多模态模型 Grounding DINO 初识
简介
Grounding DINO 是一种先进的零样本目标检测模型,由 IDEA Research 开发。它通过将基于 Transformer 的检测器 DINO 与Grounded Pre-Training相结合,实现了通过人类输入(如类别名称或指代表达)对任意物体进行检测。
例如在不需要任何训练的情况下,告诉Grounding DINO找出图像中人所在的位置,Grounding DINO就能标注出人的坐标。如下:

演示流程:

基本原理
在Grounding DINO中,作者想要完成这样一项任务:根据人类文字输入去检测任意类别的目标,称作开放世界目标检测问题(open-set object detection)。
完成open-set object detection的关键是将language信息引入到目标的通用特征表示中。例如,GLIP利用对比学习的方式在目标检测和文字短语之间建立起了联系,它在close-set和open-set数据集上都有很好的表现。尽管如此,GLIP是基于传统的one-stage detector结构,因此还有一定的局限性。
受很多前期工作的启发(GLIP、DINO等),作者提出了Grounding DINO,它相对于GLIP有以下几点优势:
- Grounding DINO 的transformer结构更接近于NLP模型,因此它更容易同时处理图片和文字;
- Transformer-based detector在处理大型数据集时被证明有优势;
- 作为DETR的变种,DINO能够完成end-to-end的训练,而且不需要NMS等额外的后处理。
网络结构:
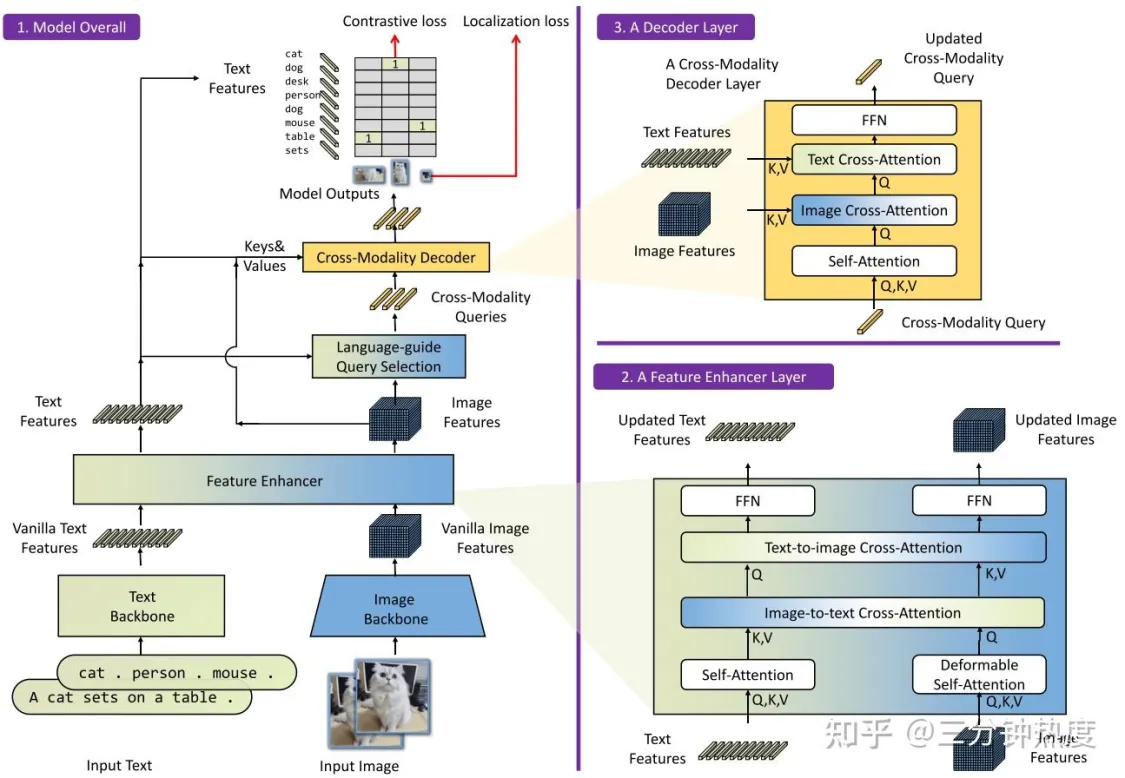
Grounding DINO的整体结构如上图所示。Grounding DINO是一个双encoder单decoder结构,它包含了
- 一个image backbone用于提取image feature
- 一个text backbone用于提取text feature
- 一个feature enhancer用于融合image和text feature
- 一个language-guide query selection模块用于query初始化
- 一个cross-modality decoder用于bbox预测
特点与优势
- 零样本检测能力:Grounding DINO 能够在没有目标数据集标注的情况下,通过文本提示检测未见过的类别。例如,在 COCO 数据集的零样本检测基准测试中,它达到了 52.5 AP。
- 强大的跨模态融合能力:通过深度的视觉与语言模态融合,模型在开放集目标检测和指代表达理解任务中表现出色。
- 端到端优化:基于 Transformer 的架构使得 Grounding DINO 可以端到端地进行优化,无需手工设计模块。
应用场景
- Grounding DINO 可以广泛应用于需要灵活目标检测的场景
- 自动驾驶:通过自然语言描述检测特定的交通标志或障碍物。
- 机器人视觉:根据指令识别和操作物体。
- 图像标注与内容理解:自动识别图像中的对象并生成描述。
安装
参考:https://blog.csdn.net/weixin_44151034/article/details/139362032
1.安装虚拟环境
