时空上下文视觉跟踪(STC)算法
算法概述
而STC跟踪算法基于贝叶斯框架,根据跟踪目标与周围区域形成的的时空关系,在图像低阶特征上(如图像灰度和位置)对目标与附近区域进行了统计关系建模。通过计算置信图(confidence map),找到似然概率最大的位置,即为跟踪结果。
算法原理
上下文的重要性

在视觉跟踪,局部上下文包括一个目标和它的附近的一定区域的背景。因为,在连续帧间目标周围的局部场景其实存在着很强的时空关系。例如,上图中的目标存在着严重的阻挡,导致目标的外观发生了很大的变化。然而,因为只有小部分的上下文区域是被阻挡的,整体的上下问区域是保持相似的,所以该目标的局部上下文不会发生很大的变化。因此,当前帧局部上下文会有助于帮助预测下一帧中目标的位置。图中,黄色框的是目标,然后它和它的周围区域,也就是红色框包围的区域,就是该目标的上下文区域。左:虽然出现严重的阻挡导致目标的外观发现很大的变化,但目标中心(由黄色的点表示)和其上下文区域中的周围区域的其他位置(由红色点表示)的空间关系几乎没有发生什么变化。中:学习到的时空上下文模型(蓝色方框内的区域具有相似的值,表示该区域与目标中心具有相似的空间关系)。右:学习到的置信图。
时间信息:邻近帧间目标变化不会很大。位置也不会发生突变。
空间信息:目标和目标周围的背景存在某种特定的关系,当目标的外观发生很大变化时,这种关系可以帮助区分目标和背景。
对目标这两个信息的组合就是时空上下文信息,该论文就是利用这两个信息来进行对阻挡等鲁棒并且快速的跟踪。
置信图定义
在STC算法中,目标的定位问题可用一个目标在预估出现区域各个位置上的出现概率问题来处理。因此如果有一张概率图,可以知道图像中各个位置目标出现的概率,则图像中概率最大的位置就是目标最可能存在的位置,置信图定义为:
$c(x) = P(x|o) = b{e^{ - {{\left| {\frac{{x - {x^*}}}{\alpha }} \right|}^\beta }}}$
$x$表示目标位置,$o$ 表示目标出现, $b$为归一化常量,$\alpha $为尺度参数,$\beta $为形状参数。 ${x^*}$是目标的位置。其中$\beta =1 $能够有效的避免二义性和过拟合。
置信图可分解成为:
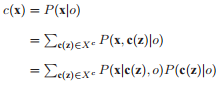
置信图似然函数分解为两个概率部分。一个是跟踪目标与周围上下文信息的空间关系的条件概率$P(x,c(z)|o)$,该条件概率使目标与其空间上下文建立关系。当图像中出现多个与目标相似的物体时,STC算法就要依靠空间上下文关系排除非目标本身的其他物体;另一个是目标局部上下文各个点X的上下文先验概率$P(c(z)|o)$。上下文先验概率描述了目标的外观特征。STC算法的核也就在于利用图像中得到的目标外观模型,通过在线学习得到一个时空上下文模型,利用时空上下文模型计算出置信图,从而得到目标最可能存在的位置。
空间上下文模型
定义上一小节中提到的,跟踪目标与周围上下文信息的空间关系的条件概率$P(x,c(z)|o)$ 即是空间上下文模型,定义为:
$P(x,c(z)|o){\rm{ = }}{{\rm{h}}^{{\rm{sc}}}}{\rm{(x - z)}}$
该模型表示目标位置 ${x^*}$与局部区域内点$z$之间的相对距离及方向关系,反映了目标与周围区域的空间关系。由于${h^{sc}}(x - z)$不是一个径向对称函数,因此解决分辨二异性问题。
置信图似然函数分解为两个概率部分。一个是跟踪目标与周围上下文信息的空间关系的条件概率$P(x,c(z)|o)$,该条件概率使目标与其空间上下文建立关系。当图像中出现多个与目标相似的物体时,STC算法就要依靠空间上下文关系排除非目标本身的其他物体;另一个是目标局部上下文各个点X的上下文先验概率$P(c(z)|o)$。上下文先验概率描述了目标的外观特征。STC算法的核也就在于利用图像中得到的目标外观模型,通过在线学习得到一个时空上下文模型,利用时空上下文模型计算出置信图,从而得到目标最可能存在的位置。
空间上下文模型定义
上一小节中提到的,跟踪目标与周围上下文信息的空间关系的条件概率$P(x,c(z)|o)$即是空间上下文模型,定义为:
$P(x,c(z)|o){\rm{ = }}{{\rm{h}}^{{\rm{sc}}}}{\rm{(x - z)}}$
