【MySQL】2.细节知识
1.存储引擎
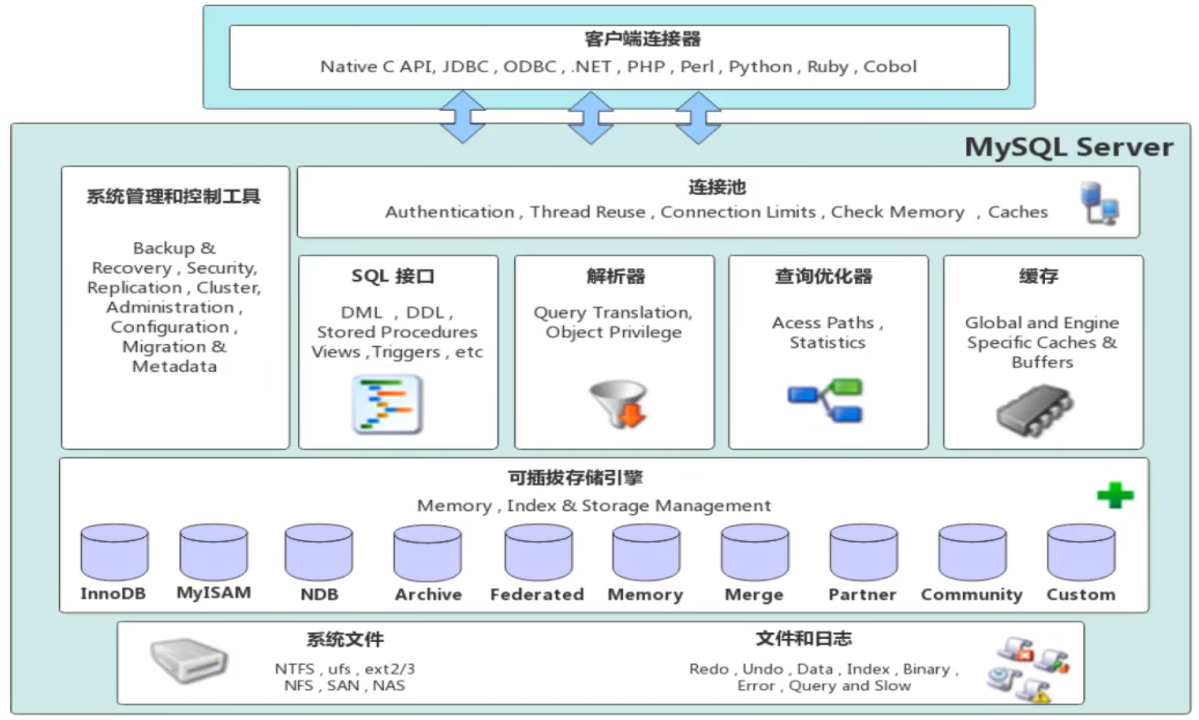
- MySQL体系结构
- 连接层:最上层的客户端连接服务,完成连接处理、授权认证等服务
- 服务层:完成大多数核心服务功能,并完成缓存的查询,SQL的分析和优化,部分内置函数执行
- 引擎层:负责MySQL中数据的存储和提取,不同的存储引擎有不同的功能
- 存储层:将数据存储在文件系统上
- InnoDB 存储引擎
- 支持事务、行级锁和外键
- 文件以ibd作为文件后缀
- Tablespace(表空间)-> Segment(段)-> Extent(区 1M)-> Page(页64K)-> Row(行)
- MyISAM 存储引擎
- 不支持事务,不支持外键,不支持行锁,支持表锁
- .sdi 存储表结构 .MYD 存储数据 .MYI 存储索引
- Memory 存储
- 存储在内存中,默认hash索引
- .sdi 存储表结构信息
2.Index 索引
2.1 基础知识
数据库通过维护索引来提高检索表的效率,通过对索引排序降低对数据直接排序的开销。维护索引会降低增删改的效率,也会额外占用空间。
- B+Tree索引:B+树,最常用
- Hash索引:通过哈希表实现,通常只需要一次检索,但不支持范围查询
- R-tree(空间索引):主要用于地理空间数据
- Full-text(全文索引):建立倒排索引,快速匹配文档
数据结构相关知识查看:数据结构
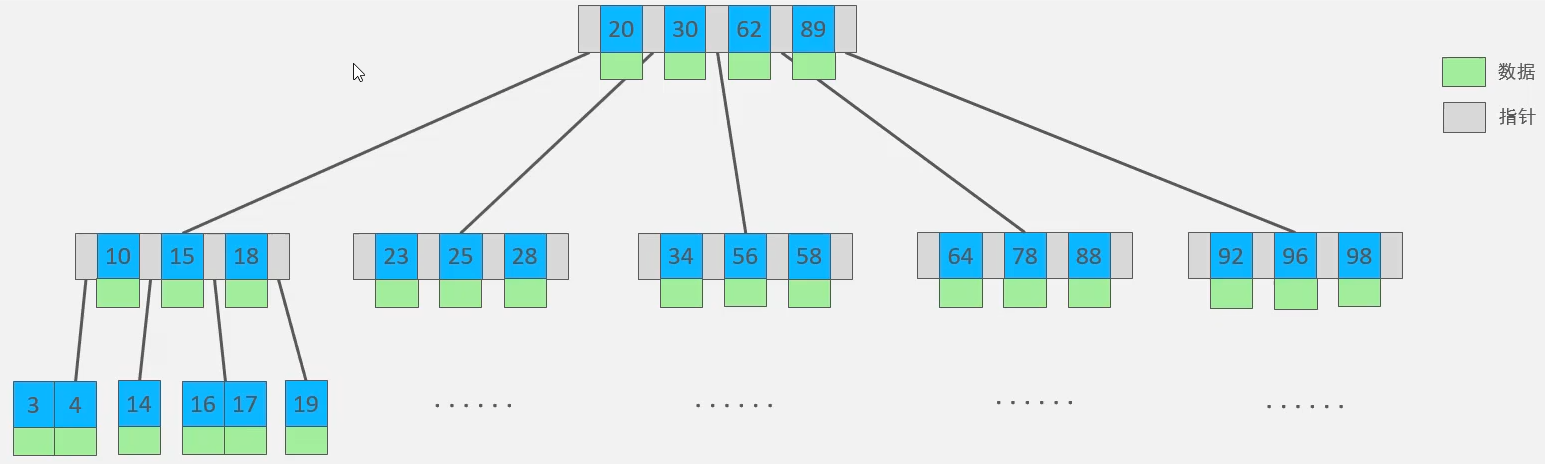
B树:下面是一个5阶的B Tree,他有5个指针,4个Key。注意B树每个节点都存放了数据。
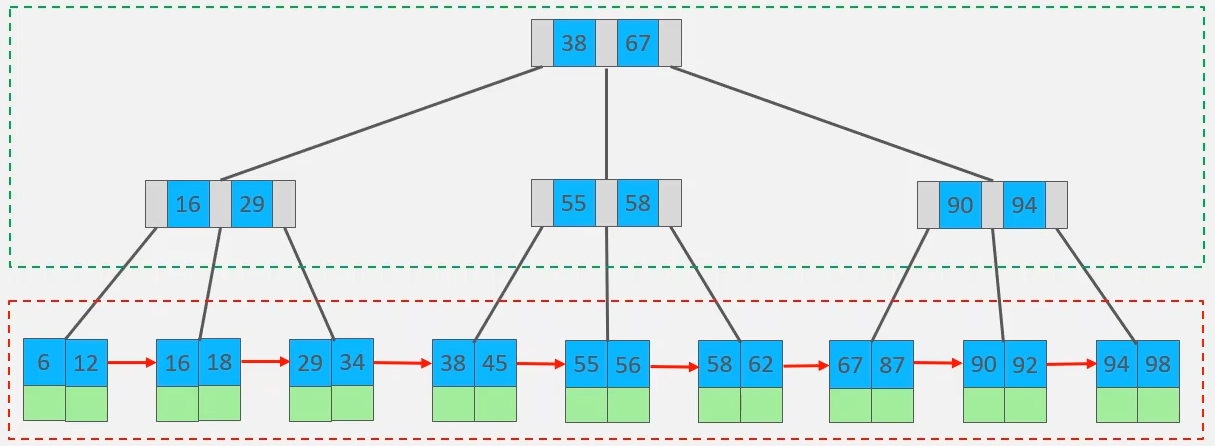
B+树:下面是一个3阶的B+ tree,最多存储3个指针,2个Key。B+树所有元素都会出现在非叶子节点,叶子节点存储的所有元素,也形成了一个单向链表。注意B+树所有的数据都存放在叶子节点上
MySQL对B+树进行了修改,增加了一个指向相邻叶子节点的指针
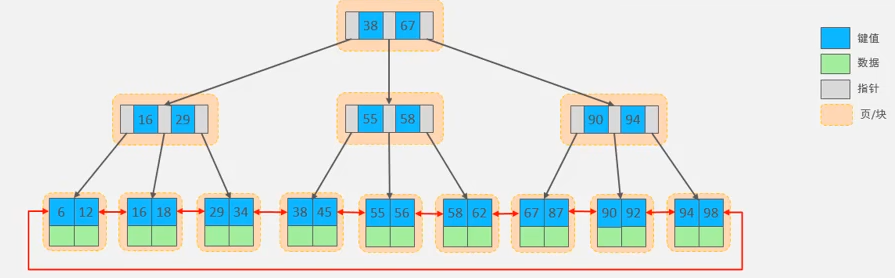
- B-tree和B+tree对比:B树每个节点都需要存放数据,每次寻址到硬盘上16K的空间能查到的指针数量很少,保存同样的数据会导致寻址次数增加,性能下降
- 索引分类
- 主键索引(primary):默认自动创建,只能有一个
- 唯一索引(unique):可以有多个,避免某一个表中某列数据的值重复
- 常规索引:可以有多个
- 全文索引(FULLTEXT):可以有多个,全文索引查找文本中的关键词,而不是比较索引中的值