conda create -n dino python=3.10 -y
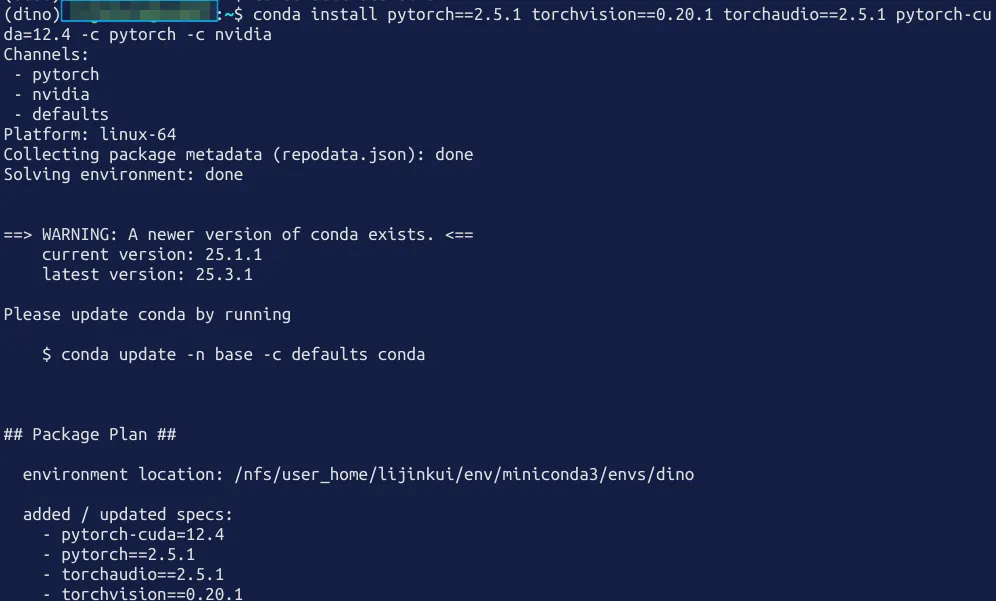
2.安装pytorch
conda install pytorch==2.5.1 torchvision==0.20.1 torchaudio==2.5.1 pytorch-cuda=12.4 -c pytorch -c nvidia
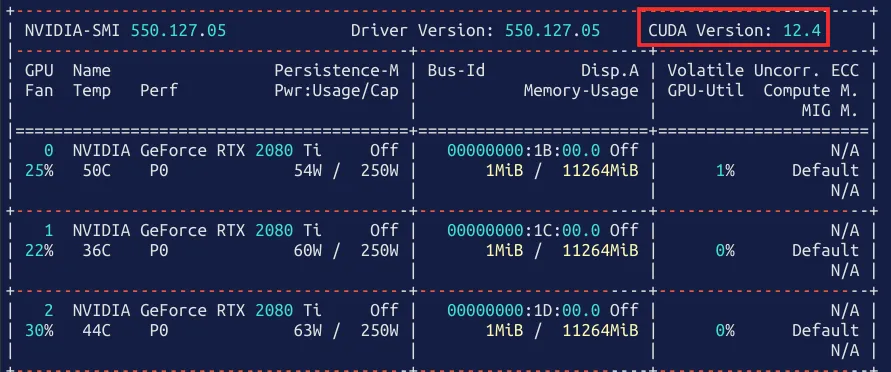
如果有显卡在安装pytorch之前需要了解显卡驱动支持的最高cuda版本,安装pytorch的同时会安装cuda和cudnn等模块,保证cuda版本在显卡支持的范围之内。
nvidia-smi
4.下载项目并安装
git clone https://github.com/IDEA-Research/GroundingDINO.git
cd GroundingDINO
pip install -e . -i https://pypi.tuna.tsinghua.edu.cn/simple
5.下载权重
预训练模型:groundingdino_swint_ogc.pth 这里可能需要使用魔法
mkdir weights
cd weights
wget -q https://github.com/IDEA-Research/GroundingDINO/releases/download/v0.1.0-alpha/groundingdino_swint_ogc.pth
到这里为止就安装好了Grounding DINO,下面就来使用它。
运行
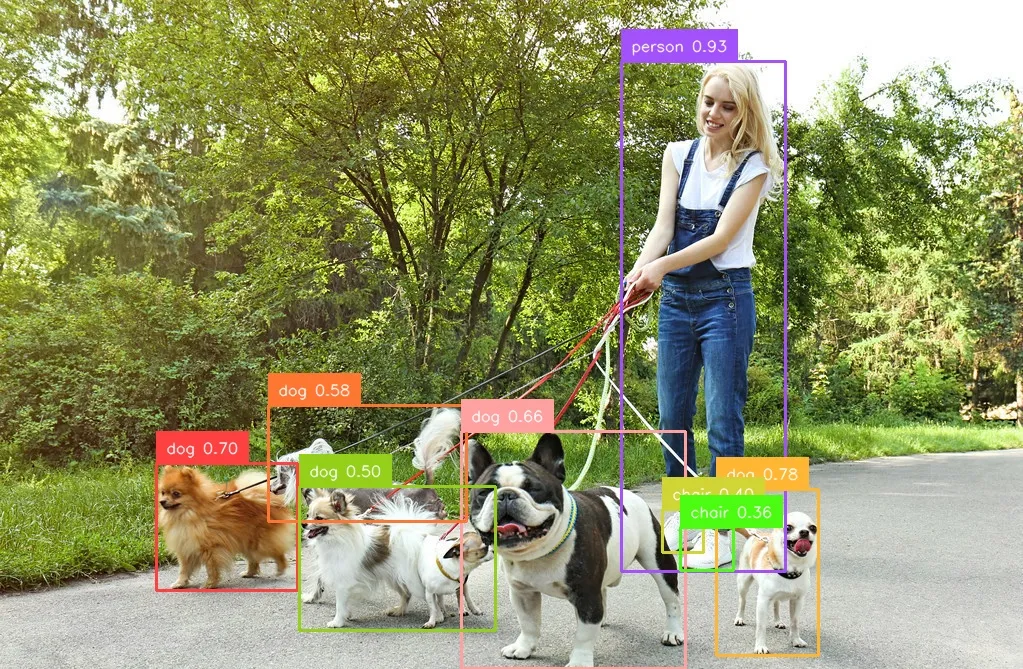
Grounding DINO 能做的事情包括理解文字信息,找出图像中文字信息描述的对象。比如告诉Grounding DINO 找出图像中人所在的位置。
在项目根目录下创建test.py文件,位置一定不能错,关系到寻找配置文件的路径。需要输入给模型包括一个图像和一段文字。准备一张图像,再准备一段文字,文字为想要检测的物体,用空格或句号隔开,如: "chair . person . cell . flower"
from groundingdino.util.inference import load_model, load_image, predict, annotate
import cv2
#加载模型
model = load_model("groundingdino/config/GroundingDINO_SwinT_OGC.py", "weights/groundingdino_swint_ogc.pth")
#要预测的图片路径
IMAGE_PATH = "1.jpeg"
#要预测的类别提示,可以输入多个类中间用英文句号隔开
TEXT_PROMPT = "chair . person . cell . flower"
BOX_TRESHOLD = 0.35
TEXT_TRESHOLD = 0.25
image_source, image = load_image(IMAGE_PATH)
boxes, logits, phrases = predict(
model=model,
image=image,
caption=TEXT_PROMPT,
box_threshold=BOX_TRESHOLD,
