一步一步理解GB、GBDT、xgboost
GBDT和xgboost在竞赛和工业界使用都非常频繁,能有效的应用到分类、回归、排序问题,虽然使用起来不难,但是要能完整的理解还是有一点麻烦的。本文尝试一步一步梳理GB、GBDT、xgboost,它们之间有非常紧密的联系,GBDT是以决策树(CART)为基学习器的GB算法,xgboost扩展和改进了GDBT,xgboost算法更快,准确率也相对高一些。
1. Gradient boosting(GB)
机器学习中的学习算法的目标是为了优化或者说最小化loss Function, Gradient boosting的思想是迭代生多个(M个)弱的模型,然后将每个弱模型的预测结果相加,后面的模型Fm+1(x)基于前面学习模型的Fm(x)的效果生成的,关系如下:


GB算法的思想很简单,关键是怎么生成h(x)?
如果目标函数是回归问题的均方误差,很容易想到最理想的h(x)应该是能够完全拟合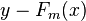 ,这就是常说基于残差的学习。残差学习在回归问题中可以很好的使用,但是为了一般性(分类,排序问题),实际中往往是基于loss Function 在函数空间的的负梯度学习,对于回归问题
,这就是常说基于残差的学习。残差学习在回归问题中可以很好的使用,但是为了一般性(分类,排序问题),实际中往往是基于loss Function 在函数空间的的负梯度学习,对于回归问题 残差和负梯度也是相同的。
残差和负梯度也是相同的。 中的f,不要理解为传统意义上的函数,而是一个函数向量
中的f,不要理解为传统意义上的函数,而是一个函数向量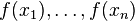 ,向量中元素的个数与训练样本的个数相同,因此基于Loss Function函数空间的负梯度的学习也称为“伪残差”。
,向量中元素的个数与训练样本的个数相同,因此基于Loss Function函数空间的负梯度的学习也称为“伪残差”。
GB算法的步骤:
1.初始化模型为常数值:

2.迭代生成M个基学习器
1.计算伪残差

2.基于 生成基学习器
生成基学习器
3.计算最优的

4.更新模型

2. Gradient boosting Decision Tree(GBDT)
GB算法中最典型的基学习器是决策树,尤其是CART,正如名字的含义,GBDT是GB和DT的结合。要注意的是这里的决策树是回归树,GBDT中的决策树是个弱模型,深度较小一般不会超过5,叶子节点的数量也不会超过10,对于生成的每棵决策树乘上比较小的缩减系数(学习率<0.1),有些GBDT的实现加入了随机抽样(subsample 0.5<=f <=0.8)提高模型的泛化能力。通过交叉验证的方法选择最优的参数。因此GBDT实际的核心问题变成怎么基于使用CART回归树生成?
CART分类树在很多书籍和资料中介绍比较多,但是再次强调GDBT中使用的是回归树。作为对比,先说分类树,我们知道CART是二叉树,CART分类树在每次分枝时,是穷举每一个feature的每一个阈值,根据GINI系数找到使不纯性降低最大的的feature以及其阀值,然后按照feature<=阈值,和feature>阈值分成的两个分枝,每个分支包含符合分支条件的样本。用同样方法继续分枝直到该分支下的所有样本都属于统一类别,或达到预设的终止条件,若最终叶子节点中的类别不唯一,则以多数人的类别作为该叶子节点的性别。回归树总体流程也是类似,不过在每个节点(不一定是叶子节点)都会得一个预测值,以年龄为例,该预测值等于属于这个节点的所有人年龄的平均值。分枝时穷举每一个feature的每个阈值找最好的分割点,但衡量最好的标准不再是GINI系数,而是最小化均方差--即(每个人的年龄-预测年龄)^2 的总和 / N,或者说是每个人的预测误差平方和 除以 N。这很好理解,被预测出错的人数越多,错的越离谱,均方差就越大,通过最小化均方差能够找到最靠谱的分枝依据。分枝直到每个叶子节点上人的年龄都唯一(这太难了)或者达到预设的终止条件(如叶子个数上限),若最终叶子节点上人的年龄不唯一,则以该节点上所有人的平均年龄做为该叶子节点的预测年龄。
3. Xgboost
Xgboost是GB算法的高效实现,xgboost中的基学习器除了可以是CART(gbtree)也可以是线性分类器(gblinear)。下面所有的内容来自原始paper,包括公式。
(1). xgboost在目标函数中显示的加上了正则化项,基学习为CART时,正则化项与树的叶子节点的数量T和叶子节点的值有关。
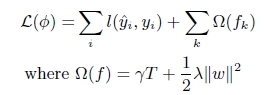
(2). GB中使用Loss Function对f(x)的一阶导数计算出伪残差用于学习生成fm(x),xgboost不仅使用到了一阶导数,还使用二阶导数。
第t次的loss:
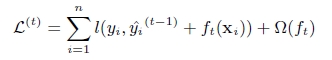
对上式做二阶泰勒展开:g为一阶导数,h为二阶导数
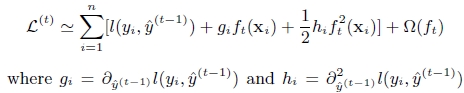
(3). 上面提到CART回归树中寻找最佳分割点的衡量标准是最小化均方差,xgboost寻找分割点的标准是最大化,lamda,gama与正则化项相关
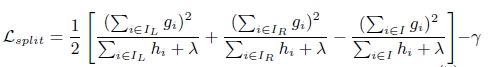
xgboost算法的步骤和GB基本相同,都是首先初始化为一个常数,gb是根据一阶导数ri,xgboost是根据一阶导数gi和二阶导数hi,迭代生成基学习器,相加更新学习器。
xgboost与gdbt除了上述三点的不同,xgboost在实现时还做了许多优化:
- 在寻找最佳分割点时,考虑传统的枚举每个特征的所有可能分割点的贪心法效率太低,xgboost实现了一种近似的算法。大致的思想是根据百分位法列举几个可能成为分割点的候选者,然后从候选者中根据上面求分割点的公式计算找出最佳的分割点。
- xgboost考虑了训练数据为稀疏值的情况,可以为缺失值或者指定的值指定分支的默认方向,这能大大提升算法的效率,paper提到50倍。
- 特征列排序后以块的形式存储在内存中,在迭代中可以重复使用;虽然boosting算法迭代必须串行,但是在处理每个特征列时可以做到并行。
- 按照特征列方式存储能优化寻找最佳的分割点,但是当以行计算梯度数据时会导致内存的不连续访问,严重时会导致cache miss,降低算法效率。paper中提到,可先将数据收集到线程内部的buffer,然后再计算,提高算法的效率。
- xgboost 还考虑了当数据量比较大,内存不够时怎么有效的使用磁盘,主要是结合多线程、数据压缩、分片的方法,尽可能的提高算法的效率。
参考资料:
2. XGBoost: A Scalable Tree Boosting System
3. 陈天奇的slides
一步一步理解GB、GBDT、xgboost的更多相关文章
- 一步一步理解Paxos算法
一步一步理解Paxos算法 背景 Paxos 算法是Lamport于1990年提出的一种基于消息传递的一致性算法.由于算法难以理解起初并没有引起人们的重视,使Lamport在八年后重新发表到 TOCS ...
- 一步一步的理解C++STL迭代器
