Python爬虫学习——使用Cookie登录新浪微博
1.首先在浏览器中进入WAP版微博的网址,因为手机版微博的内容较为简洁,方便后续使用正则表达式或者beautifulSoup等工具对所需要内容进行过滤
https://login.weibo.cn/login/
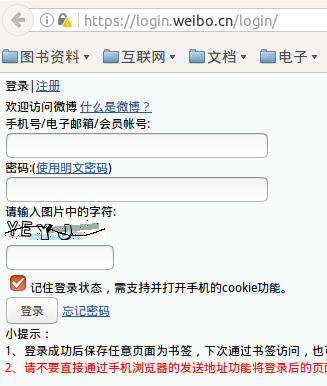
2.人工输入账号、密码、验证字符,最后最重要的是勾选(记住登录状态)
3.使用Wireshark工具或者火狐的HttpFox插件对GET请求进行分析,需要是取得GET请求中的Cookie信息
在未登录新浪微博的情况下,是可以通过网址查看一个用户的首页的,但是不能进一步查看该用户的关注和粉丝等信息,如果点击关注和粉丝,就会重定向回到登录页面
比如使用下面函数对某个用户 http://weibo.cn/XXXXXX/fans 的粉丝信息进行访问,会重定向回登录页面
#获取网页函数
def getHtml(url,user_agent="wswp",num_retries=2): #下载网页,如果下载失败重新下载两次
print '开始下载网页:',url
# headers = {'User-Agent':'Mozilla/5.0 (Windows NT 6.1; rv:24.0) Gecko/20100101 Firefox/24.0'}
headers = {"User-agent":user_agent}
request = urllib2.Request(url,headers=headers) #request请求包
try:
html = urllib2.urlopen(request).read() #GET请求
except urllib2.URLError as e:
print "下载失败:",e.reason
html = None
if num_retries > 0:
if hasattr(e,'code') and 500 <= e.code < 600:
return getHtml(url,num_retries-1)
return html

所以需要在请求的包中的headers中加入Cookie信息,
在勾选了记住登录状态之后,点击关注或者粉丝按钮,发出GET请求,并使用wireshark对这个GET请求进行抓包
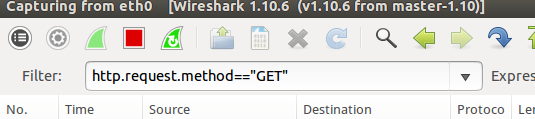
可以抓到这个GET请求

右键Follow TCP Stream,图片中打码的部分就Cookie信息
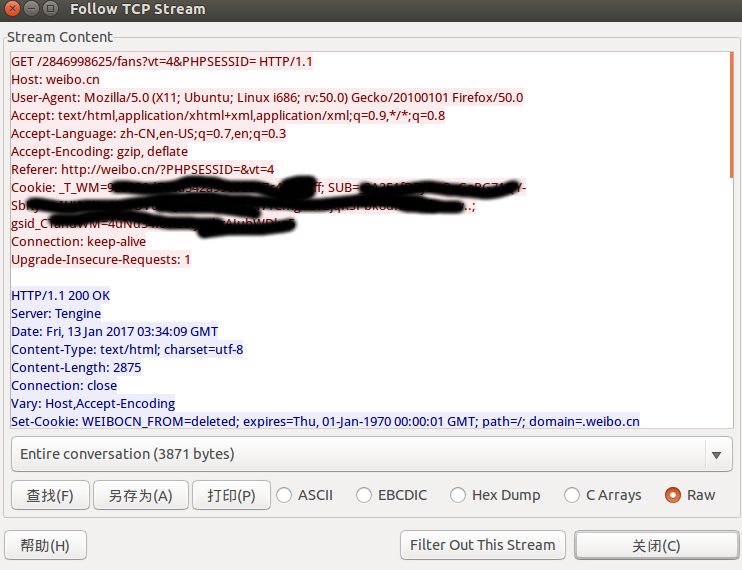
4.加入Cookie信息,重新获取网页
有了Cookie信息,就可以对Header信息就行修改
#获取网页函数
def getHtml(url,user_agent="wswp",num_retries=2): #下载网页,如果下载失败重新下载两次
print '开始下载网页:',url