text_threshold=TEXT_TRESHOLD
)
annotated_frame = annotate(image_source=image_source, boxes=boxes, logits=logits, phrases=phrases)
#保存预测的图片,保存到outputs文件夹中,名称为annotated_image.jpg
cv2.imwrite("annotated_image.jpg", annotated_frame)
执行代码:
得到标注结果的图像:



自带页面
Grounding DINO 使用代码推理还有一个更方便的网页端推理页面。在demo目录下面的gradio_demo.py 是一个python实现的前端推理页面。
由于我在写这篇文章时发现直接跑有点问题,所以需要稍作修改。主要修改在load_model_hf函数中,修改了模型文件的加载方式。原本从huggingface获取但是模型文件已经不在了,修改成使用上面下载的模型。
import argparse
from functools import partial
import cv2
import requests
import os
from io import BytesIO
from PIL import Image
import numpy as np
from pathlib import Path
import warnings
import torch
# prepare the environment
os.system("python setup.py build develop --user")
os.system("pip install packaging==21.3")
os.system("pip install gradio==3.50.2")
warnings.filterwarnings("ignore")
import gradio as gr
from groundingdino.models import build_model
from groundingdino.util.slconfig import SLConfig
from groundingdino.util.utils import clean_state_dict
from groundingdino.util.inference import annotate, load_image, predict
import groundingdino.datasets.transforms as T
from huggingface_hub import hf_hub_download
# Use this command for evaluate the Grounding DINO model
config_file = "groundingdino/config/GroundingDINO_SwinT_OGC.py"
ckpt_repo_id = "ShilongLiu/GroundingDINO"
ckpt_filenmae = "weights/groundingdino_swint_ogc.pth"
def load_model_hf(model_config_path, repo_id, filename, device='cpu'):
