前端学HTTP之客户端识别和cookie
前面的话
Web服务器可能会同时与数千个不同的客户端进行对话。这些服务器通常要记录下它们在与谁交谈,而不会认为所有的请求都来自匿名的客户端。本文主要介绍客户端识别及cookie机制
HTTP首部
HTTP最初是一个匿名、无状态的请求/响应协议。服务器处理来自客户端的请求,然后向客户端回送一条响应。Web服务器几乎没有什么信息可以用来判定是哪个用户发送的请求,也无法记录来访用户的请求序列
Web站点希望能够提供个性化接触。它们希望对连接另一端的用户有更多的了解,并且能在用户浏览页面时对其进行跟踪。以购物网站为例,专门为用户生成的欢迎词和页面内容,使购物体验更加个性化;通过了解客户的兴趣,商店可以推荐一些它们认为客户会感兴趣的商品。商店还可以在临近客户生日或其他一些重要日子的时候提供生日特定的商品;在线购物的用户不喜欢一次又一次地填写繁琐的地址和信用卡信息。有些站点会将这些管理细节存储在一个数据库中。只要他们识别出用户,就可以使用存档的管理信息,使得购物体验更加便捷;HTTP事务是无状态的。每条请求/响应都是独立进行的。很多Web站点希望能在用户与站点交互的过程中(比如,使用在线购物车的时候)构建增量状态。要实现这一功能,Web站点就需要有一种方式来区分来自不同用户的HTTP事务
下表中给出了七种最常见的用来承载用户相关信息的HTTP请求首部

From首部包含了用户的E-mail地址。每个用户都有不同的E-mail地址,所以在理想情况下,可以将这个地址作为可行的源端来识别用户。但由于担心那些不讲道德的服务器会搜集这些E-mail地址,用于垃圾邮件的散发,所以很少有浏览器会发送From首部。实际上,From首部是由自动化的机器人或蜘蛛发送的,这样在出现问题时,网管还有个地方可以发送愤怒的投诉邮件
User-Agent首部可以将用户所用浏览器的相关信息告知服务器,包括程序的名称和版本,通常还包含操作系统的相关信息。要实现定制内容与特定的浏览器及其属性间的良好互操作时,这个首部是非常有用的,但它并没有为识别特定的用户提供太多有意义的帮助
下面是最新版本chrome发送的:
User-Agent:Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2883.75 Safari/537.36
Referer首部提供了用户来源页面的URL。Referer首部自身并不能完全标识用户,但它确实说明了用户之前访问过哪个页面。通过它可以更好地理解用户的浏览行为,以及用户的兴趣所在。比如,如果从一个篮球网站抵达某个Web服务器的,这个服务器可能会推断你是个篮球迷
但是,From、User-Agent和Referer首部都不足以实现可靠的识别
IP地址
早期Web曾尝试将客户端IP地址作为一种标识形式使用。如果每个用户都有不同的IP地址,IP地址(如果会发生变化的话)也很少会发生变化,而且Web服务器可以判断出每条请求的客户端IP地址的话,这种方案是可行的。通常在HTTP首部并不提供客户端的IP地址,但Web服务器可以找到承载HTTP请求的TCP连接另一端的IP地址
比如,在Unix系统中,函数调用getpeername就可以返回发送端机器的客户端IP地址:
status = getpeername(tcp_connection_socket,...);
但是,使用客户端IP地址来识别用户存在着很多缺点,限制了将其作为用户识别技术的效能。因为客户端IP地址描述的是所用的机器,而不是用户。如果多个用户共享同一台计算机,就无法对其进行区分了;很多因特网服务提供商都会在用户登录时为其动态分配IP地址。用户每次登录时,都会得到一个不同的地址,因此Web服务器不能假设IP地址可以在各登录会话之间标识用户;为了提高安全性,并对稀缺的地址资源进行管理,很多用户都是通过网络地址转换(Network Address Translation, NAT)防火墙来浏览网络内容的。这些NAT设备隐藏了防火墙后面那些实际客户端的IP地址,将实际的客户端IP地址转换成了一个共享的防火墙IP地址和不同的端口号;HTTP代理和网关通常会打开一些新的、到原始服务器的TCP连接。Web服务器看到的将是代理服务器的IP地址,而不是客户端的。有些代理为了绕过这个问题会添加特殊的Client-IP或X-Forwarded-For扩展首部来保存原始的IP地址,但并不是所有的代理都支持这种行为
