mapreduce总结
一、mapreduce简介
- MapReduce是一种分布式计算模型,是hadoop的核心组件之一,是Google提出的,主要用于搜索领域,解决海量数据的计算问题。
- MR有两个阶段组成:Map和Reduce,用户只需实现map()和reduce()两个函数,即可实现分布式计算。
MapReduce执行流程
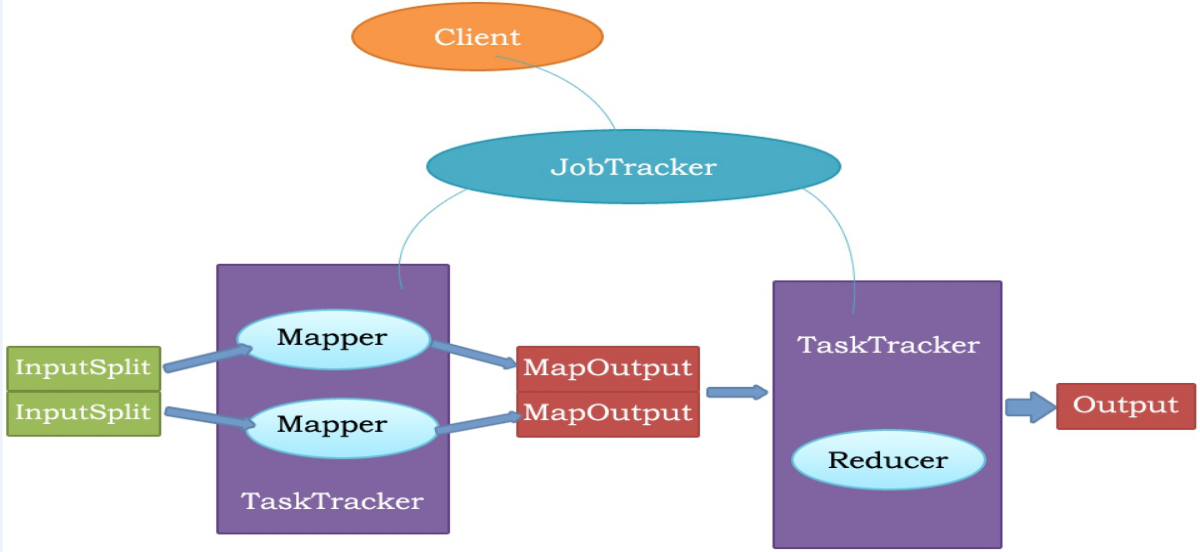
Client: 用来提交MapReduce作业。
JobTracker: 用来协调作业的运行。
TaskTracker: 用来处理作业划分后的任务。
MapReduce原理
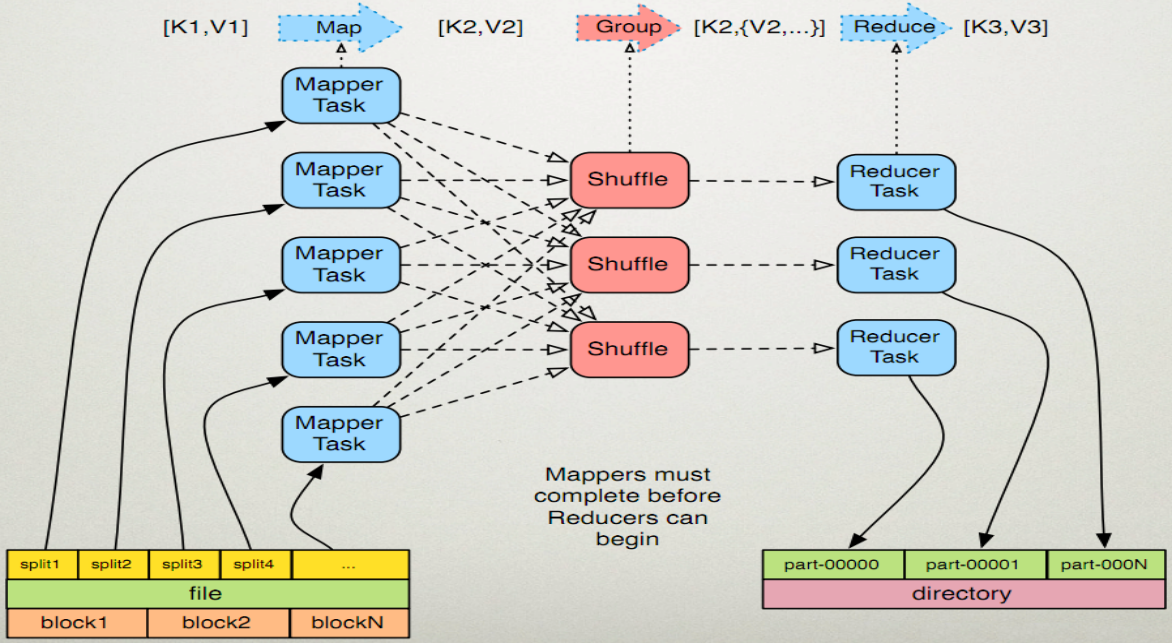
MapReduce的执行过程:
1、Map任务处理
- 第一阶段是把输入文件按照一定的标准分片 (InputSplit),每个输入片的大小是固定的。默认情况下,输入片(InputSplit)的大小与数据块(Block)的大小是相同的。如果数据块(Block)的大小是默认值64MB,输入文件有两个,一个是32MB,一个是72MB。那么小的文件是一个输入片,大文件会分为两个数据块,那么是两个输入片,一共产生三个输入片。每一个输入片由一个Mapper进程处理,这里的三个输入片,会有三个Mapper进程处理。
- 第二阶段是对输入片中的记录按照一定的规则解析成键值对,有个默认规则是把每一行文本内容解析成键值对,这里的“键”是每一行的起始位置(单位是字节),“值”是本行的文本内容。
- 第三阶段是调用Mapper类中的map方法,在第二阶段中解析出来的每一个键值对,调用一次map方法,如果有1000个键值对,就会调用1000次map方法,每一次调用map方法会输出零个或者多个键值对。
- 第四阶段是按照一定的规则对第三阶段输出的键值对进行分区,分区是基于键进行的,比如我们的键表示省份(如北京、上海、山东等),那么就可以按照不同省份进行分区,同一个省份的键值对划分到一个区中。默认情况下只有一个区,分区的数量就是Reducer任务运行的数量,因此默认只有一个Reducer任务。
- 第五阶段是对每个分区中的键值对进行排序。首先,按照键进行排序,对于键相同的键值对,按照值进行排序。比如三个键值 对<2,2>、<1,3>、<2,1>,键和值分别是整数。那么排序后的结果 是<1,3>、<2,1>、<2,2>。如果有第六阶段,那么进入第六阶段;如果没有,直接输出到本地的linux 文件中。
- 第六阶段是对数据进行归约处理,也就是reduce处理,通常情况下的Comber过程,键相等的键值对会调用一次reduce方法,经过这一阶段,数据量会减少,归约后的数据输出到本地的linxu文件中。本阶段默认是没有的,需要用户自己增加这一阶段的代码。
2、Reduce任务处理
- 第一阶段是Reducer任务会主动从Mapper任务复制其输出的键值对,Mapper任务可能会有很多,因此Reducer会复制多个Mapper的输出。(shuffle过程)
- 第二阶段是把复制到Reducer本地数据,全部进行合并,即把分散的数据合并成一个大的数据,再对合并后的数据排序。
- 第三阶段是对排序后的键值对调用reduce方法,键相等的键值对调用一次reduce方法,每次调用会产生零个或者多个键值对,最后把这些输出的键值对写入到HDFS文件中
二、java代码实现
实现文件中的单词个数统计
package mapreduce; import java.net.URI;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat; public class WordCountApp {
static final String INPUT_PATH = "hdfs://hadoop01:9000/hello";
static final String OUT_PATH = "hdfs://hadoop01:9000/out"; public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
FileSystem fileSystem = FileSystem.get(new URI(INPUT_PATH), conf);
Path outPath = new Path(OUT_PATH);
if (fileSystem.exists(outPath)) {
