InnoDB的数据页结构
页是InnoDB存储引擎管理数据库的最小磁盘单位。页类型为B-tree node的页,存放的即是表中行的实际数据了。
InnoDB数据页由以下七个部分组成,如图所示:
- File Header(文件头)。
- Page Header(页头)。
- Infimun+Supremum Records。
- User Records(用户记录,即行记录)。
- Free Space(空闲空间)。
- Page Directory(页目录)。
- File Trailer(文件结尾信息)。

File Header、Page Header、File Trailer的大小是固定的,用来标示该页的一些信息,如Checksum、数据所在索引层等。其余部分为实际的行记录存储空间,因此大小是动态的。
File Header
File Header用来记录页的一些头信息,由如下8个部分组成,共占用38个字节,如表4-3所示:

FIL_PAGE_SPACE_OR_CHKSUM:当MySQL版本小于MySQL-4.0.14,该值代表该页属于哪个表空间,因为如果我们没有开启innodb_file_per_table,共享表空间中可能存放了许多页,并且这些页属于不同的表空间。之后版本的MySQL,该值代表页的checksum值(一种新的checksum值)。
FIL_PAGE_OFFSET:表空间中页的偏移值。
FIL_PAGE_PREV,FIL_PAGE_NEXT:当前页的上一个页以及下一个页。B+Tree特性决定了叶子节点必须是双向列表。
FIL_PAGE_LSN:该值代表该页最后被修改的日志序列位置LSN(Log Sequence Number)。
FIL_PAGE_TYPE:页的类型。通常有以下几种,见表4-4。请记住0x45BF,该值代表了存放的数据页。


FIL_PAGE_FILE_FLUSH_LSN:该值仅在数据文件中的一个页中定义,代表文件至少被更新到了该LSN值。
FIL_PAGE_ARCH_LOG_NO_OR_SPACE_ID:从MySQL 4.1开始,该值代表页属于哪个表空间。
Page Header
接着File Header部分的是Page Header,用来记录数据页的状态信息,由以下14个部分组成,共占用56个字节。见表4-5。

PAGE_N_DIR_SLOTS:在Page Directory(页目录)中的Slot(槽)数。Page Directory会在后面介绍。
PAGE_HEAP_TOP:堆中第一个记录的指针。
PAGE_N_HEAP:堆中的记录数。
PAGE_FREE:指向空闲列表的首指针。
PAGE_GARBAGE:已删除记录的字节数,即行记录结构中,delete flag为1的记录大小的总数。
PAGE_LAST_INSERT:最后插入记录的位置。
PAGE_DIRECTION:最后插入的方向。可能的取值为PAGE_LEFT(0x01),PAGE_RIGHT(0x02),PAGE_SAME_REC(0x03),PAGE_SAME_PAGE(0x04),PAGE_NO_DIRECTION(0x05)。
PAGE_N_DIRECTION:一个方向连续插入记录的数量。
PAGE_N_RECS:该页中记录的数量。
PAGE_MAX_TRX_ID:修改当前页的最大事务ID,注意该值仅在Secondary Index定义。
PAGE_LEVEL:当前页在索引树中的位置,0x00代表叶节点。
PAGE_INDEX_ID:当前页属于哪个索引ID。
PAGE_BTR_SEG_LEAF:B+树的叶节点中,文件段的首指针位置。注意该值仅在B+树的Root页中定义。
PAGE_BTR_SEG_TOP:B+树的非叶节点中,文件段的首指针位置。注意该值仅在B+树的Root页中定义。
Infimum和Supremum记录
在InnoDB存储引擎中,每个数据页中有两个虚拟的行记录,用来限定记录的边界。Infimum记录是比该页中任何主键值都要小的值,Supremum指比任何可能大的值还要大的值。这两个值在页创建时被建立,并且在任何情况下不会被删除。在Compact行格式和Redundant行格式下,两者占用的字节数各不相同。下图显示了Infimum和Supremum Records。
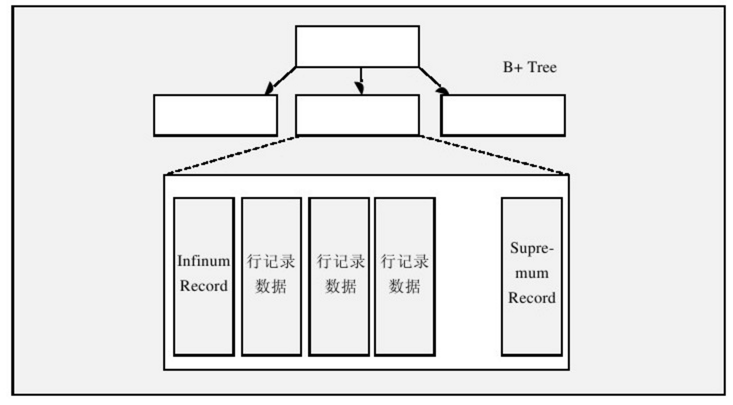