一步一步的理解C++STL迭代器 "指针"对全部C/C++的程序猿来说,一点都不陌生. 在接触到C语言中的malloc函数和C++中的new函数后.我们也知道这两个函数返回的都是一 ...
- 一步一步理解 python web 框架,才不会从入门到放弃 -- 开始使用 Django
背景知识 要使用 Django,首先必须先安装 Django. 下图是 Django 官网的版本支持,我们可以看到上面有一个 LTS 存在.什么是 LTS 呢?LTS ,long-term suppo ...
- 一步一步理解线段树——转载自JustDoIT
一步一步理解线段树 目录 一.概述 二.从一个例子理解线段树 创建线段树 线段树区间查询 单节点更新 区间更新 三.线段树实战 -------------------------- 一 概述 线段 ...
- NLP(二十九)一步一步,理解Self-Attention
本文大部分内容翻译自Illustrated Self-Attention, Step-by-step guide to self-attention with illustrations and ...
- 一步一步理解word2Vec
一.概述 关于word2vec,首先需要弄清楚它并不是一个模型或者DL算法,而是描述从自然语言到词向量转换的技术.词向量化的方法有很多种,最简单的是one-hot编码,但是one-hot会有维度灾难的 ...
- 使用Python一步一步地来进行数据分析总结
原文链接:Step by step approach to perform data analysis using Python译文链接:使用Python一步一步地来进行数据分析--By Michae ...
- 一步一步搭建11gR2 rac+dg之安装rac出现问题解决(六)【转】
一步一步在RHEL6.5+VMware Workstation 10上搭建 oracle 11gR2 rac + dg 之安装rac出现的问题 (六) 本文转自 一步一步搭建11gR2 rac+dg之 ...
- 如何一步一步用DDD设计一个电商网站(九)—— 小心陷入值对象持久化的坑
阅读目录 前言 场景1的思考 场景2的思考 避坑方式 实践 结语 一.前言 在上一篇中(如何一步一步用DDD设计一个电商网站(八)—— 会员价的集成),有一行注释的代码: public interfa ...
随机推荐
- 隐藏chrome空白标签栏的最近访问
chrome版本: 29.0.1547.76 m 找到安装路径下Custom.css文件,添加.most-visited{display:none !important}来修改样式. 我的路径为:C: ...
- oracle Redhat64 安装
详细可以参考:http://blog.csdn.net/chenfeng898/article/details/8782679 直接执行如下yum安装命令后,如果再出错,跳到2 yum -y inst ...
- php中文汉字截取函数
public function substrgb($in,$num) { //$num=16; $pos=0; $bytenum=0; $out=""; while($num){ ...
- 分批次从musql取数据,每次取1000条
$t = new Gettags(); $num=$t->sum_tag(); $num=$num/1000; $flag_num=ceil($num); $flag_array=array() ...
- hdu 4632 Palindrome subsequence
http://acm.hdu.edu.cn/showproblem.php?pid=4632 简单DP 代码: #include<iostream> #include<cstdio& ...
- 二模 (2) day2
第一题: 题目描述: 在一个长方形框子里,最多有 N(0≤N≤6)个相异的点.在其中任何-个点上放一个很小的油滴,那么这个油滴会一直扩展,直到接触到其他油滴或者框子的边界.必须等一个油滴扩展完毕才能放 ...
- 一键制作u盘启动盘教程
第一步:制作完成u深度u盘启动盘 第二步:下载Ghost Win7系统镜像文件包,存入u盘启动盘 第三步:电脑模式更改成ahci模式,不然安装完成win7系统会出现蓝屏现象 正式安装步骤: u ...
- IT公司100题-7-判断两个链表是否相交
问题:有一个单链表,其中可能有一个环,也就是某个节点的next指向的是链表中在它之前的节点,这样在链表的尾部形成一环.1.如何判断一个链表是不是这类链表? 问题扩展:1.如果链表可能有环呢?2.如果需 ...
- HDU 5353
题目大意: 相邻的朋友可以给出自己手上最多一颗糖,n个朋友形成一个环,问给的方式能否最后使所有朋友都糖的数量相同 这里我用的是网络流来做的,这里n=100000,用sap的模板可以跑过 #includ ...
- 分布式一致性原理—BASE
定义 BASE是BasicallyAvailable(基本可用).Soft state(软状态)和Eventually consistent(最终一致性)三个短语的简写,是由来自eBay的架构师Dan ...