Spark Mllib里相似度度量(基于余弦相似度计算不同用户之间相似性)(图文详解)
不多说,直接上干货!
常见的推荐算法
1、基于关系规则的推荐
2、基于内容的推荐
3、人口统计式的推荐
4、协调过滤式的推荐
协调过滤算法,是一种基于群体用户或者物品的典型推荐算法,也是目前常用的推荐算法中最常用和最经典的算法。
协调过滤算法主要有两种:
用户对物品: 考查具有相同爱好的用户对相同物品的评分标准进行计算;
物品对用户: 考查具有相同物质的物品从而推荐给选择了某件物品的用户。
相似度度量(基于欧几里得距离的相似度计算和基于余弦角度的相似度计算)
(1)、基于欧几里得距离的相似度计算
欧几里得,是三维空间中两个点的真实距离。
欧几里得相似度计算是一种基于用户之间直线距离的计算方式。在相似度计算中,不同的物品或者用户可以将其定义为不同的坐标点,而特定目标定位为坐标原点。
在实际应用中,常常使用欧几里得距离的倒数作为相似度,即 1/ (d+1) 作为近似值。
(2)、基于余弦角度的相似度计算
不同的物品或者用户作为不同的坐标点,但不能为坐标原点。
其实,还有其他的算法,也可以来相似度度量。

基于欧几里得距离的相似度计算和基于余弦角度的相似度计算的区别
欧几里得相似度是以目标绝对距离作为衡量的标准,余弦相似度以目标差异的大小作为衡量标准。
欧几里得相似度注重目标之间的差异,与目标在空间中的位置直接相关。余弦相似度是不同目标在空间中的夹角,更加表现在前进趋势上的差异。
欧几里得相似度和余弦相似度具有不同的计算方法和描述特征,一般来说,欧几里得相似度用来表现不同目标的绝对差异性,分析目标之间的相似度与差异情况。而余弦相似度更多的是对目标从方向趋势上区分,对特定坐标数字不敏感。
基于余弦相似度计算不同用户之间相似性
步骤是:
(1)输入数据
(2)建立相似度算法公式
(3)计算不同用户之间的相似度
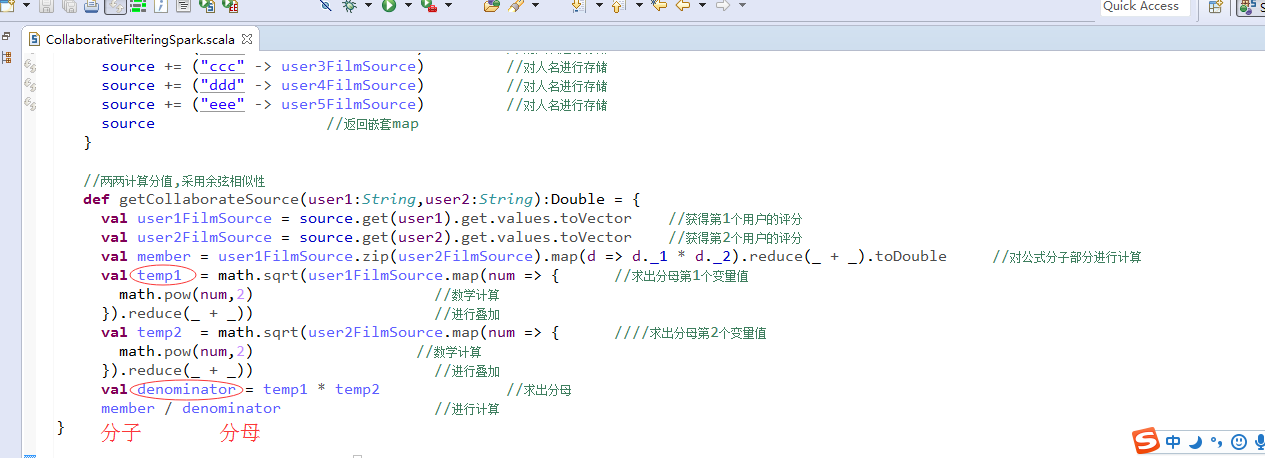
CollaborativeFilteringSpark.scala
package zhouls.bigdata.chapter5
import org.apache.spark.{SparkConf, SparkContext}
import scala.collection.mutable.Map
object CollaborativeFilteringSpark {
val conf = new SparkConf().setMaster("local").setAppName("CollaborativeFilteringSpark ") //设置环境变量
val sc = new SparkContext(conf) //实例化环境
val users = sc.parallelize(Array("aaa","bbb","ccc","ddd","eee")) //设置用户
val films = sc.parallelize(Array("smzdm","ylxb","znh","nhsc","fcwr")) //设置电影名
val source = Map[String,Map[String,Int]]() //使用一个source嵌套map作为姓名电影名和分值的存储
val filmSource = Map[String,Int]() //设置一个用以存放电影分的map
def getSource(): Map[String,Map[String,Int]] = { //设置电影评分
val user1FilmSource = Map("smzdm" -> ,"ylxb" -> ,"znh" -> ,"nhsc" -> ,"fcwr" -> )
val user2FilmSource = Map("smzdm" -> ,"ylxb" -> ,"znh" -> ,"nhsc" -> ,"fcwr" -> )
val user3FilmSource = Map("smzdm" -> ,"ylxb" -> ,"znh" -> ,"nhsc" -> ,"fcwr" -> )
val user4FilmSource = Map("smzdm" -> ,"ylxb" -> ,"znh" -> ,"nhsc" -> ,"fcwr" -> )
val user5FilmSource = Map("smzdm" -> ,"ylxb" -> ,"znh" -> ,"nhsc" -> ,"fcwr" -> )