User Records与FreeSpace
User Records即实际存储行记录的内容。再次强调,InnoDB存储引擎表总是B+树索引组织的。
Free Space指的就是空闲空间,同样也是个链表数据结构。当一条记录被删除后,该空间会被加入空闲链表中。
Page Directory
Page Directory(页目录)中存放了记录的相对位置(注意,这里存放的是页相对位置,而不是偏移量),有些时候这些记录指针称为Slots(槽)或者目录槽(Directory Slots)。与其他数据库系统不同的是,InnoDB并不是每个记录拥有一个槽,InnoDB存储引擎的槽是一个稀疏目录(sparse directory),即一个槽中可能属于(belong to)多个记录,最少属于4条记录,最多属于8条记录。
Slots中记录按照键顺序存放,这样可以利用二叉查找迅速找到记录的指针。假设我们有('i','d','c','b','e','g','l','h','f','j','k','a'),同时假设一个槽中包含4条记录,则Slots中的记录可能是('a','e','i')。
由于InnoDB存储引擎中Slots是稀疏目录,二叉查找的结果只是一个粗略的结果,所以InnoDB必须通过recorder header中的next_record来继续查找相关记录。同时,slots很好地解释了recorder header中的n_owned值的含义,即还有多少记录需要查找,因为这些记录并不包括在slots中。
需要牢记的是,B+树索引本身并不能找到具体的一条记录,B+树索引能找到只是该记录所在的页。数据库把页载入内存,然后通过Page Directory再进行二叉查找。只不过二叉查找的时间复杂度很低,同时内存中的查找很快,因此通常我们忽略了这部分查找所用的时间。
File Trailer
为了保证页能够完整地写入磁盘(如可能发生的写入过程中磁盘损坏、机器宕机等原因),InnoDB存储引擎的页中设置了File Trailer部分。File Trailer只有一个FIL_PAGE_END_LSN部分,占用8个字节。前4个字节代表该页的checksum值,最后4个字节和File Header中的FIL_PAGE_LSN相同。通过这两个值来和File Header中的FIL_PAGE_SPACE_OR_CHKSUM和FIL_PAGE_LSN值进行比较,看是否一致(checksum的比较需要通过InnoDB的checksum函数来进行比较,不是简单的等值比较),以此来保证页的完整性(not corrupted)。
InnoDB数据页结构示例分析
首先我们建立一张表,并导入一定量的数据:
drop table if exists t;
create table t (a int unsigned not null auto_increment,b char(10),primary key(a))ENGINE=InnoDB CHARSET=UTF-8;
delimiter$$
create procedure load_t(count int unsigned)
begin
set@c=0;
while@c<count do
insert into t select null,repeat(char(97+rand()*26),10);
set@c=@c+1;
end while;
end;
$$
delimiter;
call load_t(100);
select * from t limit 10;
接着我们用工具py_innodb_page_info来分析t.ibd, py_innodb_page_info.py -v t.ibd
看到第四个页(page offset 3)是数据页,通过hexdump来分析t.ibd文件,打开整理得到的十六进制文件,数据页在0x0000c000(16K*3=0xc000)处开始:
先来分析前面File Header的38个字节:
52 1b 24 00数据页的Checksum值。
00 00 00 03页的偏移量,从0开始。
ff ff ff ff前一个页,因为只有当前一个数据页,所以这里为0xffffffff。
ff ff ff ff下一个页,因为只有当前一个数据页,所以这里为0xffffffff。
00 00 00 0a 6a e0 ac 93页的LSN。