有些Web站点仍然使用客户端IP地址在会话之间跟踪用户的行为,但这种站点并不多。无法用IP地址确定目标的地方太多了。少数站点甚至将客户端IP地址作为一种安全特性使用,它们只向来自特定IP地址的用户提供文档。在内部网络中可能可以这么做,但在因特网上就不行了,主要是因为因特网上IP地址太容易伪造了。路径上如果有拦截代理也会破坏此方案
用户登录
Web服务器无需被动地根据用户的IP地址来猜测他的身份,它可以要求用户通过用户名和密码进行认证登录来显式地询问用户是谁
为了使Web站点的登录更加简便,HTTP中包含了一种内建机制,可以用www- Authenticate首部和Authorization首部向Web站点传送用户的相关信息。一旦登录,浏览器就可以不断地在每条发往这个站点的请求中发送这个登录信息了。这样,就总是有登录信息可用了
如果服务器希望在为用户提供对站点的访问之前,先行登录,可以向浏览器回送一条HTTP响应代码401 Login Required。然后,浏览器会显示一个登录对话框,并用Authorization首部在下一条对服务器的请求中提供这些信息
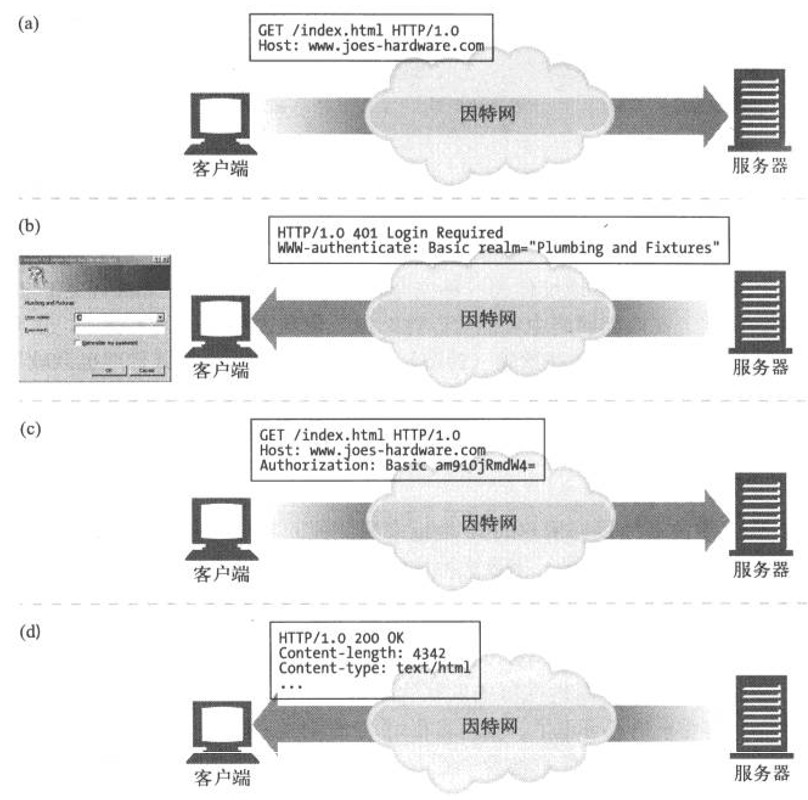
在图a中,浏览器对站点www.joes-hardware.com发起了一条请求;站点并不知道这个用户的身份,因此在图b中,服务器会返回401 Login Required HTTP响应码,并添加www-Authentication首部,要求用户登录。这样浏览器就会弹出一个登录对话框;只要用户输入了用户名和密码(对其身份进行完整性检査),浏览器就会重复原来的请求。这次它会添加一个Authorization首部,说明用户名和密码。对用户名和密码进行加密,防止那些有意无意的网络观察者看到;现在,服务器已经知道用户的身份了,今后的请求要使用用户名和密码时,浏览器会自动将存储下来的值发送出去,甚至在站点没有要求发送的时候也经常会向其发送。浏览器在每次请求中都向服务器发送Authorization首部作为一种身份的标识,这样,只要登录一次,就可以在整个会话期间维持用户的身份了
但是,登录多个Web站点是很繁琐的。从一个站点浏览到另一个站点的时候,需要在每个站点上登录。更糟的是,很可能要为不同的站点记住不同的用户名和密码。访问很多站点,喜欢的用户名可能已经被其他人用过了,而且有些站点为用户名和密码的长度和组成设置了不同的规则
胖URL
有些Web站点会为每个用户生成特定版本的URL来追踪用户的身份。通常,会对真正的URL进行扩展,在URL路径开始或结束的地方添加一些状态信息。用户浏览站点时,Web服务器会动态生成一些超链,继续维护URL中的状态信息
改动后包含了用户状态信息的URL被称为胖URL(fat URL)。下面是Amazon.com使用的一些胖URL实例。每个URL后面都附加了一个用户特有的标识码,在这个例子中就是002-1145265-8016838,这个标识码有助于在用户浏览商店内容时对其进行跟踪
<a href="/exec/obidos/tg/browse/-/229220/ref=gr_gifts/002-1145265-8016838">All Gifts</a><br>
<a href="/exec/obidos/wishlist/ref=gr_pll_/002-1145265-8016838">Wish List</a><br>