source += ("aaa" -> user1FilmSource) //对人名进行存储
source += ("bbb" -> user2FilmSource) //对人名进行存储
source += ("ccc" -> user3FilmSource) //对人名进行存储
source += ("ddd" -> user4FilmSource) //对人名进行存储
source += ("eee" -> user5FilmSource) //对人名进行存储
source //返回嵌套map
}
//两两计算分值,采用余弦相似性
def getCollaborateSource(user1:String,user2:String):Double = {
val user1FilmSource = source.get(user1).get.values.toVector //获得第1个用户的评分
val user2FilmSource = source.get(user2).get.values.toVector //获得第2个用户的评分
val member = user1FilmSource.zip(user2FilmSource).map(d => d._1 * d._2).reduce(_ + _).toDouble //对公式分子部分进行计算
val temp1 = math.sqrt(user1FilmSource.map(num => { //求出分母第1个变量值
math.pow(num,) //数学计算
}).reduce(_ + _)) //进行叠加
val temp2 = math.sqrt(user2FilmSource.map(num => { ////求出分母第2个变量值
math.pow(num,) //数学计算
}).reduce(_ + _)) //进行叠加
val denominator = temp1 * temp2 //求出分母
member / denominator //进行计算
}
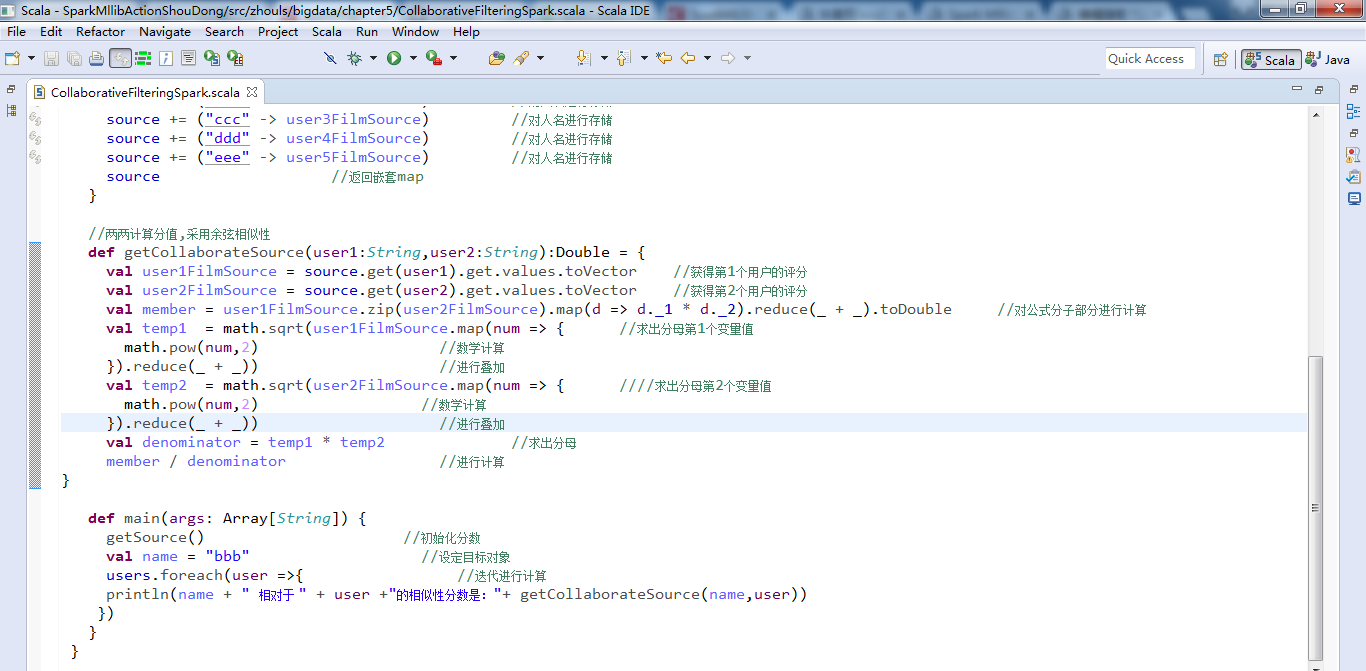
def main(args: Array[String]) {
getSource() //初始化分数
val name = "bbb" //设定目标对象
users.foreach(user =>{ //迭代进行计算
println(name + " 相对于 " + user +"的相似性分数是:"+ getCollaborateSource(name,user))
})
}
}
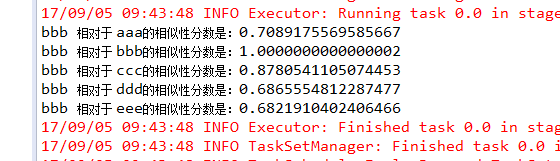
bbb 相对于 aaa的相似性分数是:0.7089175569585667
bbb 相对于 bbb的相似性分数是:1.0000000000000002
bbb 相对于 ccc的相似性分数是:0.8780541105074453
bbb 相对于 ddd的相似性分数是:0.6865554812287477
bbb 相对于 eee的相似性分数是:0.6821910402406466
当然,这里大家也可以进一步修改程序。
CollaborativeFilteringSpark.scala
package zhouls.bigdata.chapter5
import org.apache.spark.{SparkConf, SparkContext}
import scala.collection.mutable.Map
object CollaborativeFilteringSpark {
val conf = new SparkConf().setMaster("local").setAppName("CollaborativeFilteringSpark ") //设置环境变量
val sc = new SparkContext(conf) //实例化环境
val users = sc.parallelize(Array("aaa","bbb","ccc","ddd","eee")) //设置用户
val films = sc.parallelize(Array("smzdm","ylxb","znh","nhsc","fcwr")) //设置电影名
val source = Map[String,Map[String,Int]]() //使用一个source嵌套map作为姓名电影名和分值的存储
val filmSource = Map[String,Int]() //设置一个用以存放电影分的map