该模型表示目标位置 ${x^*}$与局部区域内点 之间的相对距离及方向关系,反映了目标与周围区域的空间关系。由于${h^{sc}}(x - z)$不是一个径向对称函数,因此解决分辨二异性问题。
上下文先验模型定义
上下文先验概率模型可表示为:
$P(c(z)|o) = I(z){\omega _\sigma }(z - {x^*})$
$I(z)$表示$z$处的灰度值,${\omega _\sigma } = \alpha {e^{ - \frac{{{{\left| z \right|}^2}}}{{{\sigma ^2}}}}}$表示权重函数,该权重函数是由生物视觉系统的focus of attention启发得到的,它表示人看东西的时候,会聚焦在一个确定的图像区域。通常距离目标${x^*}$越近的点对于跟踪目标越重要,因此对应的权重值也越大。而距离越远则越容易被忽视。
时空上下文模型
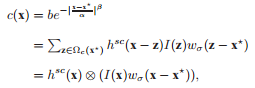
傅立叶变换得:
$F\left( {b{e^{ - {{\left| {\frac{{x - {x^*}}}{\alpha }} \right|}^\beta }}}} \right) = F({{\rm{h}}^{{\rm{sc}}}}(x)) \odot F(I(x){\omega _\sigma }(x - {x^*}))$
所以:
${{\rm{h}}^{{\rm{sc}}}}(x) = {F^{ - 1}}\left( {\frac{{F\left( {b{e^{ - {{\left| {\frac{{x - {x^*}}}{\alpha }} \right|}^\beta }}}} \right)}}{{F(I(x){\omega _\sigma }(x - {x^*})}}} \right)$
第t+1帧的时空上下文模型$H_{t + 1}^{stc}(x)$的更新公式为:
$H_{t + 1}^{stc}(x) = (1 - \rho )H_t^{stc} + \rho h_t^{sc}$
$\rho $为模型学习速率。这样算法通过不断学习到的空间上下文模型结合前一倾的时空上下文模型,就得到了当前顿的时空上下文模型,再利用该模型更新置信图,从而计算出当前顿目标的位置。
跟踪
得到时空上下文模型后,我们就可以在新的一帧计算目标的置信图了:
${c_{t + 1}}(x) = {F^{ - 1}}(H_{t + 1}^{stc}(x) \odot {I_{t + 1}}(x){\omega _{\sigma t}}(x - {x_t}*))$
然后置信图中值最大的位置,就是我们的目标位置了:
$x_{_{t + 1}}^* = \mathop {\arg \max }\limits_{x \in \Omega c(x_t^*)} {c_{t + 1}}(x)$
尺度更新
${\omega _\sigma } = \alpha {e^{ - \frac{{{{\left| z \right|}^2}}}{{{\sigma ^2}}}}}$中的$\sigma $应随着时间变化进行更新,更新的方法是:
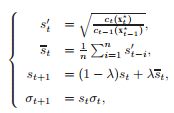
算法步骤
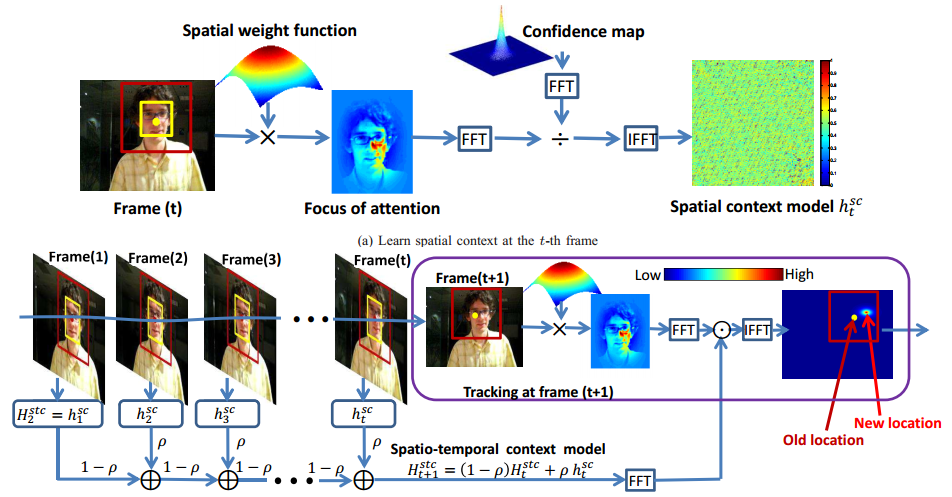
t帧:在该帧目标(第一帧由人工指定)已经知道的情况下,我们计算得到一个目标的置信图(Confidence Map,也就是目标的似然)。通过生物视觉系统上的focus of attention特性我们可以得到另一张概率图(先验概率)。通过对这两个概率图的傅里叶变换做除再反傅里叶变换,就可以得到建模目标和周围背景的空间相关性的空间上下文模型(条件概率)。然后我们用这个模型去更新跟踪下一帧需要的时空上下文模型。
t+1帧:利用t帧的上下文信息(时空上下文模型),卷积图像得到一个目标的置信图,值最大的位置就是我们的目标所在地。或者理解为图像各个地方对该上下文信息的响应,响应最大的地方自然就是满足这个上下文的地方,也就是目标了。
Ref:
时空上下文视觉跟踪(STC)算法的更多相关文章
- 时空上下文视觉跟踪(STC)算法的解读与代码复现(转)
时空上下文视觉跟踪(STC)算法的解读与代码复现 zouxy09@qq.com http://blog.csdn.net/zouxy09 本博文主要是关注一篇视觉跟踪的论文.这篇论文是Kaihua Z ...
