再谈Mysql undo log, redo log与binlog
一、undo log
1、undo log有两个作用
提供回滚和多个行版本控制(MVCC)。
在数据修改的时候,不仅记录了redo log,还记录了对应的undo,如果因为某些原因事务失败而回滚,可以借助该undo进行回滚。这对应其原子性。
undo log和redo log记录物理日志不一样,他是逻辑日志。可以认为当delete一条记录是,undo log中记录一条对应的insert记录,反之亦然,当update一条记录时,他记录一条对应相反的update记录。
当执行rollback时,就可以从undo log中的逻辑记录读取到相应的内容并进行回滚,有时候应用带行版本控制的时候,也是用过undo log来实现:当读取带某一行的其他事务锁定时,它可以从undo log中分析出改行记录以前的数据是什么,从而提供该行版本信息,让用户实现非锁定一致性读取。
undo log采用段的方式来记录的,每个undo操作在记录的时候占用一个undo log segment。
另外,undo log也会产生redo log,因为undo log也要实现持久性的保护。
- delete操作实际上不会立即直接删除,而是将delete对象打上delete flag,标记为删除,最终的删除操作是purge线程完成的。
- update分为两种情况:update的列是否是主键列。
- 如果不是主键列,在undo log中直接反向记录是如何update的。即update是直接进行的。
- 如果是主键列,update分两部执行:先删除该行,再插入一行目标行。
2、undo log的存储方式
innoDB存储引擎对undo的管理采用段的方式。rollback segment称为回滚段,每个回滚段中有1024个undo log segment。
MySQL 5.5之后可以支持128个rollback segment,即支持128*1024个undo操作,还可以通过变量innodb_undo_logs自定义多少个rollback segment,默认值为128。
undo log默认存放在共享表空间中。即保存数据的ibdata1中。
默认rollback segment全部写在一个文件中,但可以通过设置变量innodb_undo_tablespaces平均分配到多个文件中。
二、redo log
redo log包括两部分:一是内存中的日志缓冲(redo log buffer),该部分日志是易失性的;二是磁盘上的重做日志文件(redo log file),该部分日志是持久的。
假设我们有一条sql语句:
update user_table set name=‘java3y’ where id = ‘3’
MySQL执行这条SQL语句,肯定是先把id=3的这条记录查出来,然后将name字段给改掉。这没问题吧?
实际上Mysql的基本存储结构是页(记录都存在页里边),所以MySQL是先把这条记录所在的页找到,然后把该页加载到内存中,将对应记录进行修改。
现在就可能存在一个问题:如果在内存中把数据改了,还没来得及落磁盘,而此时的数据库挂了怎么办?显然这次更改就丢了。
如果每个请求都需要将数据立马落磁盘之后,那速度会很慢,MySQL可能也顶不住。所以MySQL是怎么做的呢?
MySQL引入了redo log,内存写完了,然后会写一份redo log/undo log,这份redo log记载着这次在某个页上做了什么修改。
其实写redo log的时候,也会有buffer,是先写buffer,再真正落到磁盘中的。至于从buffer什么时候落磁盘,会有配置供我们配置。
写redo log也是需要写磁盘的,但它的好处就是顺序IO(我们都知道顺序IO比随机IO快非常多)。
所以,redo log的存在为了:当我们修改的时候,写完内存了,提交后但数据还没真正写到磁盘的时候。此时我们的数据库挂了,我们可以根据redo log来对数据进行恢复。因为redo log是顺序IO,所以写入的速度很快,并且redo log记载的是物理变化(xxxx页做了xxx修改),文件的体积很小,恢复速度很快。
redo log的作用是为持久化而生的,对应其持久性。写完内存,如果数据库挂了,那我们可以通过redo log来恢复内存还没来得及刷到磁盘的数据,将redo log加载到内存里边,那内存就能恢复到挂掉之前的数据了。
三、binlog
binlog适用于主从复制和数据恢复。
binlog记录了数据库表结构和表数据变更,比如update/delete/insert/truncate/create。它不会记录select(因为这没有对表没有进行变更)。
binlog我们可以简单理解为:存储着每条变更的SQL语句(当然从下面的图看来看,不止SQL,还有XID「事务Id」等等)。
binlog日志格式
binlog日志有三种格式,分别为STATMENT、ROW和MIXED。
在 MySQL 5.7.7之前,默认的格式是STATEMENT,MySQL 5.7.7之后,默认值是ROW。日志格式通过binlog-format指定。
STATMENT
基于SQL语句的复制(statement-based replication, SBR),每一条会修改数据的sql语句会记录到binlog中。
优点:不需要记录每一行的变化,减少了binlog日志量,节约了IO, 从而提高了性能;
缺点:在某些情况下会导致主从数据不一致,比如执行sysdate()、slepp()等。
ROW
基于行的复制(row-based replication, RBR),不记录每条sql语句的上下文信息,仅需记录哪条数据被修改了。
优点:不会出现某些特定情况下的存储过程、或function、或trigger的调用和触发无法被正确复制的问题;
缺点:会产生大量的日志,尤其是alter table的时候会让日志暴涨
MIXED
基于STATMENT和ROW两种模式的混合复制(mixed-based replication, MBR),一般的复制使用STATEMENT模式保存binlog,对于STATEMENT模式无法复制的操作使用ROW模式保存binlog。
四、讨论
1、redolog 与binlog的三点不同
①redo log是InnoDB特有的;binlog是MySQL的Server层实现的,所有引擎都可以使用。
②redo log是物理日志,记录的是在某个数据页上做了什么修改;binlog是逻辑日志,记录的是这个语句的原始逻辑,比如 “给ID=2这一行的c字段加1”.
