搜索结果。
这是用GET方式传递参数,大多数情况下都是这样的。如果目标页面用POST方式传递参数,用浏览器的开发者模式抓个包看看参数是啥就OK了。
然后我们就下载到了目标页面,将其在正则表达式测试器里打开:
恩,这活儿干得多了干脆自己写了一个趁手的工具。
我们的目标是提取到搜索结果里的链接文字和链接URL。对于需要从同一个页面解析得到两项或者多项相互对应的数量一样的数据,也有两种策略:根据这些数据不同的特征直接编写表达式从页面里提取目标数据(比如先用一个正则处理页面,拿到所有的链接标题文字,再用一个正则处理页面,拿到所有的链接URL),或者分析页面结构,找到包含目标数据项的最小页面结构(比如html表格里的表格行<tr>元素),再进行解析。其中后者更靠谱一点,也可以省去很多干扰,但稍微麻烦一些。以下以后一种方式进行介绍。
用浏览器的检查工具(Chrome里以前叫查看元素,新版改叫检查了,刚刚还找了半天)分析页面代码,我们可以发现所有的搜索内容都包含在一个id属性为"b_results"的<ol>标签里。编写表达式对其进行提取:
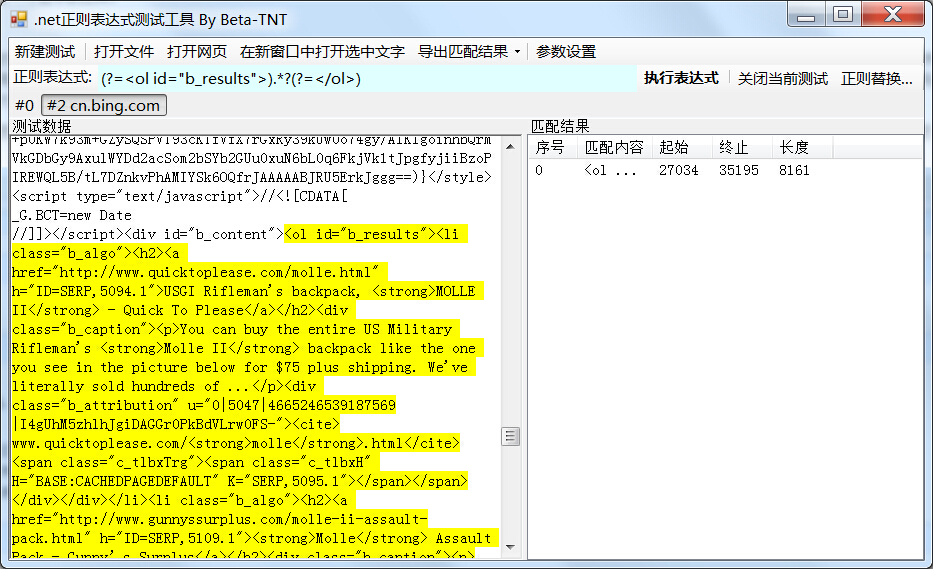
对于解析HTML用到的正则,零宽断言和逆序环视(查找)是经常用到的,用于提取带有特定前缀和后缀的字符串。有关正则表达式的技术博客园已经有很多相关文章,这里不再赘述。
不过需要注意的是,对于.net的正则表达式库,有一些开关需要注意。对于解析html的时候,经常需要将SingleLine参数选中,这样引擎会把字符串里所有的回车当成普通字符,而不是当成一行数据的结尾。不过这也并非绝对,也需要根据实际情况进行灵活配置。
另外还有一个小技巧。在移动端盛行的今天,一些网站会根据用户浏览器请求里的USER-AGENT提供不同的页面,对手机端发起的请求就会提供手机版的页面,出于节省客户流量的考虑,一般手机版的页面会比PC端的干净一些,页面噪音更少。
继续回到页面解析,刚刚已经找到包含所有目标元素的页面结构,实际上如果发现目标数据的最小结构的特征在页面里也是唯一的,直接提取也无妨:
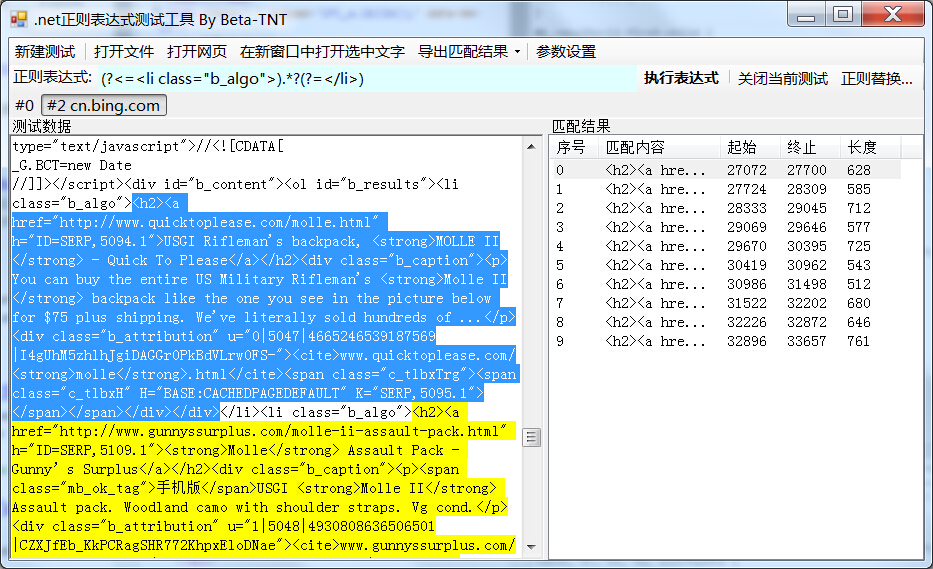
这样我们就拿到了所有包含目标数据的<li>标签的内容。顺带一提,因为截图里工具使用的NOKIA手机的USER AGENT,所以我拿到的是手机版的页面,和PC版略有不同,更干净一点。
下一步我们对每个元素进行解析。由于所有li标签的格式结构都是一样的,我们可以用同一套正则解析。
我们的目标是链接标题和链接URL,说白了,就是<a>标签的href属性和标签内容。
直接写表达式就好:

然后对于每个li标签的内容使用同样的表达式进行处理就OK了。
好了,采集器的基本原理介绍完毕,我自己写的这个正则工具可以我博客里找到,各位使用愉快,欢迎报BUG和功能建议。
下一篇将会介绍一下动态页面数据获取。
WEB页面采集器编写经验之一:静态页面采集器的更多相关文章
- 浅谈php生成静态页面
一.引 言 在速度上,静态页面要比动态页面的比方php快很多,这是毫无疑问的,但是由于静态页面的灵活性较差,如果不借助数据库或其他的设备保存相关信息的话,整体的管理上比较繁琐,比方修改编辑.比方阅读权 ...