可以通过胖URL将Web服务器上若干个独立的HTTP事务捆绑成一个“会话”或“访问”。用户首次访问这个Web站点时,会生成一个唯一的ID,用服务器可以识别的方式将这个ID添加到URL中去,然后服务器就会将客户端重新导向这个胖URL。不论什么时候,只要服务器收到了对胖URL的请求,就可以去査找与那个用户ID相关的所有增量状态(购物车、简介等),然后重写所有的输出超链,使其成为胖URL,以维护用户的ID
可以在用户浏览站点时,用胖URL对其进行识别。但这种技术存在几个很严重的问题:丑陋的URL——浏览器中显示的胖URL会给新用户带来困扰;无法共享URL——胖URL中包含了与特定用户和会话有关的状态信息。如果将这个URL发送给其他人,可能就在无意中将个人信息都共享出去了;破坏缓存——为每个URL生成用户特有的版本就意味着不再有可供公共访问的URL需要缓存了;额外的服务器负荷——服务器需要重写HTML页面使URL变胖;逃逸口——用户跳转到其他站点或者请求一个特定的URL时,就很容易在无意中“逃离”胖URL会话,只有当用户严格地追随预先修改过的链接时,胖URL才能工作。如果用户逃离此链接,就会丢失他的进展(可能是一个已经装满了东西的购物车)信息,得重新开始;在会话间是非持久的,除非用户收藏了特定的胖URL,否则用户退出登录时,所有的信息都会丢失
cookie
cookie是当前识别用户,实现持久会话的最好方式。前面各种技术中存在的很多问题对它们都没什么影响,但是通常会将它们与那些技术共用,以实现额外的价值
cookie最初是由网景公司开发的,但现在所有主要的浏览器都支持它。cookie非常重要,而且它们定义了一些新的HTTP首部。cookie的存在也影响了缓存,大多数缓存和浏览器都不允许对任何cookie的内容进行缓存
【类型】
可以笼统地将cookie分为两类:会话cookie和持久cookie。会话cookie是一种临时cookie,它记录了用户访问站点时的设置和偏好。用户退出浏览器时,会话cookie就被删除了。持久cookie的生存时间更长一些,它们存储在硬盘上。浏览器退出,计算机重启时它们仍然存在。通常会用持久cookie维护某个用户会周期性访问的站点的配置文件或登录名
会话cookie和持久cookie之间唯一的区别就是它们的过期时间。如果设置了Discard参数,或者没有设置Expires或Max-Age参数来说明扩展的过期时间,这个cookie就是一个会话cookie
【工作机制】
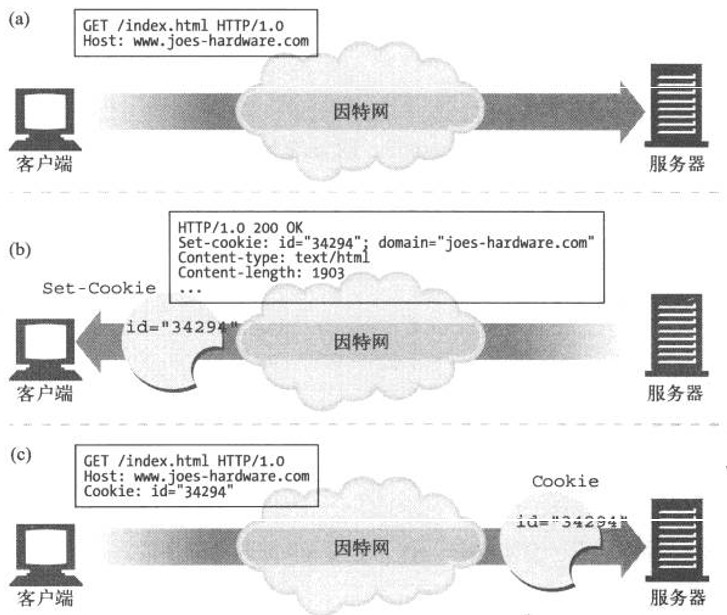
用户首次访问Web站点时,Web服务器对用户一无所知。Web服务器希望这个用户会再次回来,所以想给这个用户“拍上”一个独有的cookie,这样以后它就可以识别出这个用户了。cookie中包含了一个由名字=值(namezvalue)这样的信息构成的任意列表,并通过Set-Cookie或Set-Cookie2 HTTP响应(扩展)首部将其贴到用户身上去
cookie中可以包含任意信息,但它们通常都只包含一个服务器为了进行跟踪而产生的独特的识别码。比如,服务器会将一个表示id=”34294”的cookie贴到用户上去。服务器可以用这个数字来查找服务器为其访问者积累的数据库信息(购物历史、地址信息等)
但是,cookie并不仅限于ID号。很多Web服务器都会将信息直接保存在cookie中
Cookie: name "Brian Totty"; phone="555-1212"
浏览器会记住从服务器返回的Set-Cookie或Set-Cookie2首部中的cookie内容,并将cookie集存储在浏览器的cookie数据库中。将来用户返回同一站点时,浏览器会挑中那个服务器贴到用户上的那些cookie,并在一个cookie请求首部中将其传回去
【cookie罐:客户端的状态】
cookie的基本思想就是让浏览器积累一组服务器特有的信息,每次访问服务器时都将这些信息提供给它。因为浏览器要负责存储cookie信息,所以此系统被称为客户端侧状态(client-side state)。这个cookie规范的正式名称为HTTP状态管理机制(HTTP state management mechanism)
