SQL Server-聚焦NOT EXISTS AND NOT IN性能分析(十五)
前言
上一节我们分析了INNER JOIN和IN,对于不同场景其性能是不一样的,本节我们接着分析NOT EXISTS和NOT IN,简短的内容,深入的理解,Always to review the basics。
初步探讨NOT EXISTS和NOT IN
NOT EXISTS和NOT IN有很大的不同,尤其是对NULL的处理,为何这样说,当子查询中有NULL时,此时NOT IN不会返回任何行,下面我们来看下简单的示例。
USE TSQL2012
GO WITH table1 AS
(
SELECT AS value
UNION ALL
SELECT NULL AS nullcol1
),
table2 AS
(
SELECT AS value
UNION ALL
SELECT NULL AS nullcol2
)
首先我们来通过NOT EXISTS来进行查询
SELECT * FROM table1 AS a
WHERE NOT EXISTS(SELECT * FROM table2 AS b WHERE a.value = b.value)

接下来我们再来进行NOT IN查询
SELECT * FROM table1 AS a
WHERE value NOT IN(SELECT * FROM table2)

为何会出现不一样的结果呢,我们来分析下EXISTS和IN,EXISTS使用的是两值谓词逻辑,也就说说EXISTS总是返回TRUE或者FALSE,绝对不会返回UNKNOWN,而IN使用的三值谓词逻辑即返回的是TRUE或者FALSE或者UNKNOWN。当我们进行NOT EXISTS查询时,此时用1和NULL两行数据,此时1与table2中的值进行等值比较,此时没有相同的返回FALSE,接着NOT EXISTS则返回TRUE,所以此时返回1,同理返回NULL,当利用上述NOT IN进行查询时,我们可以将上述进行如下等价
SELECT * FROM table1 AS a
WHERE value NOT IN(SELECT * FROM table2)
等价于
WHERE (
value != (SELECT value FROM table2 WHERE value = )
AND
value != (SELECT value FROM table2 WHERE value = NULL)
)
当value = 1时,此时则有TRUE AND UNKNOWN结果还是UNKNOWN,同理当value = NULL时也是返回UNKNOWN,所以最终结果都未匹配上没有任何数据返回。
进一步探讨NOT EXISTS和NOT IN
接下来我们来进行NOT EXISTS和NOT IN的性能分析,接下来我们通过三种情况来进行分析。
(1)未建立索引情况比较NOT EXISTS和NOT IN
我们还是利用上一节的BigTable和SmallerTable来进行测试。
USE TSQL2012
GO SELECT ID, SomeColumn FROM BigTable
WHERE SomeColumn NOT IN (SELECT LookupColumn FROM SmallerTable) SELECT ID, SomeColumn FROM BigTable