fileSystem.delete(outPath, true);
} Job job = new Job(conf, WordCountApp.class.getSimpleName()); // 1.1指定读取的文件位于哪里
FileInputFormat.setInputPaths(job, INPUT_PATH);
// 指定如何对输入的文件进行格式化,把输入文件每一行解析成键值对
//job.setInputFormatClass(TextInputFormat.class); // 1.2指定自定义的map类
job.setMapperClass(MyMapper.class);
// map输出的<k,v>类型。如果<k3,v3>的类型与<k2,v2>类型一致,则可以省略
//job.setOutputKeyClass(Text.class);
//job.setOutputValueClass(LongWritable.class); // 1.3分区
//job.setPartitionerClass(org.apache.hadoop.mapreduce.lib.partition.HashPartitioner.class);
// 有一个reduce任务运行
//job.setNumReduceTasks(1); // 1.4排序、分组 // 1.5归约 // 2.2指定自定义reduce类
job.setReducerClass(MyReducer.class);
// 指定reduce的输出类型
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(LongWritable.class); // 2.3指定写出到哪里
FileOutputFormat.setOutputPath(job, outPath);
// 指定输出文件的格式化类
//job.setOutputFormatClass(TextOutputFormat.class); // 把job提交给jobtracker运行
job.waitForCompletion(true);
} /**
*
* KEYIN 即K1 表示行的偏移量
* VALUEIN 即V1 表示行文本内容
* KEYOUT 即K2 表示行中出现的单词
* VALUEOUT 即V2 表示行中出现的单词的次数,固定值1
*
*/
static class MyMapper extends
Mapper<LongWritable, Text, Text, LongWritable> {
protected void map(LongWritable k1, Text v1, Context context)
throws java.io.IOException, InterruptedException {
String[] splited = v1.toString().split(" ");
for (String word : splited) {
context.write(new Text(word), new LongWritable(1));
}
};
} /**
* KEYIN 即K2 表示行中出现的单词
* VALUEIN 即V2 表示出现的单词的次数
* KEYOUT 即K3 表示行中出现的不同单词
* VALUEOUT 即V3 表示行中出现的不同单词的总次数
*/
static class MyReducer extends
Reducer<Text, LongWritable, Text, LongWritable> {
protected void reduce(Text k2, java.lang.Iterable<LongWritable> v2,
Context ctx) throws java.io.IOException,
InterruptedException {
long times = 0L;
for (LongWritable count : v2) {
times += count.get();
}
ctx.write(k2, new LongWritable(times));
};
}
}
mapreduce总结的更多相关文章
- Mapreduce的文件和hbase共同输入
Mapreduce的文件和hbase共同输入 package duogemap; import java.io.IOException; import org.apache.hadoop.co ...