args = SLConfig.fromfile(model_config_path)
model = build_model(args)
args.device = device
# cache_file = hf_hub_download(repo_id=repo_id, filename=filename)
# checkpoint = torch.load(cache_file, map_location='cpu')
checkpoint = torch.load(filename, map_location='cpu')
log = model.load_state_dict(clean_state_dict(checkpoint['model']), strict=False)
# print("Model loaded from {} \n => {}".format(cache_file, log))
_ = model.eval()
return model
def image_transform_grounding(init_image):
transform = T.Compose([
T.RandomResize([800], max_size=1333),
T.ToTensor(),
T.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
])
image, _ = transform(init_image, None) # 3, h, w
return init_image, image
def image_transform_grounding_for_vis(init_image):
transform = T.Compose([
T.RandomResize([800], max_size=1333),
])
image, _ = transform(init_image, None) # 3, h, w
return image
model = load_model_hf(config_file, ckpt_repo_id, ckpt_filenmae)
def run_grounding(input_image, grounding_caption, box_threshold, text_threshold):
init_image = input_image.convert("RGB")
original_size = init_image.size
_, image_tensor = image_transform_grounding(init_image)
image_pil: Image = image_transform_grounding_for_vis(init_image)
# run grounidng
boxes, logits, phrases = predict(model, image_tensor, grounding_caption, box_threshold, text_threshold, device='cpu')
annotated_frame = annotate(image_source=np.asarray(image_pil), boxes=boxes, logits=logits, phrases=phrases)