# headers = {'User-Agent':'Mozilla/5.0 (Windows NT 6.1; rv:24.0) Gecko/20100101 Firefox/24.0'}
headers = {"User-agent":user_agent,"Cookie":"_T_WM=XXXXXXXX; SUB=XXXXXXXX; gsid_CTandWM=XXXXXXXXX"}
request = urllib2.Request(url,headers=headers) #request请求包
try:
html = urllib2.urlopen(request).read() #GET请求
except urllib2.URLError as e:
print "下载失败:",e.reason
html = None
if num_retries > 0:
if hasattr(e,'code') and 500 <= e.code < 600:
return getHtml(url,num_retries-1)
return html
import urllib2 if __name__ == '__main__':
URL = 'http://weibo.cn/XXXXXX/fans' #URL替代
html = getHtml(URL)
print html
成功访问到某个用户的粉丝信息
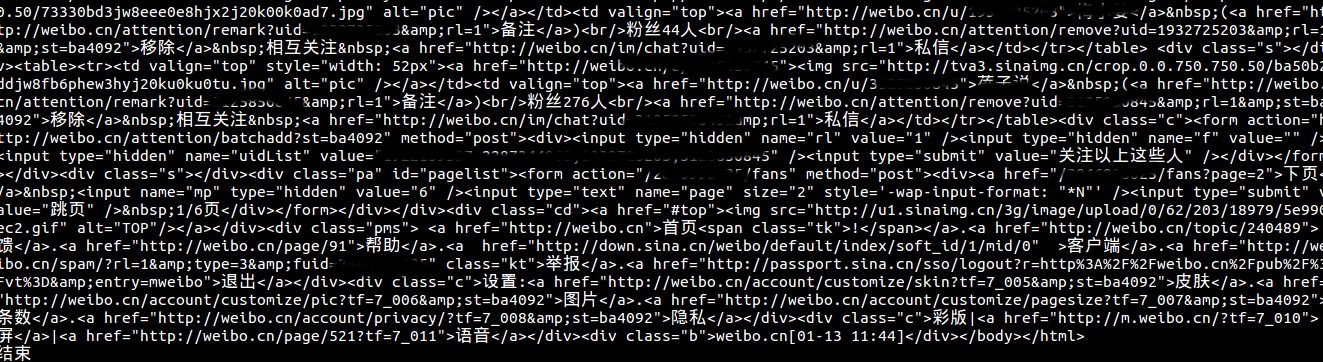
试一试访问一下最近一年很火的papi酱的微博,她的个人信息页面
import urllib2 if __name__ == '__main__':
URL = 'http://weibo.cn/2714280233/info' #URL替代
html = getHtml(URL)
print html

Python爬虫学习——使用Cookie登录新浪微博的更多相关文章
- Python爬虫学习:三、爬虫的基本操作流程
本文是博主原创随笔,转载时请注明出处Maple2cat|Python爬虫学习:三.爬虫的基本操作与流程 一般我们使用Python爬虫都是希望实现一套完整的功能,如下: 1.爬虫目标数据.信息: 2.将 ...
- Python爬虫学习:四、headers和data的获取
之前在学习爬虫时,偶尔会遇到一些问题是有些网站需要登录后才能爬取内容,有的网站会识别是否是由浏览器发出的请求. 一.headers的获取 就以博客园的首页为例:http://www.cnblogs.c ...
- 《Python爬虫学习系列教程》学习笔记
http://cuiqingcai.com/1052.html 大家好哈,我呢最近在学习Python爬虫,感觉非常有意思,真的让生活可以方便很多.学习过程中我把一些学习的笔记总结下来,还记录了一些自己 ...
- python爬虫scrapy框架——人工识别登录知乎倒立文字验证码和数字英文验证码(2)
操作环境:python3 在上一文中python爬虫scrapy框架--人工识别知乎登录知乎倒立文字验证码和数字英文验证码(1)我们已经介绍了用Requests库来登录知乎,本文如果看不懂可以先看之前 ...
