实用干货分享(5)- Hive存储格式及压缩算法测试比对分析

 编辑
编辑
Hive文件存储格式及优缺点
textfile
默认的文件格式,行存储。建表时不指定存储格式即为textfile,导入数据时把数据文件拷贝至hdfs不进行处理。
优点:最简单的数据格式,便于和其他工具(pig, grep, sed, awk)共享数据、便于查看和编辑;加载较快。
缺点:耗费存储空间,I/O性能较低;Hive不进行数据切分合并,不能进行并行操作,查询效率低。
适用于小型查询,查看具体数据内容的测试操作。
sequencefile
行存储,含有键值对的二进制文件。
优点:可压缩、可分割,优化磁盘利用率和I/O;可并行操作数据,查询效率高。
缺点:存储空间消耗最大;对于Hadoop生态系统之外的工具不适用,需要通过text文件转化加载。
rcfile
行列式存储。先将数据按行分块,同一个record在一个块上,避免读一条记录需要读多个block;然后块数据列式存储。
优点:可压缩,高效的列存取;查询效率较高。
缺点:加载时性能消耗较大,需要通过text文件转化加载;读取全量数据性能低。
orcfile
 编辑
编辑
优化后的rcfile,行列式存储。优缺点与rcfile类似,查询效率最高。适用于Hive中大型的存储、查询。
parquet
 编辑
编辑
列式存储,以二进制方式存储。
优点:可压缩,高效的列存取;优化I/O。
缺点:不支持upadate操作(数据写入后不可更改),不支持ACID。
Hive压缩算法对比
Hive压缩算法包含6种,其中包含default、gzip、bzip2、lzo、lz4、snappy等压缩格式,具体采用压缩算法及比对详细如下:
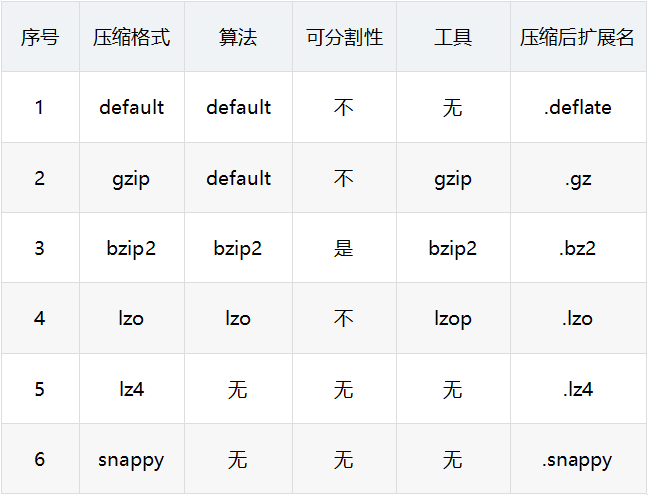
编辑
检查Hadoop本地库支持压缩格式
检查命令:hadoop checknative
hadoop checknative 命令检查本地库是否支持压缩,若不支持,需要进行源码编译将native library编译进Hadoop。
native library checking:
hadoop: true /opt/cloudera/parcels/cdh-6.1.0-1.cdh6.1.0.p0.770702/lib/hadoop/lib/native/libhadoop.so.1.0.0
zlib: true /lib64/libz.so.1
zstd: true /opt/cloudera/parcels/cdh-6.1.0-1.cdh6.1.0.p0.770702/lib/hadoop/lib/native/libzstd.so.1
snappy: true /opt/cloudera/parcels/cdh-6.1.0-1.cdh6.1.0.p0.770702/lib/hadoop/lib/native/libsnappy.so.1
lz4: true revision:10301
bzip2: true /lib64/libbz2.so.1
openssl: true /lib64/libcrypto.so
isa-l: true /opt/cloudera/parcels/cdh-6.1.0-1.cdh6.1.0.p0.770702/lib/hadoop/lib/native/libisal.so.2
Hive压缩算法设置
default压缩格式
 编辑
编辑
set hive.exec.compress.output=true;
set mapred.output.compress=true;
set mapred.output.compression.codec=org.apache.hadoop.io.compress.defaultcodec;
gzip压缩格式
 编辑
编辑
set hive.exec.compress.output=true;
set mapred.output.compress=true;
set mapred.output.compression.codec=org.apache.hadoop.io.compress.gzipcodec;
bzip2压缩格式
 编辑
编辑
set hive.exec.compress.output=true;
set mapred.output.compress=true;
