Python爬虫学习——使用Cookie登录新浪微博
1.首先在浏览器中进入WAP版微博的网址,因为手机版微博的内容较为简洁,方便后续使用正则表达式或者beautifulSoup等工具对所需要内容进行过滤
https://login.weibo.cn/login/
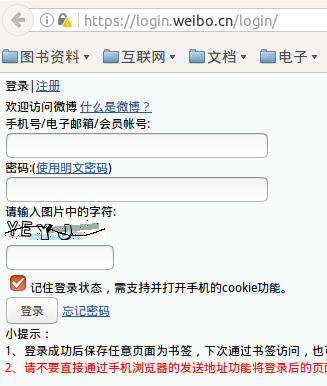
2.人工输入账号、密码、验证字符,最后最重要的是勾选(记住登录状态)
3.使用Wireshark工具或者火狐的HttpFox插件对GET请求进行分析,需要是取得GET请求中的Cookie信息
在未登录新浪微博的情况下,是可以通过网址查看一个用户的首页的,但是不能进一步查看该用户的关注和粉丝等信息,如果点击关注和粉丝,就会重定向回到登录页面
比如使用下面函数对某个用户 http://weibo.cn/XXXXXX/fans 的粉丝信息进行访问,会重定向回登录页面
#获取网页函数
def getHtml(url,user_agent="wswp",num_retries=2): #下载网页,如果下载失败重新下载两次
print '开始下载网页:',url
# headers = {'User-Agent':'Mozilla/5.0 (Windows NT 6.1; rv:24.0) Gecko/20100101 Firefox/24.0'}
headers = {"User-agent":user_agent}
request = urllib2.Request(url,headers=headers) #request请求包
try:
html = urllib2.urlopen(request).read() #GET请求
except urllib2.URLError as e:
print "下载失败:",e.reason
html = None
if num_retries > 0:
if hasattr(e,'code') and 500 <= e.code < 600:
return getHtml(url,num_retries-1)
return html

所以需要在请求的包中的headers中加入Cookie信息,
在勾选了记住登录状态之后,点击关注或者粉丝按钮,发出GET请求,并使用wireshark对这个GET请求进行抓包
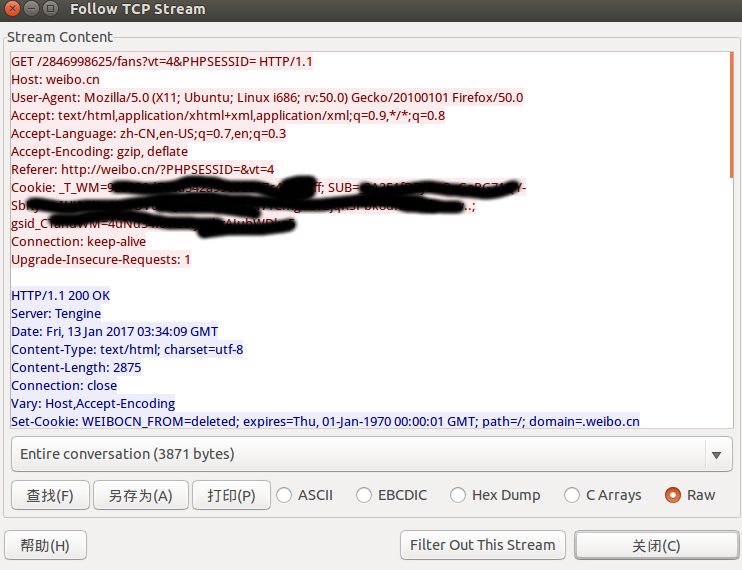
可以抓到这个GET请求

右键Follow TCP Stream,图片中打码的部分就Cookie信息
4.加入Cookie信息,重新获取网页
有了Cookie信息,就可以对Header信息就行修改
#获取网页函数
def getHtml(url,user_agent="wswp",num_retries=2): #下载网页,如果下载失败重新下载两次
print '开始下载网页:',url
# headers = {'User-Agent':'Mozilla/5.0 (Windows NT 6.1; rv:24.0) Gecko/20100101 Firefox/24.0'}
headers = {"User-agent":user_agent,"Cookie":"_T_WM=XXXXXXXX; SUB=XXXXXXXX; gsid_CTandWM=XXXXXXXXX"}
request = urllib2.Request(url,headers=headers) #request请求包
try:
html = urllib2.urlopen(request).read() #GET请求
except urllib2.URLError as e:
print "下载失败:",e.reason
html = None
if num_retries > 0:
if hasattr(e,'code') and 500 <= e.code < 600:
return getHtml(url,num_retries-1)
return html
import urllib2 if __name__ == '__main__':
URL = 'http://weibo.cn/XXXXXX/fans' #URL替代
html = getHtml(URL)
print html
成功访问到某个用户的粉丝信息
试一试访问一下最近一年很火的papi酱的微博,她的个人信息页面
import urllib2 if __name__ == '__main__':
URL = 'http://weibo.cn/2714280233/info' #URL替代
html = getHtml(URL)
print html