- [转]《Python爬虫学习系列教程》
<Python爬虫学习系列教程>学习笔记 http://cuiqingcai.com/1052.html 大家好哈,我呢最近在学习Python爬虫,感觉非常有意思,真的让生活可以方便很多. ...
- python爬虫学习(1) —— 从urllib说起
0. 前言 如果你从来没有接触过爬虫,刚开始的时候可能会有些许吃力 因为我不会从头到尾把所有知识点都说一遍,很多文章主要是记录我自己写的一些爬虫 所以建议先学习一下cuiqingcai大神的 Pyth ...
- python爬虫学习 —— 总目录
开篇 作为一个C党,接触python之后学习了爬虫. 和AC算法题的快感类似,从网络上爬取各种数据也很有意思. 准备写一系列文章,整理一下学习历程,也给后来者提供一点便利. 我是目录 听说你叫爬虫 - ...
- Python爬虫学习:二、爬虫的初步尝试
我使用的编辑器是IDLE,版本为Python2.7.11,Windows平台. 本文是博主原创随笔,转载时请注明出处Maple2cat|Python爬虫学习:二.爬虫的初步尝试 1.尝试抓取指定网页 ...
- python爬虫学习视频资料免费送,用起来非常666
当我们浏览网页的时候,经常会看到像下面这些好看的图片,你是否想把这些图片保存下载下来. 我们最常规的做法就是通过鼠标右键,选择另存为.但有些图片点击鼠标右键的时候并没有另存为选项,或者你可以通过截图工 ...
随机推荐
- 【UVA】10285-Longest Run on a Snowboard(动态规划)
这是一个简单的问题.你并不需要打印路径. 状态方程dp[i][j] = max(dp[i-1][j],dp[i][j-1],dp[i+1][j],dp[i][j+1]); 14003395 10285 ...
- ckplayer
ckplayer 的使用基本功能实现(一) 有个项目里用到视频播放功能,虽然是国产的插件,但我觉得做的还是不错,而且是免费使用,顺便支持下国内的一些项目(O(∩_∩)O~). 一.首先去官网下载 插件 ...
- Cocos2d-x3.0 Json解析
2dx3.0下一个JSON解析库官员以及集成.我们参考一下吧OK. JSON文件hello.json内容 {"pets":["dog","cat&qu ...
- weblogic启动报错--com.octetstring.vde.backend.BackendRoot
错误现象: 使用bea用户启动weblogic时报错,错误信息如下: <2014-7-29 下午07时47分23秒 CST> <Notice> <Log Manageme ...
- Invent 2014回顾
AWS re:Invent 2014回顾 亚马逊在2014年11月11-14日的拉斯维加斯举行了一年一度的re:Invent大会.在今年的大会上,亚马逊一股脑发布和更新了很多服务.现在就由我来带领 ...
- Ibatis 返回datatable数据类型案例
/// <summary> /// 查询实体 [DataSet数据集] /// </summary> /// <param name="statementNam ...
- Javascript多线程引擎(三)
Javascript多线程引擎(三) 完成对ECMAScript-262 3rd规范的阅读后, 列出了如下的限制条件 1. 去除正则表达式( 语法识别先不编写) 2. 去除对Function Decl ...
- 在GridView的中有一个DropDownList,并且DropDownList有回传事件
在GridView的中有一个DropDownList,并且DropDownList有回传事件 最近做一个项目,需要在GridView中的ItemTemplate中添加一个DropDownList,并且 ...
- API变了,客户端怎么办?
使用ASP.NET Web Api构建基于REST风格的服务实战系列教程[九]——API变了,客户端怎么办? 系列导航地址http://www.cnblogs.com/fzrain/p/3490137 ...
- CSDN 高校俱乐部: 排列搜索
CSDN 高校俱乐部/英雄会 题目: 设数组a包含n个元素恰好是0..n - 1的一个排列,给定b[0],b[1],b[2],b[3]问有多少个0..n-1的排列a,满足(a[a[b[0]]]*b[0 ...