def getSource(): Map[String,Map[String,Int]] = { //设置电影评分
val user1FilmSource = Map("smzdm" -> ,"ylxb" -> ,"znh" -> ,"nhsc" -> ,"fcwr" -> )
val user2FilmSource = Map("smzdm" -> ,"ylxb" -> ,"znh" -> ,"nhsc" -> ,"fcwr" -> )
val user3FilmSource = Map("smzdm" -> ,"ylxb" -> ,"znh" -> ,"nhsc" -> ,"fcwr" -> )
val user4FilmSource = Map("smzdm" -> ,"ylxb" -> ,"znh" -> ,"nhsc" -> ,"fcwr" -> )
val user5FilmSource = Map("smzdm" -> ,"ylxb" -> ,"znh" -> ,"nhsc" -> ,"fcwr" -> )
source += ("aaa" -> user1FilmSource) //对人名进行存储
source += ("bbb" -> user2FilmSource) //对人名进行存储
source += ("ccc" -> user3FilmSource) //对人名进行存储
source += ("ddd" -> user4FilmSource) //对人名进行存储
source += ("eee" -> user5FilmSource) //对人名进行存储
source //返回嵌套map
}
//两两计算分值,采用余弦相似性
def getCollaborateSource(user1:String,user2:String):Double = {
val user1FilmSource = source.get(user1).get.values.toVector //获得第1个用户的评分
val user2FilmSource = source.get(user2).get.values.toVector //获得第2个用户的评分
val member = user1FilmSource.zip(user2FilmSource).map(d => d._1 * d._2).reduce(_ + _).toDouble //对公式分子部分进行计算
val temp1 = math.sqrt(user1FilmSource.map(num => { //求出分母第1个变量值
math.pow(num,) //数学计算
}).reduce(_ + _)) //进行叠加
val temp2 = math.sqrt(user2FilmSource.map(num => { ////求出分母第2个变量值
math.pow(num,) //数学计算
}).reduce(_ + _)) //进行叠加
val denominator = temp1 * temp2 //求出分母
member / denominator //进行计算
}
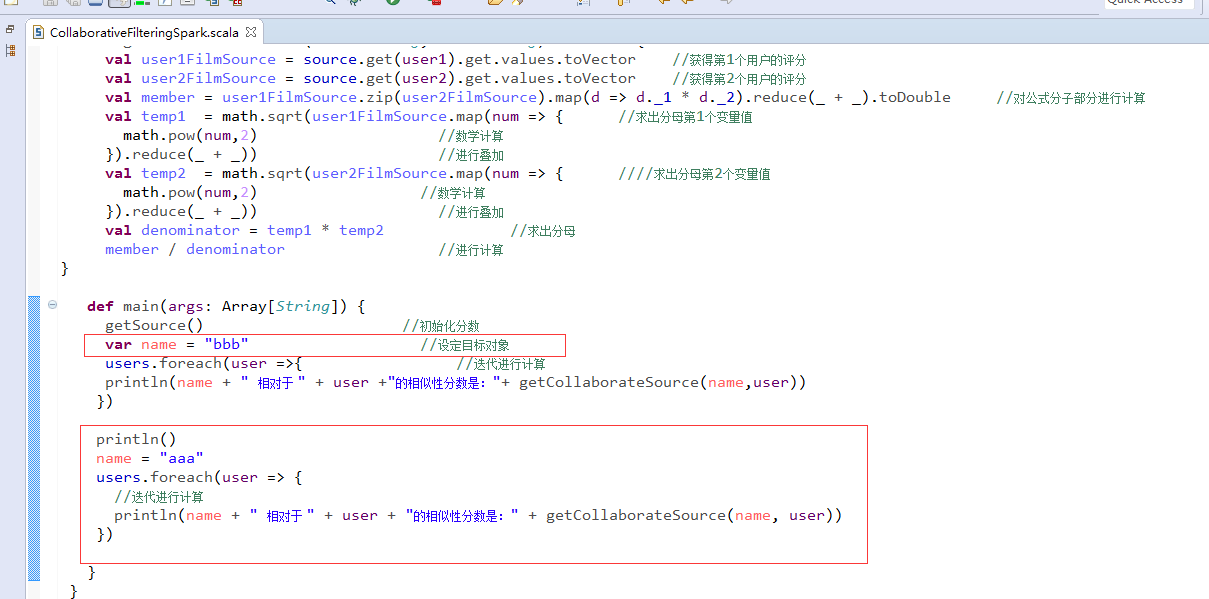
def main(args: Array[String]) {
getSource() //初始化分数
var name = "bbb" //设定目标对象
users.foreach(user =>{ //迭代进行计算
println(name + " 相对于 " + user +"的相似性分数是:"+ getCollaborateSource(name,user))
})
println()
name = "aaa"
users.foreach(user => {
//迭代进行计算
println(name + " 相对于 " + user + "的相似性分数是:" + getCollaborateSource(name, user))
})
}
}

或者,也可以写下程序,如下
UserSimilar.scala
package zhouls.bigdata
import org.apache.log4j.{Level, Logger}
import org.apache.spark.{SparkContext, SparkConf}
import scala.collection.mutable.Map
object UserSimilar {
//屏蔽不必要的日志显示在终端上