45 bf页类型,0x45bf代表数据页。
00 00 00 00 00 00 00这里暂时不管该值。
00 00 00 dc表空间的SPACE ID。
先不急着看下面的Page Header部分,我们来看File Trailer部分。因为File Trailer通过比较File Header部分来保证页写入的完整性。
95 ae 5d 39 Checksum值,该值通过checksum函数和File Header部分的checksum值进行比较。
6a e0 ac 93注意到该值和File Header部分页的LSN后4个值相等。
接着我们来分析56个字节的Page Header部分,对于数据页而言,Page Header部分保存了该页中行记录的大量细节信息。分析后可得:
Page Header(56 bytes):
PAGE_N_DIR_SLOTS=0x001a
PAGE_HEAP_TOP=0x0dc0
PAGE_N_HEAP=0x8066
PAGE_FREE=0x0000
PAGE_GARBAGE=0x0000
PAGE_LAST_INSERT=0x0da5
PAGE_DIRECTION=0x0002
PAGE_N_DIRECTION=0x0063
PAGE_N_RECS=0x0064
PAGE_MAX_TRX_ID=0x0000000000000000
PAGE_LEVEL=00 00
PAGE_INDEX_ID=0x00000000000001ba
PAGE_BTR_SEG_LEAF=0x000000dc0000000200f2
PAGE_BTR_SEG_TOP=0x000000dc000000020032
PAGE_N_DIR_SLOTS=0x001a,代表Page Directory有26个槽,每个槽占用2个字节。
我们可以从0x0000ffc4到0x0000fff7找到如下内容:
0000ffc0 00 00 00 00 00 70 0d 1d 0c 95 0c 0d 0b 85 0a fd|……p……
0000ffd0 0a 75 09 ed 09 65 08 dd 08 55 07 cd 07 45 06 bd|.u……e……U……E..
0000ffe0 06 35 05 ad 05 25 04 9d 04 15 03 8d 03 05 02 7d|.5……%……}
0000fff0 01 f5 01 6d 00 e5 00 63 95 ae 5d 39 6a e0 ac 93|……m……c..]9j……
PAGE_HEAP_TOP=0x0dc0代表空闲空间开始位置的偏移量,即0xc000+0x0dc0=0xcdc0处开始,我们观察这个位置的情况,可以发现这的确是最后一行的结束,接下去的部分都是空闲空间了:
0000cdb0 00 00 00 2d 01 10 70 70 70 70 70 70 70 70 70 70|……-..pppppppppp
0000cdc0 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00|……
0000cdd0 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00|……
0000cde0 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00|……
PAGE_N_HEAP=0x8066,当行记录格式为Compact时,初始值为0x0802,当行格式为Redundant时,初始值是2。其实这些值表示页初始时就已经有Infinimun和Supremum的伪记录行,0x8066-0x8002=0x64,代表该页中实际的记录有100条记录。
PAGE_FREE=0x0000代表删除的记录数,因为这里我们没有进行过删除操作,所以这里的值为0。
PAGE_GARBAGE=0x0000,代表删除的记录字节为0,同样因为我们没有进行过删除操作,所以这里的值依然为0。
PAGE_LAST_INSERT=0x0da5,表示页最后插入的位置的偏移量,即最后的插入位置应该在0xc0000+0x0da5=0xcda5,查看该位置:
0000cda0 00 03 28 f2 cb 00 00 00 64 00 00 00 51 6e 4e 80|..(……d……QnN.