- PHP生成静态页面详解
PHP生成静态页面详解 看到很多朋友在各个地方发帖问PHP生成静态文章系统的方法,以前曾做过这样一个系统,遂谈些看法,以供各位参考.好了,我们先回顾一些基本的概念. 一,PHP脚本与动态页面. PHP ...
- ASP.Net MVC如何访问的静态页面
MVC开发中,因为View文件夹下的web.config文件默认会把任何方法的请求的任何文件,路径都交给 System.Web.HttpNotFoundHandler 去处理.起到Controller ...
- SpringMVC与SpringBoot返回静态页面遇到的问题
1.SpringMVC静态页面响应 package com.sv.controller; import org.springframework.stereotype.Controller; impor ...
- 用 Smarty 生成静态页面入门介绍
why Smarty? 随着公司首页(以下简称首页)流量越来越大,最近开始考虑使用后台语言生成静态页面的技术. 我们知道,一个简单页面一般是一个 .html(或者 .htm ..shtml)后缀的文件 ...
- Ruby on Rails Tutorial 第三章 静态页面
1.生成静态页面 $ rails generate controller StaticPages home help #生成主页和帮助页面的路由.控制器及静态页面 $ rails destroy ...
- Java项目生成静态页面
第一次做项目需要生成静态页面,网上很多大牛对将网页生成静态页面有很多异议.说一下我的看法. 不外乎有以下因素: 1.从页面加载时间来看:静态页面不需要与数据库建立连接,尤其是访问数据量较大的页面,这种 ...
- 使用 gulp-file-include 构建前端静态页面
前言 虽然现在单页面很流行,但是在 PC 端多页面还是常态,所以构建静态页面的工具还有用武之地.最近也看到了一些询问如何 include HTML 文件的问题. 很多时候我们在写静态页面的时候也希望能 ...
- HTML:调用静态页面html 的几种方法
今天做办公用品管理系统时,发现需要用到在一个静态页面html 中调用多个静态页面html的内容.查找资料总结了以下一些方法: 一.iframe引入的方法 代码如下: <!-- 部门--> ...
随机推荐
- listview的用法
带标题和内容的 private String[] mtitle={"姓名","年龄","生日",};private String[] mar ...
- google.GIS小例子
var map; var array = [[41.774166667, 85.943055556], [43.864052, 87.560499]];//经纬度 var array1 = [&quo ...
- PHPMyAdmin弱口令猜解【Python脚本】
PHPMyAdmin弱口令猜解 测试截图: 代码片段 #! /usr/bin/env python # _*_ coding:utf-8 _*_ import requests import time ...
- Java JDBC链接数据库
1.注册驱动Class.forname("com.mysql.jdbc.Driver");//这是连接mysql数据库的驱动2.获取数据库连接java.sql.Connectio ...
- struct2的structs.xml文件配置There is no Action mapped for action name 问题
很久没写过博客,今天重新开始写,新技术太多,只有通过博客才可以不断积累,本人水平有限,如有错误,欢迎指正,谢谢 今天在MAVEN上配置web project的struct2,发现自己忽略了很多问题,再 ...
- js键盘事件全面控制详解
js键盘事件全面控制 主要分四个部分第一部分:浏览器的按键事件第二部分:兼容浏览器第三部分:代码实现和优化第四部分:总结 第一部分:浏览器的按键事件 用js实现键盘记录,要关注浏览器的三种按键事件 ...
- js中event.target
event.srcElement从字面上可以看出来有以下关键字:事件,源 他的意思就是:当前事件的源, 我们可以调用他的各种属性 就像:document.getElementById(&quo ...
- VS调试技巧,提高调试效率(转):
如果你还没有使用过这些技巧,希望这篇博文能帮你发现它们. 它们学起来很容易,能帮你节省很多时间. 运行到光标(Ctrl+ F10) 我经常看见人们是这样来调试应用程序的: 他们在应用程序需要调试的代码 ...
- Jquery cxColor 示例演示
今天第一次自己做调色板调用,看了半天官方的例子愣是没看懂,唉,码农老矣,尚能码否? 经过对官方下载的示例一删一浏览终于弄出来了,这么简单的东西,官方的Demo逼格也太高了 上代码: <!DOCT ...
- openssl 升级
openssl version -a rpm -q --changelog openssl | grep CVE bash -version #!/bin/bash if [[ $EUID -ne ...