Logger.getLogger("org.apache.spark").setLevel(Level.WARN)
Logger.getLogger("org.apache.eclipse.jetty.server").setLevel(Level.OFF)
//程序入口
val conf = new SparkConf().setMaster("local[1]").setAppName(this.getClass().getSimpleName().filter(!_.equals('$')))
println(this.getClass().getSimpleName().filter(!_.equals('$')))
val sc = new SparkContext(conf)
//设置用户名
val users = sc.parallelize(Array("张三", "李四", "王五", "赵六", "阿七"))
//设置电影名
val films = sc.parallelize(Array("逆战", "人间", "鬼屋", "西游记", "雪豹"))
//使用一个source嵌套map作为姓名电影名和分值的存储
val source = Map[String, Map[String, Int]]()
//设置一个用以存放电影分的map
val filmSource = Map[String, Int]()
def getSource(): Map[String, Map[String, Int]] = {
//设置电影评分
val user1FilmSource = Map("逆战" -> , "人间" -> , "鬼屋" -> , "西游记" -> , "雪豹" -> )
val user2FilmSource = Map("逆战" -> , "人间" -> , "鬼屋" -> , "西游记" -> , "雪豹" -> )
val user3FilmSource = Map("逆战" -> , "人间" -> , "鬼屋" -> , "西游记" -> , "雪豹" -> )
val user4FilmSource = Map("逆战" -> , "人间" -> , "鬼屋" -> , "西游记" -> , "雪豹" -> )
val user5FilmSource = Map("逆战" -> , "人间" -> , "鬼屋" -> , "西游记" -> , "雪豹" -> )
//对人名进行储存
source += ("张三" -> user1FilmSource)
source += ("李四" -> user2FilmSource)
source += ("王五" -> user3FilmSource)
source += ("赵六" -> user4FilmSource)
source += ("阿七" -> user5FilmSource)
//返回嵌套map
source
}
//两两计算分值,采用余弦相似性
def getCollaborateSource(user1: String, user2: String): Double = {
//获得1,2两个用户的评分
val user1FilmSource = source.get(user1).get.values.toVector
val user2FilmSource = source.get(user2).get.values.toVector
//对公式部分分子进行计算
val member = user1FilmSource.zip(user2FilmSource).map(d => d._1 * d._2).reduce(_ + _).toDouble
//求出分母第一个变量值
val temp1 = math.sqrt(user1FilmSource.map(num => {math.pow(num, )}).reduce(_ + _))
//求出分母第二个变量值
val temp2 = math.sqrt(user2FilmSource.map(num => {math.pow(num, )}).reduce(_ + _))
//求出分母
val denominator = temp1 * temp2
//进行计算
member / denominator
}
def main(args: Array[String]) {
//初始化分数
getSource()
val name1 = "张三"