Python爬虫学习——使用Cookie登录新浪微博的更多相关文章
- Python爬虫学习:三、爬虫的基本操作流程
本文是博主原创随笔,转载时请注明出处Maple2cat|Python爬虫学习:三.爬虫的基本操作与流程 一般我们使用Python爬虫都是希望实现一套完整的功能,如下: 1.爬虫目标数据.信息: 2.将 ...
- Python爬虫学习:四、headers和data的获取
之前在学习爬虫时,偶尔会遇到一些问题是有些网站需要登录后才能爬取内容,有的网站会识别是否是由浏览器发出的请求. 一.headers的获取 就以博客园的首页为例:http://www.cnblogs.c ...
- 《Python爬虫学习系列教程》学习笔记
http://cuiqingcai.com/1052.html 大家好哈,我呢最近在学习Python爬虫,感觉非常有意思,真的让生活可以方便很多.学习过程中我把一些学习的笔记总结下来,还记录了一些自己 ...
- python爬虫scrapy框架——人工识别登录知乎倒立文字验证码和数字英文验证码(2)
操作环境:python3 在上一文中python爬虫scrapy框架--人工识别知乎登录知乎倒立文字验证码和数字英文验证码(1)我们已经介绍了用Requests库来登录知乎,本文如果看不懂可以先看之前 ...
- [转]《Python爬虫学习系列教程》
<Python爬虫学习系列教程>学习笔记 http://cuiqingcai.com/1052.html 大家好哈,我呢最近在学习Python爬虫,感觉非常有意思,真的让生活可以方便很多. ...
- python爬虫学习(1) —— 从urllib说起
0. 前言 如果你从来没有接触过爬虫,刚开始的时候可能会有些许吃力 因为我不会从头到尾把所有知识点都说一遍,很多文章主要是记录我自己写的一些爬虫 所以建议先学习一下cuiqingcai大神的 Pyth ...
- python爬虫学习 —— 总目录
开篇 作为一个C党,接触python之后学习了爬虫. 和AC算法题的快感类似,从网络上爬取各种数据也很有意思. 准备写一系列文章,整理一下学习历程,也给后来者提供一点便利. 我是目录 听说你叫爬虫 - ...
- Python爬虫学习:二、爬虫的初步尝试
我使用的编辑器是IDLE,版本为Python2.7.11,Windows平台. 本文是博主原创随笔,转载时请注明出处Maple2cat|Python爬虫学习:二.爬虫的初步尝试 1.尝试抓取指定网页 ...
- python爬虫学习视频资料免费送,用起来非常666
当我们浏览网页的时候,经常会看到像下面这些好看的图片,你是否想把这些图片保存下载下来. 我们最常规的做法就是通过鼠标右键,选择另存为.但有些图片点击鼠标右键的时候并没有另存为选项,或者你可以通过截图工 ...
随机推荐
- jQuery数字加减插件
jQuery数字加减插件 我们在网上购物提交订单时,在网页上一般会有一个选择数量的控件,要求买家选择购买商品的件数,开发者会把该控件做成可以通过点击实现加减等微调操作,当然也可以直接输入数字件数.本文 ...
- 什么是Solr搜索
什么是Solr搜索 一.Solr综述 什么是Solr搜索 我们经常会用到搜索功能,所以也比较熟悉,这里就简单的介绍一下搜索的原理. 当然只是介绍solr的原理,并不是搜索引擎的原理,那会更复杂. ...
- DataUml Design 课程6-DataUML Design 1.1版本号正式宣布(支持PD数据模型)
从DataUML Design正式宣布到现在两个月,因为最近忙,出版到现在为止1.1版本号.稍后我们将始终坚持以良好DataUML Design软件,我希望程序员有很多支持. 一.1.1新的和改进的版 ...
- QTP特点有哪些?
QTP特点有哪些? 浏览:77 | 更新:2013-06-19 12:35 QTP是一个侧重于功能的回归自动化测试工具:提供了很多插件,如:.NET的,Java的,SAP的,Terminal Emul ...
- MVC4中使用Ninject
MVC4中使用Ninject 1.NuGet获取Ninject.dll .NET技术交流群 199281001 .欢迎加入. 2.全局注册 Global.asax.cs RegisterNinje ...
- 动态注册HttpModule
动态注册HttpModule 2014-06-05 08:58 by 汤姆大叔, 757 阅读, 4 评论, 收藏, 编辑 文章内容 通过前面的章节,我们知道HttpApplication在初始化的时 ...
- SignalR1
SignalR循序渐进(一) 前阵子把玩了一下SignalR,起初以为只是个real-time的web通讯组件.研究了几天后发现,这玩意简直屌炸天,它完全就是个.net的双向异步通讯框架,用它能做很多 ...
- boost------ref的使用(Boost程序库完全开发指南)读书笔记
STL和Boost中的算法和函数大量使用了函数对象作为判断式或谓词参数,而这些参数都是传值语义,算法或函数在内部保修函数对象的拷贝并使用,例如: #include "stdafx.h&quo ...
- 上传文件大小限制,webconfig和IIS配置大文件上传
IIS6下上传大文件没有问题,但是迁移到IIS7下面,上传大文件时,出现HTTP 404错误. IIS配置上传大小,webconfig <!-- 配置允许上传大小 --><httpR ...
- C#HTTP代理的实现之注册表实现
HTTP代理的实现形式,可以通过修改注册表项,然后启动浏览器来实现,也可以通过SOCKET通信,构造HTTP头实现.下面是关于注册表实现的方式. 注册表实现,只需要修改几个关键的注册表项就可以了. 第 ...