- 根据索引形式分类:
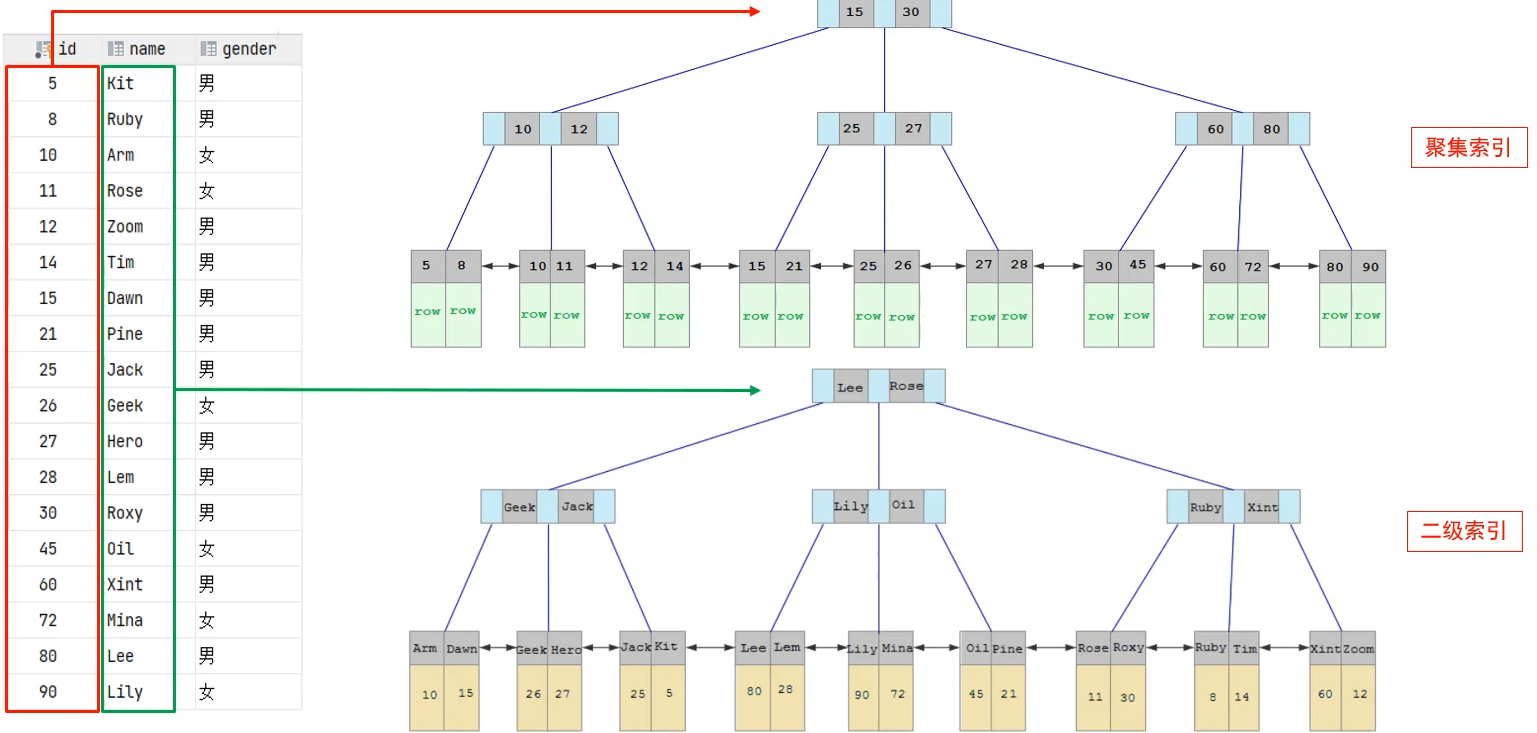
- 聚集索引(Clustered Index):将数据存储和索引放到一块,叶子节点保存行数据,可以有,必须只有一个
- 如果表存在主键,主键索引就是聚集索引
- 如果表不存在主键,则使用第一个唯一(unique)索引作为聚集索引
- 如果表没有主键,没有合适的唯一索引,则自动创建rowid作为隐藏的聚集索引
- 二级索引(Secondary Index):将数据与索引分开存储,叶子节点保存关联的主键值,可以存在多个
- 聚集索引(Clustered Index):将数据存储和索引放到一块,叶子节点保存行数据,可以有,必须只有一个
下面是实际例子,只有聚集索引存储了数据,二级索引没有存储实际数据,避免数据冗余。如果查询索引 'Arm',它首先查询二级索引中 'Arm' 对应的聚集索引 '10',然后再通过 '10' 查询具体的数据,这个过程称为回表查询。
2.2 SQL语法
- 创建索引
- 联合索引:创建一个索引关联(partid, age, name),最左前缀法则:索引最左侧的字段必须存在
- select * from user where partid=1 and age=20 and name='Xuan'; # 通过联合索引查询
- select * from user where partid=1 and age=20; # 通过联合索引查询
- select * from user where age=20 and name='xuan'; # 全表扫描查询
- select * from user where partid=1 and name='xuan'; # 先通过联合索引查询partid,再通过全表扫描查询name
- select * from user where partid=1 and age>30 and name='xuan'; # 如果联合索引出现范围查询(>,<) 范围查询右侧的索引失效
- select * from user where partid=1 and age>=30 and name='xuan'; # >= 不会让右侧索引失效
- 如果对索引列进行函数运算会使索引失效
- select * from user where substring(phone, 10, 2) = '15'; # 查看手机尾号为15的,全表扫描而非通过索引查找phone
- 模糊匹配中,后面字段模糊才能走索引
- select * from user where id like '123%'; # 前缀为123的所有id的人