val name2 = "李四"
val name3 = "王五"
val name4 = "赵六"
val name5 = "阿七"
users.foreach(user => {
println(name1 + " 相对于 " + user + " 的相似性分数是 " + getCollaborateSource(name1, user) )
})
println("--------------------------------------------------------------------------")
users.foreach(user => {
println(name2 + " 相对于 " + user + " 的相似性分数是 " + getCollaborateSource(name2, user) )
})
println("--------------------------------------------------------------------------")
users.foreach(user => {
println(name3 + " 相对于 " + user + " 的相似性分数是 " + getCollaborateSource(name3, user) )
})
println("--------------------------------------------------------------------------")
users.foreach(user => {
println(name4 + " 相对于 " + user + " 的相似性分数是 " + getCollaborateSource(name4, user) )
})
println("--------------------------------------------------------------------------")
users.foreach(user => {
println(name5 + " 相对于 " + user + " 的相似性分数是 " + getCollaborateSource(name5, user) )
})
}
}
结果是
"C:\Program Files\Java\jdk1.8.0_77\bin\java" -Didea.launcher.port= "-Didea.launcher.bin.path=D:\Program Files (x86)\JetBrains\IntelliJ IDEA 15.0.5\bin" -Dfile.encoding=UTF- -classpath "C:\Program Files\Java\jdk1.8.0_77\jre\lib\charsets.jar;C:\Program Files\Java\jdk1.8.0_77\jre\lib\deploy.jar;C:\Program Files\Java\jdk1.8.0_77\jre\lib\ext\access-bridge-64.jar;C:\Program Files\Java\jdk1.8.0_77\jre\lib\ext\cldrdata.jar;C:\Program Files\Java\jdk1.8.0_77\jre\lib\ext\dnsns.jar;C:\Program Files\Java\jdk1.8.0_77\jre\lib\ext\jaccess.jar;C:\Program Files\Java\jdk1.8.0_77\jre\lib\ext\jfxrt.jar;C:\Program Files\Java\jdk1.8.0_77\jre\lib\ext\localedata.jar;C:\Program Files\Java\jdk1.8.0_77\jre\lib\ext\nashorn.jar;C:\Program Files\Java\jdk1.8.0_77\jre\lib\ext\sunec.jar;C:\Program Files\Java\jdk1.8.0_77\jre\lib\ext\sunjce_provider.jar;C:\Program Files\Java\jdk1.8.0_77\jre\lib\ext\sunmscapi.jar;C:\Program Files\Java\jdk1.8.0_77\jre\lib\ext\sunpkcs11.jar;C:\Program