0000cdb0 00 00 00 2d 01 10 70 70 70 70 70 70 70 70 70 70|……-..pppppppppp
0000cdc0 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00|……
可以看到,最后这的确是最后插入a列值为100的行记录,但是这次直接指向了行记录的内容,而不是指向行记录的变长字段长度的列表位置。
PAGE_DIRECTION=0x0002,因为我们是通过自增长的方式进行行记录的插入,所以PAGE_DIRECTION的方向是向右。
PAGE_N_DIRECTION=0x0063,表示一个方向连续插入记录的数量,因为我们是以自增长的方式插入了100条记录,因此该值为99。
PAGE_N_RECS=0x0064,表示该页的行记录数为100,注意该值与PAGE_N_HEAP的比较,PAGE_N_HEAP包含两个伪行记录,并且是通过有符号的方式记录的,因此值为0x8066。
PAGE_LEVEL=0x00,代表该页为叶子节点。因为数据量目前较少,因此当前B+树索引只有一层。B+数叶子层总是为0x00。
PAGE_INDEX_ID=0x00000000000001ba,索引ID。
上面就是数据页的Page Header部分了,接下去就是存放的行记录了,前面提到过InnoDB存储引擎有2个伪记录行,用来限定行记录的边界,我们接着往下看:
0000c050 00 02 00 f2 00 00 00 dc 00 00 00 02 00 32 01 00|……2..
0000c060 02 00 1c 69 6e 66 69 6d 75 6d 00 05 00 0b 00 00|……infimum……
0000c070 73 75 70 72 65 6d 75 6d 0a 00 00 00 10 00 22 00|supremum……".
观察0xc05E到0xc077,这里存放的就是这两个伪行记录,InnoDB存储引擎设置伪行只有一个列,且类型是Char(8)。伪行记录的读取方式和一般的行记录并无不同,我们整理后可以得到如下的结果:
#Infimum伪行记录
01 00 02 00 1c/*recorder header*/
69 6e 66 69 6d 75 6d 00/*只有一个列的伪行记录,记录内容就是Infimum(多了一个0x00字节)
*/
#Supremum伪行记录
05 00 0b 00 00/*recorder header*/
73 75 70 72 65 6d 75 6d/*只有一个列的伪行记录,记录内容就是Supremum*/
我们来分析infimum行记录的recorder header部分,最后2个字节位00 1c表示下一个记录的位置的偏移量,即当前行记录内容的位置0xc063+0x001c,得到0xc07f。0xc07f应该很熟悉了,我们前面的分析的行记录结构都是从这个位置开始。我们来看一下:
0000c070 73 75 70 72 65 6d 75 6d 0a 00 00 00 10 00 22 00|supremum……".
0000c080 00 00 01 00 00 00 51 6d eb 80 00 00 00 2d 01 10|……Qm……-..
0000c090 64 64 64 64 64 64 64 64 64 64 0a 00 00 00 18 00|dddddddddd……
0000c0a0 22 00 00 00 02 00 00 00 51 6d ec 80 00 00 00 2d|"……Qm……-
可以看到这就是第一条实际行记录内容的位置了,如果整理后可以得到:
/*第一条行记录*/
00 00 00 01/*因为我们建表时设定了主键,这里ROWID即位列a的值1*/
00 00 00 51 6d eb/*Transaction ID*/
80 00 00 00 2d 01 10/*Roll Pointer*/
64 64 64 64 64 64 64 64 64 64/*b列的值'aaaaaaaaaa'*/
这和我们查表得到的数据是一致的:select a,b,hex(b) from t order by a limit 1;
通过recorder header最后2个字节记录的下一行记录的偏移量,我们就可以得到该页中所有的行记录;通过page header的PAGE_PREV,PAGE_NEXT就可以知道上一个页和下个页的位置。这样,我们就能读到整张表所有的行记录数据。
最后我们来分析Page Directory,前面我们已经提到了从0x0000ffc4到0x0000fff7是当前页的Page Directory,如下:
0000ffc0 00 00 00 00 00 70 0d 1d 0c 95 0c 0d 0b 85 0a fd|……p……
0000ffd0 0a 75 09 ed 09 65 08 dd 08 55 07 cd 07 45 06 bd|.u……e……U……E..