set mapred.output.compression.codec=org.apache.hadoop.io.compress.bzip2codec;
lzo压缩格式
 编辑
编辑
set hive.exec.compress.output=true;
set mapred.output.compress=true;
set mapred.output.compression.codec=com.hadoop.compression.lzo.lzopcodec;
lz4压缩格式
 编辑
编辑
set hive.exec.compress.output=true;
set mapred.output.compress=true;
set mapred.output.compression.codec= org.apache.hadoop.io.compress.lz4pcodec;
snappy压缩格式
 编辑
编辑
set hive.exec.compress.output=true;
set mapred.compress.map.output=true;
set mapred.output.compress=true;
set mapred.output.compression=org.apache.hadoop.io.compress.snappycodec;
set mapred.output.compression.codec=org.apache.hadoop.io.compress.snappycodec;
set io.compression.codecs=org.apache.hadoop.io.compress.snappycodec;
压缩算法测试及结果比对
测试案例
 编辑
编辑
测试一个Hive在不同的压缩格式下进行对压缩比、查询效率、插入效率进行结果比对。
测试环境
 编辑
编辑
大数据平台产品:CDH6.1
节点个数:2+6
内存:256G
CPU:64核
测试数据
 编辑
编辑
表名称:ods.o_cor_test
源文件大小:3.8G
查询速度:19.41S
建表语句:
CREATE TABLE ODS.O_COR_TEST
( BOOK_ID STRING,
EVENT_ID STRING,
TRX_ID_IN STRING,
TRX_ID_OUT STRING,
LINE_ID STRING,
HEADER_ID STRING,
BATCH_ID STRING,
BOOK_TYPE STRING,
ASSET_TYPE STRING,
CATEGORY_ID STRING,
INTERFACE_CONTROL_ID_IN STRING,
INTERFACE_CONTROL_ID_OUT STRING,
EFFECTIVE_DATE DATE,
INEFFECTIVE_DATE DATE,
DATA_DATE DATE,
ACCOUNTING_DATE DATE,
EVENT_TYPE STRING,
ACTIVE_CODE STRING,
AMORTIZED_COST STRING,
FAIR_COST STRING,
CONTACT_IN STRING,
CONTACT_OUT STRING,
COST STRING,
INT STRING,
INT_ADJUST STRING,
EVALUATION_ADJUST STRING,
FAIR_COST_ADJUST STRING,
CV_RESERVE STRING,
RV_RESERVE STRING,
HV_RESERVE STRING,
RA_COST STRING,
LEASE_COST STRING,
LEASE_CV_RESERVE STRING,
LEASE_RV_RESERVE STRING,
LEASE_HV_RESERVE STRING,
INVESTMENT_INCOME STRING,
INVESTMENT_LOSS STRING,
FAIR_COST_GAIN_LOSS STRING,
V_LOSS STRING,
OTHER_INCOME STRING,
ORIGINAL STRING,
TRANS_INT_IN STRING,
TRANS_INT_OUT STRING,
INT_ACCRUED STRING,
EXPENSE STRING,
RECOV_ORIGINAL STRING,