Files\Java\jdk1.8.0_77\jre\lib\ext\zipfs.jar;C:\Program Files\Java\jdk1.8.0_77\jre\lib\javaws.jar;C:\Program Files\Java\jdk1.8.0_77\jre\lib\jce.jar;C:\Program Files\Java\jdk1.8.0_77\jre\lib\jfr.jar;C:\Program Files\Java\jdk1.8.0_77\jre\lib\jfxswt.jar;C:\Program Files\Java\jdk1.8.0_77\jre\lib\jsse.jar;C:\Program Files\Java\jdk1.8.0_77\jre\lib\management-agent.jar;C:\Program Files\Java\jdk1.8.0_77\jre\lib\plugin.jar;C:\Program Files\Java\jdk1.8.0_77\jre\lib\resources.jar;C:\Program Files\Java\jdk1.8.0_77\jre\lib\rt.jar;G:\location\spark-mllib\out\production\spark-mllib;C:\Program Files (x86)\scala\lib\scala-actors-migration.jar;C:\Program Files (x86)\scala\lib\scala-actors.jar;C:\Program Files (x86)\scala\lib\scala-library.jar;C:\Program Files (x86)\scala\lib\scala-reflect.jar;C:\Program Files (x86)\scala\lib\scala-swing.jar;G:\home\download\spark-1.6.1-bin-hadoop2.6\lib\datanucleus-api-jdo-3.2.6.jar;G:\home\download\spark-1.6.1-bin-hadoop2.6\lib\datanucleus-core-3.2.10.jar;G:\home\download\spark-1.6.1-bin-hadoop2.6\lib\datanucleus-rdbms-3.2.9.jar;G:\home\download\spark-1.6.1-bin-hadoop2.6\lib\spark-1.6.1-yarn-shuffle.jar;G:\home\download\spark-1.6.1-bin-hadoop2.6\lib\spark-assembly-1.6.1-hadoop2.6.0.jar;G:\home\download\spark-1.6.1-bin-hadoop2.6\lib\spark-examples-1.6.1-hadoop2.6.0.jar;D:\Program Files (x86)\JetBrains\IntelliJ IDEA 15.0.5\lib\idea_rt.jar" com.intellij.rt.execution.application.AppMain mllib.CollaborativeFilteringSpark
CollaborativeFilteringSpark
Using Spark's default log4j profile: org/apache/spark/log4j-defaults.properties
SLF4J: Class path contains multiple SLF4J bindings.
SLF4J: Found binding in [jar:file:/G:/home/download/spark-1.6.-bin-hadoop2./lib/spark-assembly-1.6.-hadoop2.6.0.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: Found binding in [jar:file:/G:/home/download/spark-1.6.-bin-hadoop2./lib/spark-examples-1.6.-hadoop2.6.0.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation.