0000ffe0 06 35 05 ad 05 25 04 9d 04 15 03 8d 03 05 02 7d|.5……%……}
0000fff0 01 f5 01 6d 00 e5 00 63 95 ae 5d 39 6a e0 ac 93|……m……c..]9j……
需要注意的是,Page Directory是逆序存放的,每个槽2个字节。因此我们可以看到:00 63是最初行的相对位置,即0xc063;0070就是最后一行记录的相对位置,即0xc070。我们发现,这就是前面我们分析的infimum和supremum的伪行记录。Page Directory槽中的数据都是按照主键的顺序存放,因此找具体的行就需要通过部分进行。前面已经提到,InnoDB存储引擎的槽是稀疏的,还需通过recorder header的n_owned进行进一步的判断。如,我们要找主键a为5的记录,通过二叉查找Page Directory的槽,我们找到记录的相对位置在00 e5处,找到行记录的实际位置0xc0e5:
0000c0e0 04 00 28 00 22 00 00 00 04 00 00 00 51 6d ee 80|..(."……Qm..
0000c0f0 00 00 00 2d 01 10 69 69 69 69 69 69 69 69 69 69|……-..iiiiiiiiii
0000c100 0a 00 00 00 30 00 22 00 00 00 05 00 00 00 51 6d|……0."……Qm
0000c110 ef 80 00 00 00 2d 01 10 6e 6e 6e 6e 6e 6e 6e 6e|……-..nnnnnnnn
0000c120 6e 6e 0a 00 00 00 38 00 22 00 00 00 06 00 00 00|nn……8."……
0000c130 51 6d f0 80 00 00 00 2d 01 10 71 71 71 71 71 71|Qm……-..qqqqqq
0000c140 71 71 71 71 0a 00 00 00 40 00 22 00 00 00 07 00|qqqq……@."……
可以看到第一行的记录是4不是我们要找的5,但是我们看前面的5个字节的recordheader,04 00 28 00 22,找到4~8位表示n_owned值的部分,该值为4,表示该记录有4个记录,因此还需要进一步查找。通过recorder和ader最后2个字节的偏移量0x0022,找到下一条记录的位置0xc107,这才是我们要找的主键为5的记录。
InnoDB的数据页结构的更多相关文章
- InnoDB存储引擎介绍-(7) Innodb数据页结构
数据页结构 File Header 总共38 Bytes,记录页的头信息 名称 大小(Bytes) 描述 FIL_PAGE_SPACE 4 该页的checksum值 FIL_PAGE_OFFSET 4 ...
- InnoDB数据页结构
前言 关于数据库我们知道是通过内存对磁盘进行操作的,也知道数据会落实到磁盘上,但是数据在磁盘上的存储结构可能大家还不是很清楚. MySQL服务器上负责对表中的数据的读取和写入的工作的部分是存储 ...
- 数据页结构 .InnoDb行格式、以及索引底层原理分析
局部性原理 局部性原理是指CPU访问存储器时,无论是存取指令还是存取数据,所访问的存储单元都趋于聚集在一个较小的连续区域中. 首先要明白局部性原理能解决的是什么问题,也就是主存容量远远比缓存大, CP ...
- 【Mysql】InnoDB 引擎中的数据页结构
InnoDB 是 mysql 的默认引擎,也是我们最常用的,所以基于 InnoDB,学习页结构.而学习页结构,是为了更好的学习索引. 一.页的简介 页是 InnoDB 管理存储空间的基本单位,一个页的 ...