③redo log是循环写的,空间固定会用完;binlog是可以追加写入的,在文件写道一定大小后会切换到下一个,不会覆盖以前的日志。
我们来看看InnoDB引擎在执行下列MySQL语句的流程:
update T set c=c+1 where ID=2;
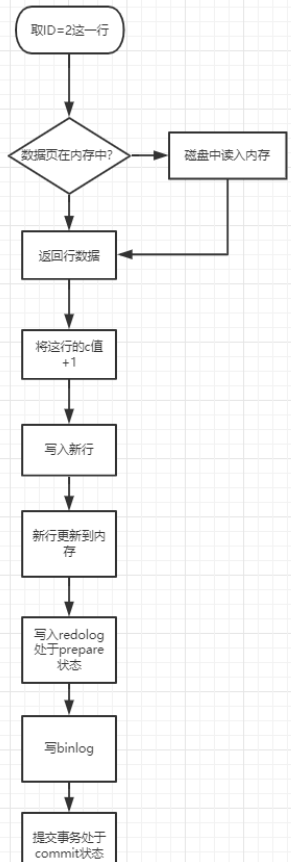
1、执行器先找到引擎取ID=2这一行。ID是主键,引擎直接用树搜索找到这一行,如果ID=2这一行所在的数据页本来就在内存中,就直接返回给执行器;否则,需要先从磁盘读入内存,然后再返回。
2、执行器拿到引擎给的行数据,把这个值加上1,比如原来是N,现在是N+1,得到新的一行数据,再调用引擎接口写入这行新数据。
3、引擎将这行新数据更新到内存中,同时将这个更新操作记录到redo log里面,此时redo log处于prepare状态。然后告知执行器执行完成了,随时可以提交事务。
4、执行器生成这个操作的binlog,并把binlog写入磁盘。
5、执行器调用引擎提交事务接口,引擎把刚刚写入的redo log改成提交状态,更新完成。
我们看到,最后三部被拆成了两个步骤:prepare和commit,这就是两阶段提交。
2、两阶段提交
两阶段提交是为了让两份日志之间的逻辑一致,binlog会记录所有的逻辑操作,并且采用追加写的形式。同时系统会定期做整库备份。这里的定期取决于系统的重要性,可以是一天一备,也可以是一周一备。
如果需要恢复到指定的某一秒,比如某天下午两点发现中午十二点有一次误删表,需要找回数据,那么我们可以这么做:
- 首先,找到最近的一次全量备份,如果你运气好,该备份那个就是昨天晚上的一个备份,从这个备份恢复到数据库。
- 从备份的时间点开始,将备份的binlog依次取出来,重放如中午误删表之前的哪个时刻。
3、为什么需要两阶段提交?