WHERE NOT EXISTS (SELECT LookupColumn FROM SmallerTable WHERE SmallerTable.LookupColumn = BigTable.SomeColumn)
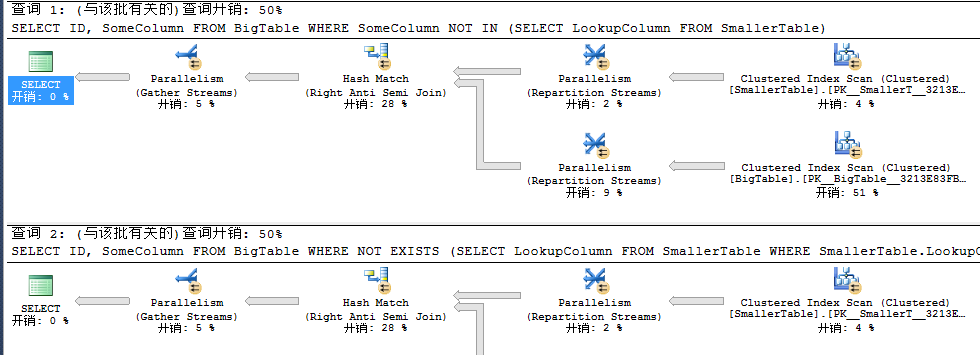
此时发现NOT EXISTS和NOT IN开销一致,解下来我们创建索引看看。
(2)创建索引比较NOT EXISTS和NOT IN
CREATE INDEX idx_BigTable_SomeColumn ON BigTable (SomeColumn)
CREATE INDEX idx_SmallerTable_LookupColumn ON SmallerTable (LookupColumn)
继续进行上述查询
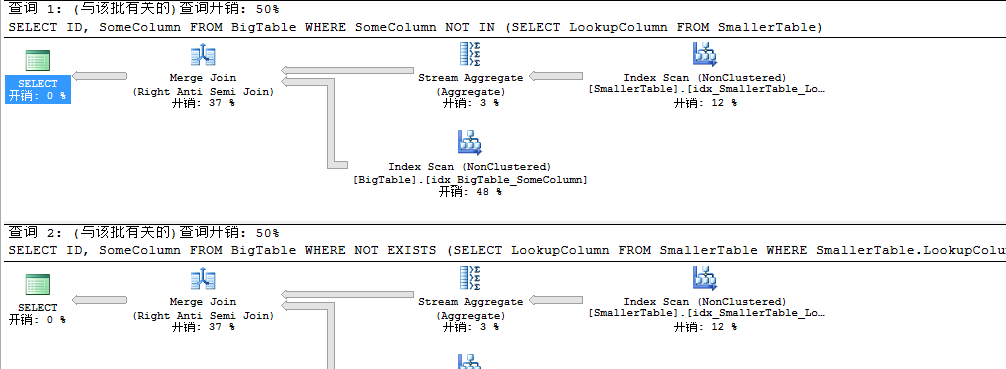
创建了索引结果还是一致和上一节我们讨论的INNER JOIN和IN的情况有点不太一样,即使是创建唯一非聚集索引二者性能开销还是一致。到这里我们是不是可以下结论说二者性能一致呢,我们继续往下看,不知道大家发现了没有我们在上一节开始时对查询列的约束是不为空的,那要是为空结果又会是怎样的呢,我们看看。
(3)将查询列修改为可空
我们将SomeTable表和SmallerTable表中的SomeCloumn和LookupColumn修改为可空
USE TSQL2012
GO ALTER TABLE BigTable
ALTER COLUMN SomeColumn UNIQUEIDENTIFIER NULL ALTER TABLE SmallerTable
ALTER COLUMN LookupColumn UNIQUEIDENTIFIER NULL
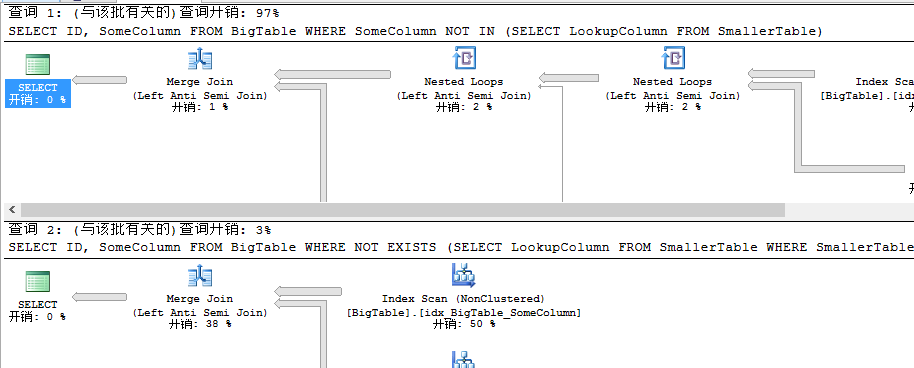
查询计划显示结果大大出乎我们意料,为什么将列修改为可空的,此时NOT IN的性能开销接近是NOT EXISTS的33倍,猜测的话数据量越大这个差距应该是越来越明显。不知道为何如此,反正查询计划是如此,欺骗不了我们。在SQL Server 2012基础教程后续中无意中看到这样一句话:对EXISTS来说它会过滤掉NULL值。是不是当列定义为NULL时,IN不会过滤掉NULL,而EXISTS即使定义为NULL也会被自然过滤呢,不得而知。通过上述我们明确知道,有时候将列定义为空会减少我们的不必要的判断,但是在NOT EXISTS和NOT IN比较中,此时通过定义为NULL将会得到巨大的差异,至此,我们可以得出如下结论。
NOT EXISTS和NOT IN性能分析结论:当将查询列定义为NULL时,NOT EXISTS比NOT IN性能要好很多,当定义为非NULL时此时二者查询开销一样。当然如没有特殊情况,还是建议将查询列定义为非NULL,这样既可以保证查询性能,也可以保证在使用过程中NOT IN的安全性,减少不必要的性能开销。
总结
本节我们详细探讨了NOT EXISTS和NOT IN的性能情况,下一节我们开始探讨EXIST和IN的性能分析,简短的内容,深入的理解,我们下节再会。
SQL Server-聚焦NOT EXISTS AND NOT IN性能分析(十五)的更多相关文章
- SQL Server中修改“用户自定义表类型”问题的分析与方法
前言 SQL Server开发过程中,为了传入数据集类型的变量(比如接受C#中的DataTable类型变量),需要定义"用户自定义表类型",通过"用户自定义表类型&quo ...