- mapreduce多文件输出的两方法
mapreduce多文件输出的两方法 package duogemap; import java.io.IOException; import org.apache.hadoop.conf ...
- mapreduce中一个map多个输入路径
package duogemap; import java.io.IOException; import java.util.ArrayList; import java.util.List; imp ...
- Hadoop 中利用 mapreduce 读写 mysql 数据
Hadoop 中利用 mapreduce 读写 mysql 数据 有时候我们在项目中会遇到输入结果集很大,但是输出结果很小,比如一些 pv.uv 数据,然后为了实时查询的需求,或者一些 OLAP ...
- [Hadoop in Action] 第5章 高阶MapReduce
链接多个MapReduce作业 执行多个数据集的联结 生成Bloom filter 1.链接MapReduce作业 [顺序链接MapReduce作业] mapreduce-1 | mapr ...
- MapReduce
2016-12-21 16:53:49 mapred-default.xml mapreduce.input.fileinputformat.split.minsize 0 The minimum ...
- 使用mapreduce计算环比的实例
最近做了一个小的mapreduce程序,主要目的是计算环比值最高的前5名,本来打算使用spark计算,可是本人目前spark还只是简单看了下,因此就先改用mapreduce计算了,今天和大家分享下这个 ...
- MapReduce剖析笔记之八: Map输出数据的处理类MapOutputBuffer分析
在上一节我们分析了Child子进程启动,处理Map.Reduce任务的主要过程,但对于一些细节没有分析,这一节主要对MapOutputBuffer这个关键类进行分析. MapOutputBuffer顾 ...
- MapReduce剖析笔记之七:Child子进程处理Map和Reduce任务的主要流程
在上一节我们分析了TaskTracker如何对JobTracker分配过来的任务进行初始化,并创建各类JVM启动所需的信息,最终创建JVM的整个过程,本节我们继续来看,JVM启动后,执行的是Child ...
- MapReduce剖析笔记之六:TaskTracker初始化任务并启动JVM过程
在上面一节我们分析了JobTracker调用JobQueueTaskScheduler进行任务分配,JobQueueTaskScheduler又调用JobInProgress按照一定顺序查找任务的流程 ...
随机推荐
- 【转】asp使用母版页时内容页如何使用css和javascript
源地址:https://www.cnblogs.com/accumulater/p/6767138.html
- django 学习之DRF (三)
Django学习之DRF-03 视图集 1.视图集介绍 2.视图集基本使⽤ 1.需求 使⽤视图集获取列表数据和单⼀数据 2.实现 class BookInfoV ...
- vue2.0 vs vue1.0
1.每个组件模板不支持代码片段组件中模板之前<template> <h3>as</h3></template>现在 必须要有根元素 包裹住所有代码< ...
- ios swift 实现简单MVP模式
在移动开发中,会用到各种架构,比如mvp,mvvm等,其目的就是为了让项目代码的可读性更好,减轻在android(activity) ios(controller)中的大量代码问题.接下来就开始我们的 ...
- Jmeter-逻辑控制器之Switch控制器(Switch Controller)
Switch控制器(Switch Controller): 作用:Switch控制器通过给该控制器中的Value赋值,来指定运行哪个采样器.有两种赋值方式: 第一种是数值,Switch控制器下的子节点 ...
- mybatis 批量update两种方法对比
<!-- 这次用resultmap接收输出结果 --> <select id="findByName" parameterType="string&qu ...
- ArcGIS-各类问题
arcgis 10.4破解方法*注意!Desktop,Engine,Server必须为同一版本 1.先安装License10.4 2.再安装Desktop10.4 3.再安装Engine10.4 4. ...
- CF796C Bank Hacking 思维
Although Inzane successfully found his beloved bone, Zane, his owner, has yet to return. To search f ...
- JiJiDown
发生了预料之外的错误:System.Reflection.TargetInvocationException: Exception has been thrown by the target of a ...
- POJ 3686 *最小费用流-转化成普通指派问题)
题意] 有N个订单和M个机器,给出第i个订单在第j个机器完成的时间Mij,每台机器同一时刻只能处理一个订单,机器必须完整地完成一个订单后才能接着完成下一个订单.问N个订单完成时间的平均值最少为多少. ...