image_with_box = Image.fromarray(cv2.cvtColor(annotated_frame, cv2.COLOR_BGR2RGB))
return image_with_box
if __name__ == "__main__":
parser = argparse.ArgumentParser("Grounding DINO demo", add_help=True)
parser.add_argument("--debug", action="store_true", help="using debug mode")
parser.add_argument("--share", action="store_true", help="share the app")
args = parser.parse_args()
block = gr.Blocks().queue()
with block:
gr.Markdown("# [Grounding DINO](https://github.com/IDEA-Research/GroundingDINO)")
gr.Markdown("### Open-World Detection with Grounding DINO")
with gr.Row():
with gr.Column():
input_image = gr.Image(source='upload', type="pil")
grounding_caption = gr.Textbox(label="Detection Prompt")
run_button = gr.Button(label="Run")
with gr.Accordion("Advanced options", open=False):
box_threshold = gr.Slider(
label="Box Threshold", minimum=0.0, maximum=1.0, value=0.25, step=0.001
)
text_threshold = gr.Slider(
label="Text Threshold", minimum=0.0, maximum=1.0, value=0.25, step=0.001
)
with gr.Column():
gallery = gr.outputs.Image(
type="pil",
# label="grounding results"
).style(full_width=True, full_height=True)
# gallery = gr.Gallery(label="Generated images", show_label=False).style(
# grid=[1], height="auto", container=True, full_width=True, full_height=True)
run_button.click(fn=run_grounding, inputs=[
input_image, grounding_caption, box_threshold, text_threshold], outputs=[gallery])
block.launch(server_name='0.0.0.0', server_port=7579, debug=args.debug, share=args.share)