浏览器内部的cookie罐中可以有成百上千个cookie,但浏览器不会将每个cookie都发送给所有的站点。实际上,它们通常只向每个站点发送2-3个cookie。原因如下:对所有这些cookie字节进行传输会严重降低性能。浏览器实际传输的cookie字节数要比实际的内容字节数多;cookie中包含的是服务器特有的名值对,所以对大部分站点来说,大多数cookie都只是无法识别的无用数据;将所有的cookie发送给所有站点会引发潜在的隐私问题,那些不信任的站点也会获得只想发给其他站点的信息
总之,浏览器只向服务器发送服务器产生的那些cookie。joes-hardware.com产生的cookie会被发送给joes-hardware.com,不会发送给bobs-books.com或marys-movies.com
很多Web站点都会与第三方厂商达成协议,由其来管理广告。这些广告被做得像Web站点的一个组成部分,而且它们确实发送了持久cookie。用户访问另一个由同一广告公司提供服务的站点时,由于域是匹配的,浏览器就会再次回送早先设置的持久cookie。营销公司可以将此技术与Referer首部结合,暗地里构建一个用户档案和浏览习惯的详尽数据集。现代的浏览器都允许用户对隐私特性进行设置,以限制第三方cookie的使用
1、cookie的域属性
产生cookie的服务器可以向Set-Cookie响应首部添加一个Domain属性来控制哪些站点可以看到那个cookie。比如,下面的HTTP响应首部就是在告诉浏览器将cookie user= "maryl7"发送给域".airtravelbargains.com"的所有站点
Set-cookie: user="maryl7"; domain="airtravelbargains.com"
如果用户访问的是www.airtravelbargains.com、specials.airtravelbargains.com或任意以.airtravelbargains.com结尾的站点,下列Cookie首部都会被发布出去:
Cookie: user="maryl7"
2、cookie路径属性
cookie规范甚至允许用户将cookie与部分Web站点关联起来。可以通过Path属性来实现这一功能,在这个属性列出的URL路径前缀下所有cookie都是有效的
例如,某个Web服务器可能是由两个组织共享的,每个姐织都有独立的cookie。站点www.airtravelbargains.com可能会将部分Web站点用于汽车租赁——比如,http://www.airtravelbargains.com/autos/——用一个独立的cookie来记录用户喜欢的汽车尺寸。可能会生成一个如下所示的特殊汽车租赁cookie:
Set-cookie: pref=compact; domain="airtravelbargains.com"; path=/autos/
如果用户访问http://www.airtravelbargains.com/specials.html,就只会获得这个cookie:
Cookie: user="maryl7"
但如果访问http://www.airtravelbargains.com/autos/cheapo/index.html,就会获得这两个cookie:
Cookie: user="maryl7"
Cookie: pref=compact
因此,cookie就是由服务器贴到客户端上,由客户端维护的状态片段,只会回送给那些合适的站点。下面我们来更仔细地看看cookie的技术和标准
【cookie成分】
现在使用的cookie规范有两个不同的版本:cookies版本0(有时被称为Netscape cookies)和cookies版本1(RFC 2965)。cookies版本1 是对cookies版本0的扩展,应用不如后者广泛
