Request库基本使用
基本实例
import requests url= 'https://www.baidu.com/'
response = requests.get(url)
print(type(response))
print(response.status_code)#状态码
print(type(response.text))
print(response.text)#打开网页源代码
print(response.cookies)#获取cookies
各种请求方式
import requests url= 'https://www.baidu.com/'
requests.get(url)
requests.put(url)
requests.delete(url)
requests.head(url)
requests.options(url)
带参数的GET请求
import requests
data={
}
reponse = requests.get(url,params=data)
解析JSON
import requests
import json reponse = requests.get(url)
print(requests.json())
print(json.loads(reponse.text))
获取二进制数据和保存
import requests
import json reponse = requests.get(url)
print(reponse.text)
print(reponse.content)
import requests
import json reponse = requests.get(url)
with open(' ',' ') as f:
f.write(reponse.content)
f.close()
添加headers
import requests
import json headers = { }
response = requests.get(url,headers=headers)
基本POST请求
mport requests
import json data = { }
headers={ }
response = requests.post(url,data=data,headers=headers)
Reponse属性
import requests url= 'https://www.baidu.com/'
response = requests.get(url)
print(type(response))
print(response.status_code)#状态码
print(type(response.text))
print(response.text)#打开网页源代码
print(response.cookies)#获取cookies
print(response.history)
print(response.url)
文件上传
import requests
files = {'file':open('','rb')}
reponse = requests.post(url,files=files)
维持会话
import requests s = requests.session()
s.get(url_1)
response = s.get(url_2)
证书认证
import requests
from requests.packages import urllib3
urllib3.disable_warnings()#消除警告
response = requests.get(url,verify=False)
代理
import requests
proxies = {
"http":
"https":
}
requests.get(url,proxies=proxies)

pip3 install 'requests[socks]' 使用socks代理

import requests
from requests.exceptions import ReadTimeout try:
response = requests.get(url,timeout= )
except ReadTimeout:
print("time out")
认证设置
import requests
from requests.auth import HTTPBasicAuth response = requests.get(url,auth=HTTPBasicAuth('',''))
import requests
response = requests.get(url,auth=('',''))
异常处理
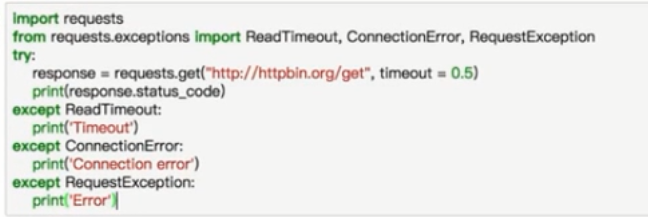
Request库基本使用的更多相关文章
- Python3 urllib.request库的基本使用
Python3 urllib.request库的基本使用 所谓网页抓取,就是把URL地址中指定的网络资源从网络流中读取出来,保存到本地. 在Python中有很多库可以用来抓取网页,我们先学习urlli ...
- Python request库与爬虫框架
Requests库的7个主要方法 requests.request():构造一个请求,支持以下各方法的基础方法 requests.get():获取HTML网页的主要方法,对应于HTTP的GET ...
- Request库使用response.text返回乱码问题
我们日常使用Request库获取response.text,这种调用方式返回的text通常会有乱码显示: import requests res = requests.get("https: ...
- 爬虫——urllib.request库的基本使用
所谓网页抓取,就是把URL地址中指定的网络资源从网络流中读取出来,保存到本地.在Python中有很多库可以用来抓取网页,我们先学习urllib.request.(在python2.x中为urllib2 ...
- 爬虫request库规则与实例
Request库的7个主要方法: requests.request(method,url,**kwargs) method:请求方式,对应get/put/post等7种: r = reques ...
- Python网络爬虫与信息提取[request库的应用](单元一)
---恢复内容开始--- 注:学习中国大学mooc 嵩天课程 的学习笔记 request的七个主要方法 request.request() 构造一个请求用以支撑其他基本方法 request.get(u ...
- Request库的安装与使用
Request库的安装与使用 安装 pip install reqeusts Requests库的7个主要使用方法 requests.request() 构造一个请求,支撑以下各方法的基础方法 req ...
- python网络爬虫学习笔记(一)Request库
一.Requests库的基本说明 引入Rquests库的代码如下 import requests 库中支持REQUEST, GET, HEAD, POST, PUT, PATCH, DELETE共7个 ...
- Request库学习
0x00前言 这库让我爱上了python 碉堡! 开心去学了一些python,然后就来学这个时候神库~~ 资料来源:http://cn.python-requests.org/en/latest/u ...
- 爬虫入门【1】urllib.request库用法简介
urlopen方法 打开指定的URL urllib.request.urlopen(url, data=None, [timeout, ]*, cafile=None, capath=None, ca ...
随机推荐
- 基于Flask框架的Python web程序的开发实战 <二> 项目组织结构
看到第七章-大型程序的结构,备受打击,搞不清工厂函数.蓝本.单元测试,不理解这些对象/变量怎么传递的,感觉好乱,虽然按照源码都照抄了,还是不理解.... 缓缓先.... 本来网上的Flask的教程就比 ...
- python爬虫框架(2)--PySpider框架安装配置
1.安装 1.phantomjs PhantomJS 是一个基于 WebKit 的服务器端 JavaScript API.它全面支持web而不需浏览器支持,其快速.原生支持各种Web标准:DOM 处理 ...
- linux系统 使用git图形化管理工具———gitk
运行安装命令: sudo apt-get install gitk 运行命令打开gitk : gitk
- sql基本查询语句练习
student(S#,Sname,Sage,Ssex) 学生表 S#:学号: Sname:学生姓名:Sage:学生年龄:Ssex:学生性别 Course(C#,Cname,T#) 课程表 ...
- nodejs安装配置
1.安装node.js(6.3.0)2.检测PATH环境变量是否配置了Node.jscmd下node --version3.D:/www/nodejs文件夹下创建hello.jsvar http = ...
- Java-马士兵设计模式学习笔记-工厂模式-单例及多例
一.单例的作用是用于控制类的生成方式,而不让外部类任意new对象 1.Car.java import java.util.ArrayList; import java.util.List; publi ...
- bzoj4391 [Usaco2015 dec]High Card Low Card
传送门 分析 神奇的贪心,令f[i]表示前i个每次都出比对方稍微大一点的牌最多能赢几次 g[i]表示从i-n中每次出比对方稍微小一点的牌最多赢几次 ans=max(f[i]+g[i+1]) 0< ...
- Entity Framework Tutorial Basics(28):Concurrency
Concurrency in Entity Framework: Entity Framework supports Optimistic Concurrency by default. In the ...
- Notepad++一键编译运行(Python、Java、C++)
Python 需要事先安装Python配置好环境变量.建议使用Anaconda,方便. 在Notepad按F5,输入如下 cmd /k chdir /d $(CURRENT_DIRECTORY) &a ...
- SQLite 如何清空表数据并将递增量归零
SQLite并不支持TRUNCATE TABLE语句 方式一: DELETE FROM [Tab_User] --不能将递增数归零 方式二: DELETE FROM sqlite_sequence W ...