- 数据分布影响索引的使用:如果使用索引的扫描比使用全表扫描还慢,则会不使用索引
- 前缀索引:如果用完整字符串做索引,可能消耗大量空间,截取一部分来做索引
- 单列索引和联合索引
- 联合索引:创建一个索引关联(partid, age, name),最左前缀法则:索引最左侧的字段必须存在
# 创建索引
CREATE [UNIQUE|FULLTEXT] INDEX index_name ON table_name (index_col_name, ...);
# 查看索引
SHOW INDEX FROM table_name;
# 删除索引
DROP INDEX index_name ON table_name; # 创建普通的索引
create index idx_user_name on tb_user(name);
# 创建唯一索引
create unique index idx_user_phone on tb_user(phone);
# 创建联合索引
create index idx_user_pro_age_sta on tb_user(profession, age, status);
# 前缀索引
select count(*) from user; # user表总数
select count(email) from user; # email不为空的字段
select count(distinct email) from user; # email不为空且不重复的字段
select count(distinct email) / count(*) from user; # 计算它的可选择性
select count(distinct substring(email, 1, 10)) / count(*) from user; # 如果截取前10个字符它的选择性和之前的选择性是否一样,让前缀最少且选择性相同
create index idx_email_5 on user(email(5)); # 创建email前缀为5的索引
- 查看SQL执行频率:查询每个指令的使用次数,分析这个表主要被查询、修改还是删除等
SHOW GLOBAL STATUS LIKE 'Com_______';
- 慢查询日志
# 查看是否打开了慢查询日志
show variables like 'slow_query_time'; vim /etc/my.cnf
# 设置慢查询开关
slow_query_log = 1
# 设置慢查询时间超过几秒记录
long_query_time = 2 # 查看慢查询的记录