- 时空上下文视觉跟踪(STC)
论文的关键点是对时空上下文(Spatio-Temporal Context)信息的利用.主要思想是通过贝叶斯框架对要跟踪的目标和它的局部上下文区域的时空关系进行建模,得到目标和其周围区域低级特征的统计 ...
- ICCV2021 | 用于视觉跟踪的学习时空型transformer
前言 本文介绍了一个端到端的用于视觉跟踪的transformer模型,它能够捕获视频序列中空间和时间信息的全局特征依赖关系.在五个具有挑战性的短期和长期基准上实现了SOTA性能,具有实时性,比 ...
- TLD视觉跟踪算法(转)
源:TLD视觉跟踪算法 TLD算法好牛逼一个,这里有个视频,是作者展示算法的效果,http://www.56.com/u83/v_NTk3Mzc1NTI.html.下面这个csdn博客里有人做的相关总 ...
- TLD视觉跟踪算法
TLD算法好牛逼一个,这里有个视频,是作者展示算法的效果,http://www.56.com/u83/v_NTk3Mzc1NTI.html.下面这个csdn博客里有人做的相关总结,感觉挺好的,收藏了! ...
- paper 140:TLD视觉跟踪算法(超棒)
我是看了这样的一个视频:http://www.56.com/u83/v_NTk3Mzc1NTI.html 然后在准备针对TLD视觉跟踪算法来个小的总结. 以下博文转自:http://blog.csdn ...
- 关于视觉跟踪中评价标准的相关记录(The Evaluation of Visual Tracking Results on OTB-100 Dataset)
关于视觉跟踪中评价标准的相关记录(The Evaluation of Visual Tracking Results on OTB-100 Dataset) 2018-01-22 21:49:17 ...
- DIY一个基于树莓派和Python的无人机视觉跟踪系统
DIY一个基于树莓派和Python的无人机视觉跟踪系统 无人机通过图传将航拍到的图像存储并实时传送回地面站差点儿已经是标配.假设想来点高级的--在无人机上直接处理拍摄的图像并实现自己主动控制要怎么实现 ...
- 视觉跟踪:MDnet
应用需注明原创! 深度学习在2015年中左右基本已经占据了计算机视觉领域中大部分分支,如图像分类.物体检测等等,但迟迟没有视觉跟踪工作公布,2015年底便出现了一篇叫MDNet的论文,致力于用神经网络 ...
随机推荐
- spider_action
spider from mobile to mobile to mobile from selenium import webdriver from selenium.webdriver.chrome ...
- Delphi 64与32位的差异
Delphi 64与32位的差异 最近,Delphi推出了64位预览版本, 我做为一个忠实的Delphier, 看到这消息后,第一时间学习,并写下这个做为以后的参考资料. 相同点: 在Delphi ...
- HDOJ 3473 Minimum Sum
划分树,统计每层移到左边的数的和. Minimum Sum Time Limit: 16000/8000 MS (Java/Others) Memory Limit: 65536/32768 K ...
- dig指定服务器查询域名解析时间
time=$(dig @8.8.8.8 baidu.com | grep Query | awk '{print $4}') echo $time 一 nslookup指定服务器查询域名解析时间 ro ...
- R中常用数据挖掘算法包
数据挖掘主要分为4类,即预测.分类.聚类和关联,根据不同的挖掘目的选择相应的算法.下面对R语言中常用的数据挖掘包做一个汇总: 连续因变量的预测: stats包 lm函数,实现多元线性回归 stats包 ...
- PHP网页导出Word文档的方法分离
今天要探讨的是PHP网页导出Word文档的方法,使用其他语言的朋友也可以参考,因为原理是差不多的. 原理 一般,有2种方法可以导出doc文档,一种是使用com,并且作为php的一个扩展库安装到服务器上 ...
- LRC歌词文件读取代码
/**************************************************/ /*******************-main文件-******************* ...
- vim 正则表达式查找ip
特别说明: \v \v 表示 very magic 这种模式下很多字符默认就表示一些特殊意义,而不用加 \ 如 : < 单词开头 > 单词结尾 ( 组开始 ) 组结束 { 次数开始 } 次 ...
- 【leetcode刷题笔记】Unique Binary Search Trees
Given n, how many structurally unique BST's (binary search trees) that store values 1...n? For examp ...
- HDU 1800 Flying to the Mars 字典树,STL中的map ,哈希树
http://acm.hdu.edu.cn/showproblem.php?pid=1800 字典树 #include<iostream> #include<string.h> ...