- SQL SERVER 2012 执行计划走嵌套循环导致性能问题的案例
开发人员遇到一个及其诡异的的SQL性能问题,这段完整SQL语句如下所示: declare @UserId INT declare @PSANo VAR ...
- [翻译]——SQL Server使用链接服务器的5个性能杀手
前言: 本文是对博客http://www.dbnewsfeed.com/2012/09/08/5-performance-killers-when-working-with-linked-server ...
- 在SQL Server 2016里使用查询存储进行性能调优
作为一个DBA,排除SQL Server问题是我们的职责之一,每个月都有很多人给我们带来各种不能解释却要解决的性能问题. 我就多次听到,以前的SQL Server的性能问题都还好且在正常范围内,但现在 ...
- 智能SQL优化工具--SQL Optimizer for SQL Server(帮助提升数据库应用程序性能,最大程度地自动优化你的SQL语句 )
SQL Optimizer for SQL Server 帮助提升数据库应用程序性能,最大程度地自动优化你的SQL语句 SQL Optimizer for SQL Server 让 SQL Serve ...
- SQL Server 手把手教你使用profile进行性能监控
200 ? "200px" : this.width)!important;} --> 介绍 经常会有人问profile工具该怎么使用?有没有方法获取性能差的sql的问题.自 ...
- SQL Server事务、隔离级别详解(二十九)
前言 事务一直以来是我最薄弱的环节,也是我打算重新学习SQL Server的出发点,关于SQL Server中事务将分为几节来进行阐述,Always to review the basics. 事务简 ...
- SQL Server 磁盘请求超时的833错误原因分析以及解决
本文出处:http://www.cnblogs.com/wy123/p/6984885.html 最近遇到一个SQL Server服务器响应极度缓慢,并且出现客户端请求报错的情况,在数据库中的erro ...
- SQL Server手把手教你使用profile进行性能监控
介绍 经常会有人问profile工具该怎么使用?有没有方法获取性能差的sql的问题.自从转mysql我自己也差不多2年没有使用profile,忽然profile变得有点生疏不得不重新熟悉一下.这篇文章 ...
随机推荐
- 关于.NET异常处理的思考
年关将至,对于大部分程序员来说,马上就可以闲下来一段时间了,然而在这个闲暇的时间里,唯有争论哪门语言更好可以消磨时光,估计最近会有很多关于java与.net的博文出现,我表示要作为一个吃瓜群众,静静的 ...
- svn 常用命令总结
svn 命令篇 svn pget svn:ignore // 查看忽略项 svn commit -m "提交说明" // 提交修改 svn up(update) // 获取最新版本 ...
- kafka学习笔记:知识点整理
一.为什么需要消息系统 1.解耦: 允许你独立的扩展或修改两边的处理过程,只要确保它们遵守同样的接口约束. 2.冗余: 消息队列把数据进行持久化直到它们已经被完全处理,通过这一方式规避了数据丢失风险. ...
- JS继承之原型继承
许多OO语言都支持两种继承方式:接口继承和实现继承.接口继承只继承方法签名,而实现继承则继承实际的方法.如前所述,由于函数没有签名,在ECMAScript中无法实现接口继承.ECMAScript只支 ...
- Boost信号/槽signals2
信号槽是Qt框架中一个重要的部分,主要用来解耦一组互相协作的类,使用起来非常方便.项目中有同事引入了第三方的信号槽机制,其实Boost本身就有信号/槽,而且Boost的模块相对来说更稳定. signa ...
- 【干货分享】流程DEMO-借款申请
流程名: 借款申请 业务描述: 当员工个人在工作中需要进行借款时,通过此项流程提交借款申请,审批通过后,财务部进行款项支付. 流程相关文件: 流程包.xml WebService业务服务.xm ...
- 学习C的笔记
[unsigned] 16位系统中一个int能存储的数据的范围为-32768~32767,而unsigned能存储的数据范围则是0~65535.由于在计算机中,整数是以补码形式存放的.根据最高位的不同 ...
- js实现四大经典排序算法
为了方便测试,这里写了一个创建长度为n的随机数组 function createArr(n) { var arr = []; while (n--) { arr.push(~~(Math.random ...
- jsp
-----------------
- grunt配置任务
这个指南解释了如何使用 Gruntfile 来为你的项目配置task.如果你还不知道 Gruntfile 是什么,请先阅读 快速入门 指南并看看这个Gruntfile 实例. Grunt配置 Grun ...