vim /var/lib/mysql/localhost-slow.log
- 显示每条指令具体耗时在哪方面
# 查看是否支持查看耗时
SELECT @@have_profiling;
# 设置开关
set profiling = 1;
# 查看每条SQL耗时基本情况,会显示指令和该条指令记录的ID
show profiles;
# 查看指定query_id的SQL语句各个阶段耗时
show profile for query query_id;
# 查看指定query_id的SQL语句CPU使用情况
show profile cpu for query query_id;
- explain执行计划,有子查询的这种指令肯定会执行多条指令,显示一张表来查看信息
- id:select查询的序列表,表示操作表的顺序,id相同则从上到下查询,id值越大越先执行
- select_type:select查询的类型,simple(简单表)、primary(主查询)、union(union中第二个或后面的查询语句)、subquery(select/where后包含了子查询)等
- type:连接类型,性能从好到差依次是 NULL、System、const(主键或唯一索引访问)、eq_ref、ref(非唯一索引访问)、range、index、all
- possible_key:可能用到的一个或多个索引
- key:实际用到的索引
- key_len:使用到索引的字节数
- rows:mysql认为要执行查询的行数,innnodb引擎的表中,是估计值
- filtered:返回结果的行数占需读取行数的百分比,越大越好
# 在语句前加 EXPLAIN 或 DESC 查看语句执行时如何连接和连接的顺序
# 举例
desc select * from tb_user where id = 1;
explain select * from tb_user where id =1;
2.3 SQL优化
- 主键优化:InnoDB引擎中,表数据都是根据主键顺序存放的,因为是按主键顺序存放的,就会涉及到页的处理(所以插入数据时应该尽可能按顺序插入,或使用自增主键,不然会频繁的进行页分裂)
- 页分裂:主键在乱序插入的时候,如果某一页的空间满了会出现页分裂

- 页合并:删除主键后,首先会标记它是被删除了,而非删除这个数据,接下来该数据可以被覆盖。如果删除的数量多到一个阈值会进行合并



- order by 优化
- explain 查看显示 using filesort:首先全表扫描,把满足条件的行加载到缓冲区,之后进行排序