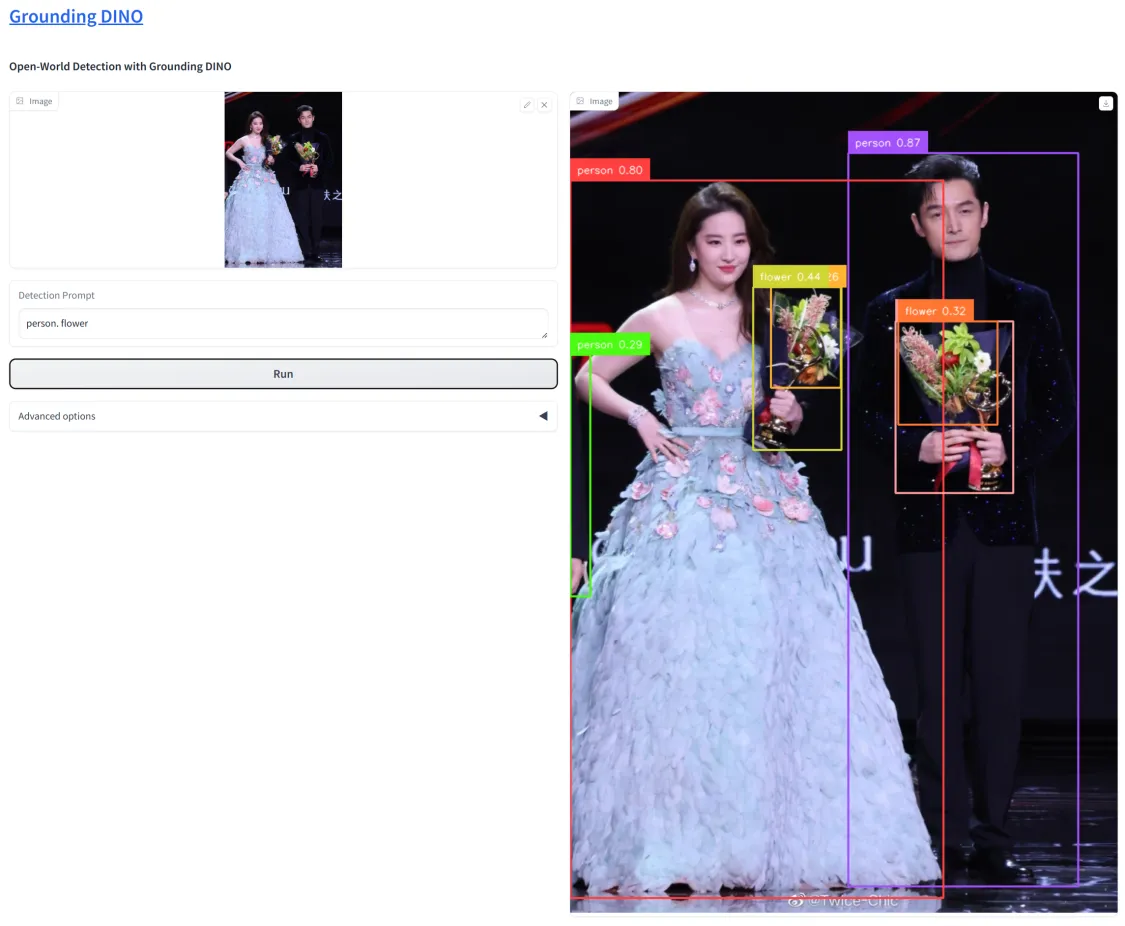
执行 python demo/gradio_demo.py ,注意一定要在这个路径下。首先会安装一些库,然后启动
hon3.10/site-packages (from anyio->httpx->gradio==3.50.2) (1.3.1)
final text_encoder_type: bert-base-uncased
Running on local URL: http://0.0.0.0:7579
To create a public link, set `share=True` in `launch()`.
IMPORTANT: You are using gradio version 3.50.2, however version 4.44.1 is available, please upgrade.
--------
打开 http://IP:7579/ 就能看到页面。上传图片完成推理
各位亦菲、胡歌们,觉得不错请支持点赞,谢谢~
多模态模型 Grounding DINO 初识的更多相关文章
- 全网最详细中英文ChatGPT接口文档(四)30分钟快速入门ChatGPT——Models模型
@ 目录 Models Overview 概述 GPT-4 Limited beta GPT-3.5 Feature-specific models 特定功能的模型 Finding the right ...
- 大规模 Transformer 模型 8 比特矩阵乘简介 - 基于 Hugging Face Transformers、Accelerate 以及 bitsandbytes
引言 语言模型一直在变大.截至撰写本文时,PaLM 有 5400 亿参数,OPT.GPT-3 和 BLOOM 有大约 1760 亿参数,而且我们仍在继续朝着更大的模型发展.下图总结了最近的一些语言模型 ...
- Multi-modal Sentence Summarization with Modality Attention and Image Filtering 论文笔记
文章已同步更新在https://ldzhangyx.github.io/,欢迎访问评论. 五个月没写博客了,不熟悉我的人大概以为我挂了…… 总之呢这段时间还是成长了很多,在加拿大实习的两个多月来 ...
- python之路—从入门到放弃
python基础部分 函数 初识函数 函数进阶 装饰器函数 迭代器和生成器 内置函数和匿名函数 递归函数 常用模块 常用模块 模块和包 面向对象 初识面向对象 面向对象进阶 网络编程 网络编程 并发编 ...
- 预训练模型——开创NLP新纪元
预训练模型--开创NLP新纪元 论文地址 BERT相关论文列表 清华整理-预训练语言模型 awesome-bert-nlp BERT Lang Street huggingface models 论文 ...
- CVPR2022 Oral OGM-GE阅读笔记
标题:Balanced Multimodal Learning via On-the-fly Gradient Modulation(CVPR 2022 Oral) 论文:https://arxiv. ...