SLF4J: Actual binding is of type [org.slf4j.impl.Log4jLoggerFactory]
// :: INFO Slf4jLogger: Slf4jLogger started
// :: INFO Remoting: Starting remoting
// :: INFO Remoting: Remoting started; listening on addresses :[akka.tcp://sparkDriverActorSystem@192.168.1.100:8380]
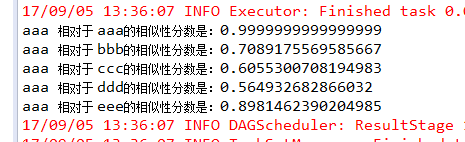
张三 相对于 张三 的相似性分数是 0.9999999999999999
张三 相对于 李四 的相似性分数是 0.7089175569585667
张三 相对于 王五 的相似性分数是 0.6055300708194983
张三 相对于 赵六 的相似性分数是 0.564932682866032
张三 相对于 阿七 的相似性分数是 0.8981462390204985
--------------------------------------------------------------------------
李四 相对于 张三 的相似性分数是 0.7089175569585667
李四 相对于 李四 的相似性分数是 1.0000000000000002
李四 相对于 王五 的相似性分数是 0.8780541105074453
李四 相对于 赵六 的相似性分数是 0.6865554812287477
李四 相对于 阿七 的相似性分数是 0.6821910402406466
--------------------------------------------------------------------------
王五 相对于 张三 的相似性分数是 0.6055300708194983
王五 相对于 李四 的相似性分数是 0.8780541105074453
王五 相对于 王五 的相似性分数是 1.0
王五 相对于 赵六 的相似性分数是 0.7774630169639036
王五 相对于 阿七 的相似性分数是 0.7416198487095662
--------------------------------------------------------------------------
赵六 相对于 张三 的相似性分数是 0.564932682866032
赵六 相对于 李四 的相似性分数是 0.6865554812287477
赵六 相对于 王五 的相似性分数是 0.7774630169639036
赵六 相对于 赵六 的相似性分数是 1.0
赵六 相对于 阿七 的相似性分数是 0.738024966423108
--------------------------------------------------------------------------
阿七 相对于 张三 的相似性分数是 0.8981462390204985
阿七 相对于 李四 的相似性分数是 0.6821910402406466
阿七 相对于 王五 的相似性分数是 0.7416198487095662
阿七 相对于 赵六 的相似性分数是 0.738024966423108
阿七 相对于 阿七 的相似性分数是 0.9999999999999998
// :: INFO RemoteActorRefProvider$RemotingTerminator: Shutting down remote daemon. Process finished with exit code
Spark Mllib里相似度度量(基于余弦相似度计算不同用户之间相似性)(图文详解)的更多相关文章
- Spark Mllib里如何删除每一条数据中所有的双引号“”(图文详解)
不多说,直接上干货! 具体,见 Hadoop+Spark大数据巨量分析与机器学习整合开发实战的第13章 使用决策树二元分类算法来预测分类StumbleUpon数据集
- 全网最全的Windows下Anaconda2 / Anaconda3里正确下载安装OpenCV(离线方式和在线方式)(图文详解)
不多说,直接上干货! 说明: Anaconda2-5.0.0-Windows-x86_64.exe安装下来,默认的Python2.7 Anaconda3-4.2.0-Windows-x86_64.ex ...
- 全网最详细的Windows系统里Oracle 11g R2 Client(64bit)的下载与安装(图文详解)
不多说,直接上干货! 环境: windows10系统(64位) 最好先安装jre或jdk(此软件用来打开oracle自带的可视化操作界面,不装也没关系:可以安装plsql,或者直接用命令行操作) Or ...
- 全网最详细的CentOS7里如何安装MySQL(得改为替换安装MariaDB)(图文详解)
不多说,直接上干货! 直接yum install mysql的话会报错,原因在于yum安装库里没有直接可以用的安装包,此时需要用到MariaDB了,MariaDB是MySQL社区开发的分支,也是一个增 ...