RECOV_TRANS_INT_IN STRING,
RECOV_TRANS_INT_OUT STRING,
RECOV_INT_ACCRUED STRING,
RECOV_EXPENSE STRING,
LOSS_ORIGINAL STRING,
LOSS_TRANS_INT_IN STRING,
LOSS_TRANS_INT_OUT STRING,
LOSS_INT_ACCRUED STRING,
LOSS_EXPENSE STRING,
LEASE_ORIGINAL STRING,
GUARANTEE1 STRING,
GUARANTEE2 STRING,
GUARANTEE3 STRING,
BALANCE_OUT STRING,
LY_INVESTMENT_INCOME STRING,
LY_INVESTMENT_LOSS STRING,
LY_FAIR_COST_GAIN_LOSS STRING,
LY_V_LOSS STRING,
LAST_UPDATE_DATE DATE,
LAST_UPDATED_BY STRING,
CREATION_DATE DATE,
CREATED_BY STRING,
LAST_UPDATE_LOGIN STRING,
ATTRIBUTE_CATEGORY STRING,
ATTRIBUTE1 STRING,
ATTRIBUTE2 STRING,
ATTRIBUTE3 STRING,
ATTRIBUTE4 STRING,
ATTRIBUTE5 STRING,
ATTRIBUTE6 STRING,
ATTRIBUTE7 STRING,
ATTRIBUTE8 STRING,
ATTRIBUTE9 STRING,
ATTRIBUTE10 STRING,
INT_AMORTIZED STRING,
START_DATE DATE,
END_DATE DATE,
DEL_FLAG STRING
)
测试方法
本测试采用每次开启Hive压缩模式并设置Hive的压缩算法,对于Hive每种文件存储格式新建Hive表,并向不同分区插入数据,测试并记录各种压缩算法的压缩效率、查询速率、插入速度。
注:每次设置终端退出后设置无效。
查询速率测试sql语句:
select count(*) from ods.o_cor_test where etl_date=
压缩算法对比
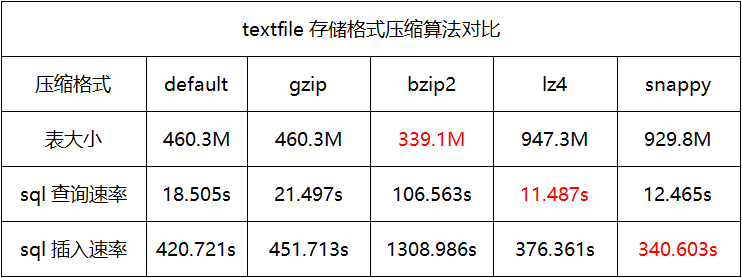
编辑
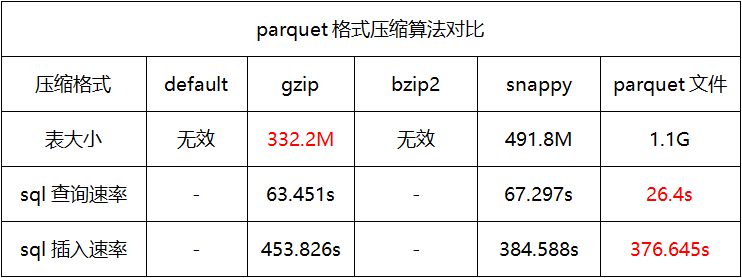
编辑

编辑
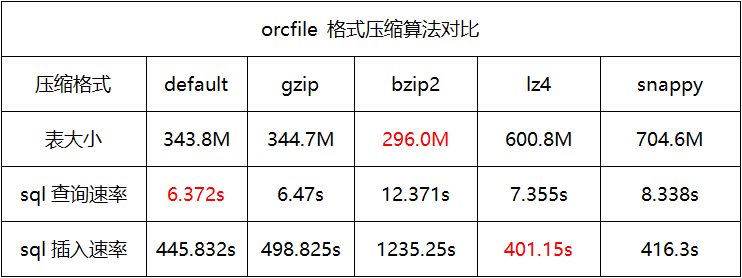
编辑
测试结果
当应用场景多为查询时,建议使用orcfile存储格式且压缩格式为default。
当应用场景多为存储时,建议使用orcfile存储格式且压缩格式为bzip2。
当应用场景多为插入时,建议使用sequencefile存储格式且压缩格式为snappy。
一般常用存储格式为orcfile且压缩格式为default。
实用干货分享(5)- Hive存储格式及压缩算法测试比对分析的更多相关文章
- 逆向实用干货分享,Hook技术第一讲,之Hook Windows API
逆向实用干货分享,Hook技术第一讲,之Hook Windows API 作者:IBinary出处:http://www.cnblogs.com/iBinary/版权所有,欢迎保留原文链接进行转载:) ...
- 逆向实用干货分享,Hook技术第二讲,之虚表HOOK
逆向实用干货分享,Hook技术第二讲,之虚表HOOK 正好昨天讲到认识C++中虚表指针,以及虚表位置在反汇编中的表达方式,这里就说一下我们的新技术,虚表HOOK 昨天的博客链接: http://www ...
- 【腾讯优测干货分享】Android内存泄漏的简单检查与分析方法
本文来自于Dev Club 开发者社区,非经作者同意,请勿转载,原文地址:http://dev.qq.com/topic/57d14047603a5bf1242ad01b 导语 内存泄漏问题大约是An ...
- 【腾讯优测干货分享】安卓专项测试之GPU测试探索
本文来自于Dev Club 开发者社区,非经作者同意,请勿转载,原文地址:http://dev.qq.com/topic/57c7ffdc0569a1191bce8a63 作者:章未哲——腾讯SNG质 ...