由于redolog和binlog是两个独立的逻辑,如果不用两阶段提交,要么就是先写完redo log,再写binlog,或者采用反过来的顺序,来看下会有什么问题。
仍然用前面的update语句来做例子,假设当前ID=2的行,字段c的值是0,在假设执行update语句过程中在写完第一个日志后,第二个日志还没有写完期间发生了crash,那么分为两种情况。
1、先写redo log后写binlog。假设在redo log写完,binlog没有写完的时候,MySQL进程异常重启。由于我们前面说过的,redo log写完之后,系统即使崩溃,仍然能够把数据恢复回来,所以恢复后这一行c的值是1.由于binlog没有写完就crash了,这时候binlog里面就没有记录这个语句,因此之后备份日志的时候,存起来的binlog里面就没有这条语句。如果需要使用这个binlog来恢复临时库的话,由于这个语句的binlog丢失,这个临时库就会少了这一次的更新,回复出来的这一行c的值就是0,与原库不同。
2、先写binlog后写redo log。如果binlog写完之后crash,由于redo log还没写,崩溃恢复以后这个事务无效,所以这一行的c的值是0.但是binlog里面已经记录了把c从0修改为1这个日志,所以之后再用binlog来恢复的时候就多了一个事务出来,恢复出来的这一行的值就是1,与原库的值不同。
在两阶段提交的不同时刻MySQL出现异常,重启后会出现什么情况
我们假设在redo log处于prepare阶段,写binlog之前为时刻A,在写binlog之后,redo log处于commit阶段之前为时刻B
如果在时刻A发生crash,由于binlog还没有写,redo log也还没有提交,所以崩溃恢复的时候,这个事务会回滚。这时候,binlog还没写,所以也不会传到备库中,binlog和redo log都没有写入,相当于没有执行这条命令。所以MySQL重启后和将来使用binlog进行数据恢复的数据库的状态是一样的。
如果在时刻B发生crash,这时候binlog写完,redo log还没有commit,那么在崩溃恢复时MySQL会做以下判断规则:
1、如果redo log里面的事务是完整的,也就是已经有了commit标识,则直接提交;
2、如果redo log里面的事务只有完整的prepare,则判断对应的事务binlog是否存在并完整:
a. 如果是,则提交事务。
b. 否则,回顾事务。
MySQL怎么知道binlog是完整的?
一个事务的binlog是有完整格式的:
- statement格式的binlog,最后会有COMMIT;
- row格式的binlog,最后会有一个XID event。
另外,在MySQL 5.6.2版本以后,还引入了binlog-checksum参数,用来验证binlog内容和正确性,对于binlog日志由于磁盘的原因,可能会在日志中间出错的情况,MySQL可以通过校验checksum的结果来发现,所以,MySQL还是有办法验证事务binlog的完整性的。
redo log和binlog是怎么关联起来的?
他们都有一个共同的数据字段,叫XID。奔溃恢复的时候,会被顺序扫描redo log:
- 如果碰到既有prepare,又有commit的redo log,就直接提交。
- 如果碰到只有prepare,没有commit的redo log,就拿着XID去binlog找对应的事情。
处于prepare阶段的redolog加上完整的binlog,重启就能恢复,MySQL为什么要这么设计?
因为binlog一旦写入完成之后,那么这个binlog是完整的,如果这个时候MySQL发生崩溃,在重新启动之后,该binlog会被从库使用,所以主库也要提交这个事务,采用这个策略,主库和备库的数据就保证了一致性。
redo log一般设置多大?
如果redo log太小,会导致文件很快就被写满,然后不得不强行刷redo log,很容易就会使MySQL抖,这样WAL机制的能力就发挥不出来了,如果磁盘足够大,那么可以设置为4个1GB。
正常运行中的实例,数据写入后的最终落盘,是从redo log更新过来的还是从buffer pool更新过来的?
redo log并没有记录数据页的完整数据,所以他并没有能力自己去更新磁盘数据页,也就不存在"数据最终落盘,是由redo log更新过去" 的情况。
1、如果正常运行的实例,数据页被修改后,跟磁盘的数据页不一致,成为脏页,最终数据落盘,就是把内存中的数据页写盘,这个过程,甚至与redo log毫无关系。
2、再崩溃恢复场景中,InnoDB如果判断一个数据页可能再崩溃恢复的时候丢失了更新,就会把他读到内存中,然后让redo log更新内存内容,更新之后,内存页变为脏页,就回到了第一种情况的状态。
redo log buffer 是什么? 实现修改内存,还是先写redo log文件?
再一个事务更新过程中,日志是要写多次的。例如
begin;
insert into t1 ...
insert into t2 ...
commit;
这个事务要往两个表中插入记录,插入数据的过程中,生成的日志都先保存起来,但又不能再还没commit的时候就直接写道redo log文件里。
所以redo log buffer 就是一块内存,用来保存redo日志的,也就是说,再执行第一个insert的时候,数据的内存被修改了,redo log buffer 也写入了日志。
但是,真正把日志写到redo log文件,是在执行commit语句的时候做的(innodb存储引擎刷日志的规则之一),单独执行一个更新语句的时候,InnoDB会自己启动一个事务,再语句执行完成的时候提交。过程跟上面一样,只不过是压缩到了一个语句里面完成。
4、日志刷盘的规则
log buffer中未刷到磁盘的日志称为脏日志(dirty log)。
在上面的说过,默认情况下事务每次提交的时候都会刷事务日志到磁盘中,这是因为变量 innodb_flush_log_at_trx_commit 的值为1。但是innodb不仅仅只会在有commit动作后才会刷日志到磁盘,这只是innodb存储引擎刷日志的规则之一。
刷日志到磁盘有以下几种规则:
1.发出commit动作时。已经说明过,commit发出后是否刷日志由变量 innodb_flush_log_at_trx_commit 控制。
2.每秒刷一次。这个刷日志的频率由变量 innodb_flush_log_at_timeout 值决定,默认是1秒。要注意,这个刷日志频率和commit动作无关。
3.当log buffer中已经使用的内存超过一半时。
4.当有checkpoint时,checkpoint在一定程度上代表了刷到磁盘时日志所处的LSN位置。
再谈Mysql undo log, redo log与binlog的更多相关文章
- Mysql undo与redo Log
http://mysql.taobao.org/monthly/2015/04/01/ http://www.cnblogs.com/Bozh/archive/2013/03/18/2966494.h ...