1、Cookies版本0
最初的cookie规范是由网景公司定义的,这些“版本0”的cookie定义了set-Cookie响应首部、cookie请求首部以及用于控制cookie的字段
Set-Cookie: name-value[;expires=date][;path=path][;domain=domain][;secure]
Cookie: name1-value1[; name2=value2]...
Set-Cookie首部有一个强制性的cookie名和cookie值。后面跟着可选的cookie属性,中间由分号分隔


客户端发送请求时,会将所有与域、路径和安全过滤器相匹配的未过期cookie都发送给这个站点。所有cookie都被组合到一个Cookie首部中
Cookie: session-id=--; session-id-time=
2、Cookies版本1
RFC 2965(以前的RFC 2109)定义了一个cookie的扩展版本。这个版本1标准引入了Set-cookie2首部和Cookie2首部,但它也能与版本0系统进行互操作
RFC 2965 cookie标准比原始的网景公司的标准略微复杂一些,还未得到完全的支持。RFC 2965 cookie的主要改动包括下列内容:为每个cookie关联上解释性文本,对其目的进行解释;允许在浏览器退出时,不考虑过期时间,将cookie强制销毁;用相对秒数,而不是绝对日期来表示cookie的Max-Age;通过URL端口号,而不仅仅是域和路径来控制cookie的能力;通过Cookie首部回送域、端口和路径过滤器(如果有的话);为实现互操作性使用的版本号;在Cookie首部从名字中区分出附加关键字的$前缀
cookie版本1的语法如下所示:
set-cookie = "Set-Cookie2:" cookies
cookies = #cookie
cookie = NAME "=" VALUE *(";" set-cookie-av)
NAME = attr
VALUE = value
set-cookie-av = "Comment" "=" value
"CommentURL" "=" <"> hctp_URL <"> "Discard"
"Domain" "=" value
"Max-Age" "=" value
"Path" "=" value
"Port" [ "=" <"> portlist <"> ]
"Secure"
"Version" "=" *DIGIT
portlist = #portnum
portnum = *DIGIT
cookie = "Cookie:" cookie-version *((";" | ",") cookie-value)
cookie-value = NAME "=" VALUE [";" path][";" domain][";" port]
cookie-version = "$Version" "=" value
NAME = attr
VALUE = value
path = "$Path" "=" value
domain = "$Domain" "=" value
port = "$Port" [ "=" <"> value <"> ]
cookie2 = "Cookie2:" cookie-version
版本1的cookie标准比网景公司标准的可用属性要多。下表对这些属性做了快速汇总。更详细的解释请参见RFC2965


版本1的cookie会带回与传送的每个cookie相关的附加信息,用来描述每个cookie途径的过滤器。每个匹配的cookie都必须包含来自相应Set-Cookie2首部的所有Domain、Port或Path属性
比如,假设客户端以前曾收到下列五个来自Web站点www.joes-hardware.com的Set-Cookie2响应