- explain 查看显示 using index:表示直接根据索引顺序返回有序数据
- 提前建立索引可以提高order by的效率
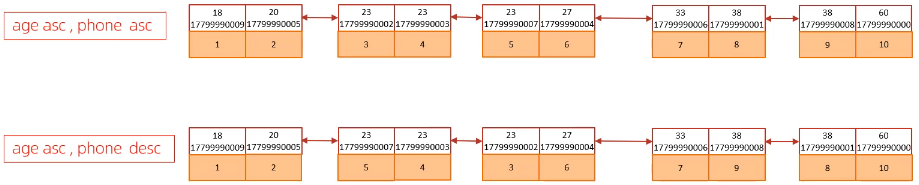
- 以一个联合索引为例子
- 第一个索引可以直接返回(age, phone)全升序或全降序的排列(从左向右扫描或从右向左扫描)
- 第二个索引可以直接返回(age, phone)age升序phone降序或者age降序phone升序的排列
- group by 优化
- explain 提示 using temporary:建立临时表来完成分组
- explain 提示 using index:通过索引完成分组
- 提前建立联合索引,同样也是按照最左前缀法则,可以快速完成分组
- limit 优化
- select * from user limit 10,10; # 每页10条数据,查看10条
- select * from user order by id limit 1000000, 10; # 查询第1000000的第10条数据,这就很慢很慢了
- 分页查询:首先创建覆盖索引提高性能,然后通过覆盖索引加子查询子查询形式优化
- select s.* from user u, (select id from user order by id limit 2000000,10) u2 where u.id = u2.id;
- count 优化
- count 由于需要大量的访问磁盘会很消耗时间,根据字段是否为空来进行计数。下面按效率排序介绍
- count(*) InnoDB引擎不会把全部字段取出,而是专门做了优化,直接累加
- count(1) 遍历整张表,对于服务层返回的每一行放一个数字1进去,直接累加
- count(主键) 直接把每一行主键id取出并累加
- count(字段)
- 有not null约束,直接累加;无not null约束,判断是否为null然后再累加
- update 优化
- 如果id存在索引,部门名称不存在索引
- select course set name = 'newName' where id = '1'; # 由于id建立的索引,所以只会有行锁
- select course set name = 'newName' where name = 'oldName'; # 由于name没有索引,行锁会升级为索引,影响并发性能
- 如果id存在索引,部门名称不存在索引
3.视图
视图(View)是一种虚拟存在的表。视图中的数据并不在数据库中真实存在,行和列数据来自定义视图的查询中使用的表