- Mysql之InnoDB行格式、数据页结构
Mysql架构图 存储引擎负责对表中的数据的进行读取和写入,常用的存储引擎有InnoDB.MyISAM.Memory等,不同的存储引擎有自己的特性,数据在不同存储引擎中存放的格式也是不同的,比如Mem ...
- MySQL InnoDB 索引 (INDEX) 页结构
MySQL InnoDB 索引 (INDEX) 页结构 InnoDB 为了不同的目的而设计了不同类型的页,我们把用于存放记录的页叫做索引页 索引页内容 索引页分为以下部分: File Header:表 ...
- SQL Server 存储(1/8):理解数据页结构
我们都很清楚SQL Server用8KB 的页来存储数据,并且在SQL Server里磁盘 I/O 操作在页级执行.也就是说,SQL Server 读取或写入所有数据页.页有不同的类型,像数据页,GA ...
- SQL Server :理解数据页结构
原文:SQL Server :理解数据页结构 我们都很清楚SQL Server用8KB 的页来存储数据,并且在SQL Server里磁盘 I/O 操作在页级执行.也就是说,SQL Server 读取或 ...
- MySQL之InnoDB数据页结构(转自掘金小册 MySQL是怎样运行的,版权归作者所有!)
InnoDB为了不同的目的而设计了不同类型的页,我们把用于存放记录的页叫做数据页. 一个数据页可以被大致划分为7个部分,分别是 File Header,表示页的一些通用信息,占固定的38字节. Pag ...
随机推荐
- Xcode8中添加SnapKit框架报错,编译失败
既然SnapKit的作者说SnapKit已经支持Swift3.0了,那么我们就先来适配SnapKit,首先用Xcode8新建一个空项目,利用Cocoapods导入SnapKit. Podfile 打 ...
- 模拟SPI协议时序
SPI是串行外设接口总线,摩托罗拉公司开发的一种全双工,同步通信总线,有四线制和三线制. 在单片机系统应用中,单片机常常是被用来当做主机(MASTER),外围器件被当做从机(SLAVE). 所以,在以 ...
- 关于Webdriver自动化测试时,页面数据与数据库id不一致的处理方式,需要使用鼠标事件
有时候Web页面需要通过onmouseout事件去动态的获取数据库的数据,在使用Webdriver进行自动化测试的时候,对于页面显示的数据,其在数据库可能会存在一个id或者code,但是id或者cod ...
- Activity之间的隐士跳转
/** * 方法一:在构造函数中指定 */ /*Intent intent=new Intent(this,TwoActivity ...
- angular.js——小小记事本3
app.js部分,首先是路由.这个之前讲过了,链接在这里—— http://www.cnblogs.com/thestudy/p/5661556.html var app = angular.modu ...
- TODO:小程序的使用体验
TODO:小程序的使用体验 2017.01.09小程序如期而至,话说十年前的今天2007.01.09是第一代iPhone发布日期. 清晨朋友圈发了一张小程序的截图,很多朋友问用什么版本的微信才有小程序 ...
- Kmeans聚类算法
K-means也是聚类算法中最简单的一种了,但是里面包含的思想却是不一般.最早我使用并实现这个算法是在学习韩爷爷那本数据挖掘的书中,那本书比较注重应用.看了Andrew Ng的这个讲义后才有些明白K- ...
- Windows进程间通信(上)
一.管道 管道(pipe)是用于进程间通信的共享内存区域.创建管道的进程称为管道服务器,而连接到这个管道的进程称为管道客户端.一个进程向管道写入信息,而另外一个进程从管道读取信息. 异步管道是基于字符 ...
- 关于LR监视Windows和linux的说明
一.监控windows系统: 1.监视连接前的准备工作 1)进入被监视windows系统,开启以下二个服务Remote Procedure Call(RPC) 和Remote Registry Ser ...
- @Autowired 和 @Resource
转自:Spring中@Autowired注解.@Resource注解的区别 Spring不但支持自己定义的@Autowired注解,还支持几个由JSR-250规范定义的注解,它们分别是@Resourc ...