- ChatGPT/InstructGPT详解
作者:京东零售 刘岩 前言 GPT系列是OpenAI的一系列预训练文章,GPT的全称是Generative Pre-Trained Transformer,顾名思义,GPT的目的就是通过Transfo ...
- 加速 Document AI (文档智能) 发展
在企业的数字工作流中充满了各种文档,包括信件.发票.表格.报告.收据等,我们无法自动提取它们的知识.如今随着文本.视觉和多模态人工智能的进步,我们有可能解锁这些知识,这篇文章向你展示了你的团队该如何使 ...
- ChatGPT|一文读懂GPT-4!
前言 大家好,今天早上一早醒来,发现各大科技圈公众号平台开始刷屏OpenAI发布的新模型GPT4.0,看这个版本号就已经知道又是一大波特性的更新. 于是立马起来开始学习! GPT-4 发布视频(202 ...
- 借AI之势,打破创意与想象的边界
不要做这个时代的最后一只恐龙. IMMENSE.36氪|作者 1811年11月,英国,诺丁汉市西北一处小镇里,一群愤怒的纺织工人挥舞着锤头与斧子,一窝蜂地冲进车间里,将几台机器砸得粉碎. 后来,这场运 ...
随机推荐
- 1. Calcite元数据创建
1. 简介 Calcite 是一款来自 Apache 的开源动态数据管理框架,核心功能是提供 SQL 查询解析.优化及执行等基础能力,以灵活支持多种数据源,广泛应用于各类数据处理系统.以下从其功能特性 ...
- 云电脑Win7系统安装报错详解:问题与解决方案
本文分享自天翼云开发者社区<云电脑Win7系统安装报错详解:问题与解决方案>,作者:每日知识小分享 随着云计算技术的快速发展,越来越多的人开始使用云电脑.然而,在为云电脑安装Win7系统时 ...
- 【忍者算法】从图书馆编目到数组搜索:探索缺失的第一个正整数|LeetCode 41 缺失的第一个正整数
从图书馆编目到数组搜索:探索缺失的第一个正整数 生活中的算法 想象你是一位图书馆管理员,正在整理一排连续编号的图书.这些书应该从1号开始按顺序排列,但是有些编号的书不见了.你的任务是找出第一个缺失的编 ...
- Linux中如何将txt文件转为png格式
Linux中如何将txt文件转为png格式 linux将txt文件转为png格式如果文本中没有中文,使用enscript,如果文本包含中文,使用paps命令.但是实际使用中,paps部分版本也不支持中 ...
- Codeforces 319B Psychos in a Line 题解 [ 绿 ] [ 单调栈 ] [ 动态规划 ] [ adhoc ]
Psychos in a Line:很好的单调栈优化 dp 题! 观察 我们先观察,一个精神病人会一直杀到什么时候.显然,会杀到右边第一个比他大的精神病人那里,然后他就杀不动了. 因此我们可以从右往左 ...
- Docker启动Nginx
Docker启动Nginx 搜索镜像 docker search nginx 拉取镜像 这里拉取的官方镜像 docker pull nginx 创建挂载目录 将nginx的文件都放在/opt/ngin ...
- JUC相关知识点总结
Java JUC(java.util.concurrent)是Java并发编程的核心工具包,提供了丰富的并发工具类和框架.以下是JUC的主要知识点,按难易程度分类,供你参考: 1. 基础概念与工具类 ...
- C# 将list进行随机排序
private List<T> RandomSortList<T>(List<T> ListT) { Random random = new Random(); L ...
- Vulnhub-Node
利用信息收集拿到路径得到账户密码,下载备份文件,base64解密后,利用fcrackzip爆破zip压缩包,得到一个文件,查看app.js,发现泄露的账户密码,连接ssh,成功连接,利用ubuntu历 ...
- k8s dial tcp 127.0.0.1:6443: connect: connection refused排查流程及解决思路
前言 k8s 集群中,使用 kubelet 报错,如下: The connection to the server 127.0.0.1:6443 was refused - did you speci ...