# 语法
create [OR REPLACE] VIEW 视图名称[(列名列表)] AS SELECT 语句 [WITH [CASCADED | LOCAL] CHECK OPTION];
# 创建视图
create or replace view stu as select id,name from student where id <=10;
create or replace view stu2 as select id, name from student where id<=20 with cascded check option;
# 修改创建的视图 两种方法
create or replace view stu as select id, name, no from student where id <= 10;
alter view stu as select id, name from student where id<=10;
# 删除视图
drop view if exists stu;
# 查询
show create view stu;
select * from stu where id = 3;
# 插入(视图本身不存储数据,插入的数据实际是视图所展示的表)
insert into stu values(6, 'Tom', 12222);
insert into stu2 values(30, 'Tom', 12222); # 因为创建表的时候有检查选项, 这里id30大于视图能显示的id,会插入失败
【MySQL】2.细节知识的更多相关文章
- c/c++细节知识整理
这篇文章总结了部分c/c++琐碎的细节知识. 目录如下: (一)bool类型 知识点出处较多,无法一一列举,向原作者致敬. (一)bool类型 在c99标准以前,c语言并没有定义bool类型.如果需要 ...
- mysql 索引相关知识
由where 1 =1 引发的思考 最近工作上被说了 说代码中不能用 where 1=1,当时觉得是应该可以用的,但是找不到什么理据, 而且mysql 语句优化这方面确实很薄弱 感觉自己mysql ...
- [置顶] Mysql存储过程入门知识
Mysql存储过程入门知识 #1,查看数据库所有的存储过程名 #--这个语句被用来移除一个存储程序.不能在一个存储过程中删除另一个存储过程,只能调用另一个存储过程 #SELECT NAME FROM ...
- mysql数据库相关知识
什么是数据库? 数据库(Database)是按照数据结构来组织.存储和管理数据的建立在计算机存储设备上的仓库.(来自:百度) 什么是sql? 结构化查询语言(Struct ...