Set-Cookie2: ID=""; Domain=".joes-hardware.com"
Set-Cookie2: color=blue
Set-Cookie2: support-pref="L2";Domain="customer-care.joes-hardware.com"
Set-Cookie2: Coupon="hammer027"; Version=""; Path="/tools"
Set-Cookie2: Coupon="handvac103"; Version="l”; Path="/tools/cordless"
如果客户端对路径/tools/cordless/specials.html又发起了一次请求,会同时发送这样一个很长的Cookie首部
Cookie: $Version="l";
ID-"";$Domain=".joes-hardware.com";
color="blue";
Coupon="hammer027"; $Path="/tools";
Coupon="handvac103"; $Path="/tools/cordless"
所有匹配cookie都是和它们的set-Cookie2过滤器一同传输的,而且保留关键字都是以美元符号($)开头的
Cookie2请求首部负责在能够理解不同cookie规范版本的客户端和服务器之间进行互操作性的协商。Cookie2首部告知服务器,用户Agent代理理解新形式的cookie,并提供了所支持的cookie标准版本(将其称为Cookie-Version更合适一些):
Cookie2: $Version=""
如果服务器理解新形式的cookie,就能够识别出Cookie2首部,并在响应首部发送Set-Cookie2(而不是Set-Cookie)。如果客户端从同一个响应中既获得了Set-Cookie首部,又获得了Set-Cookie2首部,就会忽略老的Set-Cookie首部
如果客户端既支持版本0又支持版本1的cookie,但从服务器获得的是版本0的Set-Cookie首部,就应该带着版本0的Cookie首部发送cookie。但客户端还应该发送Cookie2: $Version="1"来告知服务器它是可以升级的
【cookie与会话跟踪】
可以用cookie在用户与某个Web站点进行多项事务处理时对用户进行跟踪。电子商务Web站点用会话cookie在用户浏览时记录下用户的购物车信息。以流行的购物网站Amazon.com为例。在浏览器中输入http://www.amazon.com时,就启动了一个事务链,在这些事务中Web服务器会通过一系列的重定向、URL重写以及cookie设置来附加标识信息
下图显示了从一次Amazon.com访问中捕获的事务序列

图a——浏览器首次请求Amazon.com根页面
图b——服务器将客户端重定向到一个电子商务软件的URL上
图c——客户端对重定向的URL发起一个请求
图d——服务器在响应上贴上两个会话cookie,并将用户重定向到另一个URL,这样客户端就会用这些附加的cookie再次发出请求。这个新的URL是个胖URL,也就是说有些状态嵌入到URL中去了。如果客户端禁止了cookie,只要用户一直跟随着Amazon.com产生的胖URL链接,不离开网站,仍然可以实现一些基本的标识功能
图e——客户端请求新的URL,但现在会传送两个附加的cookie
图f——服务器重定向到home.html页面,并附加另外两个cookie
图g——客户端获取home.html页面并将所有四个cookie都发送出去
图h——服务器回送内容
【cookie与缓存】
缓存那些与cookie事务有关的文档时要特别小心。因为不希望给用户分配一个过去某些用户用过的cookie,或者更糟糕的是,向一个用户展示其他人私有文档的内容
cookie和缓存的规则并没有很好地建立起来。下面是处理缓存时的一些指导性规则