- 【干货分享】Google 的设计准则,素材和资源
在谷歌,他们说, “专注于用户,所有其它的就会水到渠成 ”.他们遵循设计原则,寻求建立让用户惊喜的用户体验.谷歌一直挑战自己,为他们的用户创造一种视觉语言,综合优秀设计的经典原则和创新.谷歌设计规范是 ...
- APP运营干货分享
从移动互联网市场总监岗位出发,从几个方面来阐述移动互联网部门如何制定一份运营推广策划案,至于关于移动互联网,移动电商是大趋势这些虚的.空泛的文字,不展开说了. 一.竞品分析 1.选择竞品,做好定位(选 ...
- Hive存储格式之RCFile详解,RCFile的过去现在和未来
我在整理Hive的存储格式和压缩格式,本来打算一篇发出来,结果其中一小节就有很多内容,于是打算写成Hive存储格式和压缩格式系列. 本节主要讲一下Hive存储格式最早的典型的列式存储格式RCFile. ...
- Hive存储格式之ORC File详解,什么是ORC File
目录 概述 文件存储结构 Stripe Index Data Row Data Stripe Footer 两个补充名词 Row Group Stream File Footer 条纹信息 列统计 元 ...
- 干货分享:SQLSERVER使用裸设备
干货分享:SQLSERVER使用裸设备 这篇文章也适合ORACLE DBA和MYSQL DBA 阅读 裸设备适用于Linux和Windows 在ORACLE和MYSQL里也是支持裸设备的!! 介绍 大 ...
- iOS - GitHub干货分享(APP引导页的高度集成 - DHGuidePageHUD - ②)
距上一篇博客"APP引导页的高度集成 - DHGuidePageHUD - ①"的发布有一段时间了, 后来又在SDK中补充了一些新的内容进去但是一直没来得及跟大家分享, 今天来跟大 ...
随机推荐
- 运维管理平台OEM定制集成开发,激发IT价值
对硬件设备商而言,借助优秀的网管.运维管理平台,可以形成完整的产品解决方案,直接提升产品的形象和适用范围.同时还可以通过网管.运维管理平台,切入到外围的产品及集成领域,并在用户后续的升级改造活动中占据 ...
- laravel框架接口
下面是增删改查的接口,在使用过程中按自己需求对代码进行更改 控制器代码 <?php namespace App\Http\Controllers; use App\Models\Fang; us ...
- FirewallD is not running 原因与解决方法
解决方法关于linux系统防火墙: centos5.centos6.redhat6系统自带的是iptables防火墙.centos7.redhat7自带firewall防火墙.ubuntu系统使用的是 ...
- ES5 和 ES6 的区别,说几个 ES6 的新增方法
ECMAscript5.,即ES5 ,表示 ECMAscript的第五次修订-2009 : ECMAscript6.,即ES6 ,表示 ECMAscript的第六次修订-2015 : ES6 是对于 ...
- Vue 组件如何进行传值的?
1 父子传值 在子组件标签设置属性,在子组件内使用 props 接收属性值 : 2. 子父传值 在子组件中使用 emit 自定义事件,在子组件标签注册自定义事件 ,接收参数 : 3. vuex 状态管 ...
- LeetCode题目练习记录 _栈、队列01 _20211012
LeetCode题目练习记录 _栈.队列01 _20211012 84. 柱状图中最大的矩形 难度困难1581 给定 n 个非负整数,用来表示柱状图中各个柱子的高度.每个柱子彼此相邻,且宽度为 1 . ...
- 轻量级网络-MobileNetv1 论文解读
1.相关工作 标准卷积 分组卷积 从 Inception module 到 depthwise separable convolutions 2.MobileNets 结构 2.1,深度可分离卷积 D ...
- 版本库控制系统的切磋之路[Git & SVN]
集中式和分布式 集中式版本库控制系统 :SVN ; 分布式版本库控制系统 :Git . 集中式 版本库是存在中央服务器的.干活使用的是自己的电脑,每次干活前都是从服务器上拉下最新的代码版本,然后才 ...
- [离线计算-Spark|Hive] 数据近实时同步数仓方案设计
背景 最近阅读了大量关于hudi相关文章, 下面结合对Hudi的调研, 设计一套技术方案用于支持 MySQL数据CDC同步至数仓中,避免繁琐的ETL流程,借助Hudi的upsert, delete 能 ...
- Spring AI + ollama 本地搭建聊天 AI
Spring AI + ollama 本地搭建聊天 AI 不知道怎么搭建 ollama 的可以查看上一篇Spring AI 初学. 项目可以查看gitee 前期准备 添加依赖 创建 SpringBoo ...