- MySQL使用细节
************************************************************************ MySQL使用细节,包括部分常用函数以及注意如何提高数 ...
- LaTeX的一些宏包及细节知识
文章来源:LaTeX的一些宏包及细节知识http://blog.chinaunix.net/uid-20289887-id-1710422.html ps:我的机器上软件并不能直接运行通,下面“代码” ...
- MySQL数据库基础知识及优化
MySQL数据库基础知识及优化必会的知识点,你掌握了多少? 推荐阅读: 这些必会的计算机网络知识点你都掌握了吗 关于数据库事务和锁的必会知识点,你掌握了多少? 关于数据库索引,必须掌握的知识点 目录 ...
- Mysql之基础知识笔记
Mysql数据库基础知识个人笔记 连接本地数据库: mysql -h localhost -u root -p 回车输入数据库密码 数据库的基础操作: 查看当前所有的数据库:show database ...
- mysql基础类型知识总结
Mysql知识回顾 http://www.educity.cn/wenda/596225.html http://blog.csdn.net/dyllove98/article/details/928 ...
- MySQL的基本知识 -- 函数
MySQL基本知识 -- 进阶(常用的函数) Tags: MySQL MySQL进阶 1.计算字段 1.概念 : 如果客户端想要的数据格式不是数据库直接在表中存储的数据格式的话,有两种处理方式.第一种 ...
随机推荐
- UML类图-UML Class Diagram
.wj_nav { display: inline-block; width: 100%; margin-top: 0; margin-bottom: 0.375rem } .wj_nav_1 { p ...
- HarmonyOS NEXT从图库选择资源上传到服务器或者把网络资源下载到图库
用户需要分享文件.保存图片.视频等用户文件时,开发者可以通过系统预置的文件选择器(FilePicker),实现该能力.通过Picker访问相关文件,将拉起对应的应用,引导用户完成界面操作,接口本身无需 ...
- Java 提取url的域名
有时候,我们需要校验URL的域名是否在白名单中,故需要提取其中的域名.可以使用java标准类库java.net.URL进行提取,方法如下: import org.apache.commons.la ...
- 面试题:JAVA中final关键字的作用
final关键字的功能概述 在Java中,关键字 final 的意思是终态,可以用于声明变量.方法和类,分别表示基本类型变量值不可变,引用类型变量引用地址不可变但值可变,方法不可被覆盖,类不可被继 ...
- 2024牛客多校2I Red Playing Cards
本文同步于我的博客. Problem There are \(2\cdot n\) cards arranged in a row, with each card numbered from \(1\ ...
- ServiceMesh实验室——00之实验室搭建
实验室搭建 Docker&&K8S 环境,这一篇(https://github.com/AliyunContainerService/k8s-for-docker-desktop)就够 ...
- vue.js+vuetify学习开发排坑:一个古怪的代码 v-slot:activator="{ on, attrs }"
由于需要全栈开发一个售票系统项目,时隔一年后重新捡回了我的前端技术~ 开发习惯是边看文档边做,然后再vuetify这个MD设计的UI元件库翻来翻去,再涉及到元件交互的时候有几段代码不是很能理解 < ...
- javascript定义函数后立即执行(IIFE)
Talk is cheap, show me the code. // Immediately Invoked Function Expression - IIFE // 定义后立即执行的JavaSc ...
- ArcGIS Pro SDK 001 基于SDK创建第一个插件
ArcGIS Pro SDK只能开发ArcGIS Pro软件上的插件,不能单独开发独立的应用程序.ArcMap是32位的,在处理大数据时,经常会崩溃,但同样的数据和逻辑,因为ArcGIS Pro是64 ...
- 一个基于 .NET 8 开源免费、高性能、低占用的博客系统
前言 今天大姚给大家分享一个基于 .NET 8 开源免费(MIT license).高性能.高安全性.低占用的博客系统:Masuit.MyBlogs. 项目介绍 Masuit.MyBlogs 是一个基 ...