如果无法缓存文档,要将其标示出来。文档的所有者最清楚文档是否是不可缓存的。如果文档不可缓存,就显式地注明——具体来说,如果除了Set-Cookie首部之外文档是可缓存的,就使用Cache-Control:no-cache="Sec-Cookie"。另一种更通用的做法是为可缓存文档使用Cache-Control:public,这样有助于节省Web中的带宽
缓存Set-Cookie首部时要小心。如果响应中有Set-Cookie首部,就可以对主体进行缓存,除非被告知不要这么做。但要注意对Set-Cookie首部的缓存。如果向多个用户发送了相同的Set-Cookie首部,可能会破坏用户的定位
有些缓存在将响应缓存起来之前会删除Set-Cookie首部,但这样也会引发一
些问题,因为在没有缓存的时候,通常都会有cookie贴在客户端上,但由缓存提供服务的客户端就不会有cookie了。强制缓存与原始服务器重新验证每条请求,并将返回的所有Set-Cookie首部都合并到客户端的响应中去,就可以改善这种状况。原始服务器可以通过向缓存的副本中添加这个首部来要求进行这种再验证
Cache-Control: must-revalidate, max-age=
即便内容实际上是可以缓存的,比较保守的缓存可能也会拒绝缓存所有包含Set-Cookie首部的响应。有些缓存允许使用缓存Set-Cookie图片,但不缓存文本的模式
小心处理带有Cookie首部的请求。带有Cookie首部的请求到达时,就在提示我们,得到的结果可能是私有的。一定要将私有内容标识为不可缓存的,但有些服务器可能会犯错,没有将此内容标记为不可缓存的
有些响应文档对应于携带Cookie首部的请求,保守的缓存可能会选择不去缓存这些响应文档。同样,有些缓存允许使用缓存cookie图片,而不缓存文本的模式。得到更广泛接受的策略是缓存带有Cookie首部的图片,将过期时间设置为零,强制每次都进行再验证
【安全性和隐私】
cookie是可以禁止的,而且可以通过日志分析或其他方式来实现大部分跟踪记录,所以cookie自身并不是很大的安全隐患。实际上,可以通过提供一个标准的审査方法在远程数据库中保存个人信息,并将匿名cookie作为键值,来降低客户端到服务器的敏感数据传送频率
但是,潜在的滥用情况总是存在的。所以,在处理隐私和用户跟踪信息时,最好还是要小心一些。第三方Web站点使用持久cookie来跟踪用户就是一种最大的滥用。将这种做法与IP地址和Referer首部信息结合在一起,这些营销公司就可以构建起相当精确的用户档案和浏览模式信息
尽管有这么多负面的宣传,人们通常还是认为,如果能够小心地确认在向谁提供私人信息,并仔细査阅站点的隐私政策。那么,cookie会话处理和事务处理所带来的便利性要比大部分风险更重要
前端学HTTP之客户端识别和cookie的更多相关文章
- 和我一起学《HTTP权威指南》——客户端识别与cookie机制
客户端识别与cookie机制 服务器需要区别是哪个客户端. 个性化接触 HTTP是匿名.无状态的请求/响应协议. Web站点希望: 对客户端的用户有更多的了解 追踪用户浏览页面的行为 因此,产生了几种 ...
- HTTP的客户端识别与cookie机制
本文是<HTTP权威指南>的读书笔记 Web服务器可能同时在与数千个客户端同时进行会话,服务器需要记录下它们在与谁交谈,而不是认为所有的请求都来自于匿名客户端.在HTTP中可以有以下几种方 ...
- HTTP客户端识别与Cookie机制
HTTP识别用户的几种技巧 承载用户身份信息的HTTP首部 客户端IP地址跟踪,通过用户的IP地址对其进行识别 用户登录,用认证方式识别用户 胖URL,一种在URL中潜入识别信息的技术 cookie, ...
- 前端学HTTP之报文首部
前面的话 首部和方法配合工作,共同决定了客户端和服务器能做什么事情.在请求和响应报文中都可以用首部来提供信息,有些首部是某种报文专用的,有些首部则更通用一些.本文将详细介绍HTTP报文中的首部 结构 ...