- Spark Mllib里的如何对单个数据集用斯皮尔曼计算相关系数
不多说,直接上干货! import org.apache.spark.mllib.stat.Statistics 具体,见 Spark Mllib机器学习实战的第4章 Mllib基本数据类型和Mlli ...
- Spark Mllib里如何将trainDara训练数据文件里第一行是字段名不是数据给删除掉(图文详解)
不多说,直接上干货! 具体,见 Hadoop+Spark大数据巨量分析与机器学习整合开发实战的第13章 使用决策树二元分类算法来预测分类StumbleUpon数据集
- CentOS系统里如何正确取消或者延长屏幕保护自动锁屏功能(图文详解)
不多说,直接上干货! 对于我这里想说的是,分别从CentOS6.X 和 CentOS7.X来谈及. 1. 问题:默认启动屏幕保护 问题描述: CentOS系统在用户闲置一段时间(默认为5分钟)后, ...
- Windows里安装wireshark或者ethereal工具(包括汉化破解)(图文详解)
不多说,直接上干货! https://www.wireshark.org/download.html 我这里,读取的是,来自于https://www.ll.mit.edu/ideval/data/19 ...
- Snort里如何将读取的包记录存到二进制tcpdump文件下(图文详解)
不多说,直接上干货! 如果网络速度很快,或者想使日志更加紧凑以便以后的分析,那么应该使用二进制的日志文件格式.如tcpdump格式或者pcap格式. 这里,我们不需指定本地网络了,因为所以的东西都被 ...
随机推荐
- Poj1207 The 3n + 1 problem(水题(数据)+陷阱)
一.Description Problems in Computer Science are often classified as belonging to a certain class of p ...
- Jetson TX2火力全开
Jetson Tegra系统的应用涵盖越来越广,相应用户对性能和功耗的要求也呈现多样化.为此NVIDIA提供一种新的命令行工具,可以方便地让用户配置CPU状态,以最大限度地提高不同场景下的性能和能耗. ...
- RabbitMQ队列,Redis\Memcached缓存
RabbitMQ RabbitMQ是一个在AMQP基础上完整的,可复用的企业消息系统. MQ全称Message Queue,消息队列(MQ)是一种应用程序对应用程序的通信方式.应用程序通过读写出入队列 ...
- 【转】 Pro Android学习笔记(六七):HTTP服务(1):HTTP GET
目录(?)[-] HTTP GET小例子 简单小例子 出现异常NetworkOnMainThreadException 通过StrictMode进行处理 URL带键值对 Andriod应用可利用ser ...
- SEO优化-伪静态-URLRewrite 详解
下面是文章是我在网上看到的,觉得写的还不错,我拿过来,修改了一些作者没有说到的地方....... 1. 在apache中配置 2. 用URLRewrite(详细:重点是UrlRewrite+Strut ...
- JSP介绍(4)--- JSP 过滤器
过滤器是可用于 Servlet 编程的 Java 类,可以实现以下目的: 在客户端的请求访问后端资源之前,拦截这些请求. 在服务器的响应发送回客户端之前,处理这些响应. 过滤器通过 Web 部署描述符 ...
- IIS备份和还原
当我们电脑系统有大量的站点和虚拟目录的时候,电脑因为种种原因需要重做系统,那么重装系统后这些站点我们是否只能一个一个的添加,如果有成百上千个站点呢,任务量可想而知,本文将介绍如何备份和还原window ...
- PWA PSI statusingclient.UpdateStatus更新任务页面的AssnCustomFields的TextValue值
1.注意Changesxml格式和下面一定要一样 2.CustomFieldGuid和CustomFieldName都不能少,自定义域的uid和name其中uid或者是MD_PROP_UID_SECO ...
- ViewPageIndicator--仿网易的使用
仿微信(网易的界面) 第一步: AndroidManifest.xml 的配置 <?xml version="1.0" encoding="utf-8"? ...
- ascII、iso、utf-8、Unicode的区别
utf-8和Unicode到底有什么区别?是存储方式不同?编码方式不同?它们看起来似乎很相似,但是实际上他们并不是同一个层次的概念,utf-8是unicode的实现方式. 要想先讲清楚他们的区别,首先 ...