- 计算机网络(HTTP)之客户识别:cookie机制
什么是cookie? 承载用户相关信息的HTTP首部 cookie的工作原理 cookie的缺陷 一.什么是cookie? cookie是由服务器生成,发送给USER-Agent(一般是浏览器),(服 ...
- 前端学做 PPT
前端学做 PPT 公司做技术分享.年终总结都需要用到ppt. 要快速.省事的做出高质量的 ppt,一方面需要熟练使用制作 ppt 的工具,另一方面得知道用工具做成什么样子才是好作品.前者比较简单,后者 ...
- 客户端技术:Cookie 服务端技术:HttpSession
客户端技术:Cookie 服务端技术:HttpSession 07. 五 / android基础 / 没有评论 一.会话技术1.什么是会话:客户打开浏览器访问一个网站,访问完毕之后,关闭浏览器.这 ...
- 前端学PHP之Session
前面的话 Session技术和Cookie相似,都是用来储存使用者的相关资料.但最大的不同之处在于Cookie是将数据存放在客户端的计算机之中,而Session则是将数据存放于服务器系统之下.Sess ...
- 客户端缓存机制 - Cookie详解
Cookie 作者:Stanley 罗昊 [转载请注明出处和署名,谢谢!] Cookie不是内置对象,所以用的时候需要new出来,Cookie是由服务端产生的,再发送给客户端保存,它不是内置对象,却是 ...
随机推荐
- Cassandra简介
在前面的一篇文章<图形数据库Neo4J简介>中,我们介绍了一种非常流行的图形数据库Neo4J的使用方法.而在本文中,我们将对另外一种类型的NoSQL数据库——Cassandra进行简单地介 ...
- linux基础学习笔记
我用的是centOS7.0版本的系统.linux的shell终端窗口类似于wind的command窗口 shell命令提示符格式:用户名@主机名:目录名 提示符 @前面的是已登录的用户名,@之后的为计 ...
- iOS开发之再探多线程编程:Grand Central Dispatch详解
Swift3.0相关代码已在github上更新.之前关于iOS开发多线程的内容发布过一篇博客,其中介绍了NSThread.操作队列以及GCD,介绍的不够深入.今天就以GCD为主题来全面的总结一下GCD ...
- 掌握javascript中的最基础数据结构-----数组
这是一篇<数据结构与算法javascript描述>的读书笔记.主要梳理了关于数组的知识.部分内容及源码来自原作. 书中第一章介绍了如何配置javascript运行环境:javascript ...
- git-2.10.2-64-bit介绍&&git下载&&git安装教程
Git介绍 分布式:Git系统是一个分布式的系统,是用来保存工程源代码历史状态的命令行工具. 保存点:Git的保存点可以追踪源码中的文件, 并能得到某一个时间点上的整个工程项目的状态:可以在该保存点将 ...
- 微信小程序中利用时间选择器和js无计算实现定时器(将字符串或秒数转换成倒计时)
转载注明出处 改成了一个单独的js文件,并修改代码增加了通用性,点击这里查看 今天写小程序,有一个需求就是用户选择时间,然后我这边就要开始倒计时. 因为小程序的限制,所以直接选用时间选择器作为选择定时 ...
- .NET Core 2016 回顾
都在回顾自己的2016,今天我们来看看.NET Core的2016. 每一年的脚步的确是快,转眼间马上就2017.新的一年,带着理想和抱负继续出发. 1 月 ASP.NET 5 改名 ASP.NET ...
- SharePonit 2010 更改另存为列表模板的语言类型
从朋友处得来一个列表模板:AccessApplicationSharePoint.stp 将其通过:网站操作----网站设置----列表模板,上传进去.然后去创建列表,发现找不到此模板. 根据多年老司 ...
- (转) 将ASP.NET Core应用程序部署至生产环境中(CentOS7)
原文链接: http://www.cnblogs.com/ants/p/5732337.html 阅读目录 环境说明 准备你的ASP.NET Core应用程序 安装CentOS7 安装.NET Cor ...
- Oracle 分页
--1:无ORDER BY排序的写法.(效率最高) --(经过测试,此方法成本最低,只嵌套一层,速度最快!即使查询的数据量再大,也几乎不受影响,速度依然!) SELECT * FROM (SELECT ...