- 说说MySQL中的Redo log Undo log都在干啥
在数据库系统中,既有存放数据的文件,也有存放日志的文件.日志在内存中也是有缓存Log buffer,也有磁盘文件log file,本文主要描述存放日志的文件. MySQL中的日志文件, ...
- 【转】说说MySQL中的Redo log Undo log都在干啥
阅读目录(Content) 1 undo 1.1 undo是啥 1.2 undo参数 1.3 undo空间管理 2 redo 2.1 redo是啥 2.2 redo 参数 2.3 redo 空间管理 ...
- 深入学习MySQL 02 日志系统:bin log,redo log,undo log
上一篇文章中,我们了解了一条查询语句的执行过程,按理说这篇应该讲一条更新语句的执行过程,但这个过程比较复杂,涉及到了好几个日志与事物,所以先梳理一下3个重要的日志,bin log(归档日志).redo ...
- MySQL中的redo log和undo log
MySQL中的redo log和undo log MySQL日志系统中最重要的日志为重做日志redo log和归档日志bin log,后者为MySQL Server层的日志,前者为InnoDB存储引擎 ...
- 再谈mysql锁机制及原理—锁的诠释
加锁是实现数据库并发控制的一个非常重要的技术.当事务在对某个数据对象进行操作前,先向系统发出请求,对其加锁.加锁后事务就对该数据对象有了一定的控制,在该事务释放锁之前,其他的事务不能对此数据对象进行更 ...
- 详细分析MySQL事务日志(redo log和undo log)
innodb事务日志包括redo log和undo log.redo log是重做日志,提供前滚操作,undo log是回滚日志,提供回滚操作. undo log不是redo log的逆向过程,其实它 ...
- 详细分析MySQL事务日志(redo log和undo log) 表明了为何mysql不会丢数据
innodb事务日志包括redo log和undo log.redo log是重做日志,提供前滚操作,undo log是回滚日志,提供回滚操作. undo log不是redo log的逆向过程,其实它 ...
- 深入理解MySQL系列之redo log、undo log和binlog
事务的实现 redo log保证事务的持久性,undo log用来帮助事务回滚及MVCC的功能. InnoDB存储引擎体系结构 redo log Write Ahead Log策略 事务提交时,先写重 ...
- 【MySQL (六) | 详细分析MySQL事务日志redo log】
Reference: https://www.cnblogs.com/f-ck-need-u/archive/2018/05/08/9010872.html 引言 为了最大程度避免数据写入时 IO ...
随机推荐
- Python中构建全局字典的详细指南
在Python编程中,全局变量是指在整个程序运行期间都可以访问的变量.全局字典作为一种特殊的全局变量,可以存储各种类型的数据,包括字符串.数字.列表.元组等,这使得它在数据管理和跨模块通信方面非常有用 ...
- ArgoCD 简介
fork https://github.com/DevopsChina/lab/tree/main/deploy/lab04-argocd 1. ArgoCD 简介 基于 kubernetes 的声明 ...
- consul注册和删除命令
curl -X PUT -d '{"id": "redis-xxx","name": "redis-xxx"," ...
- Qt交叉编译整理的几点说明
关于交叉编译,对于初学者来说是个极难跨过去的砍(一旦跨过去了,以后遇到需要交叉编译的时候都是顺水推舟.信手拈来.),因为需要搭建交叉编译环境,好在现在厂家提供的板子基本上都是测试好的环境,尤其是提供的 ...
- matlab中mat文件的生成和读取
1.mat文件的生成 (1)直接在Matlab中创建并保存矩阵数据 打开Matlab软件,点击左上角文件(File),然后点击新建(new),选择变量(Variable),就新建了一个mat文件. 点 ...
- eclipse中汉字横着的问题解决
最近在eclipse中加上中午注释,出现那种汉字是横着的情况,解决方案如下: 方法一: 同一种字体有两种显示方式,比如Fixedsys Excelsior 3.01和@Fixedsys Excelsi ...
- 从零开始的Python世界生活——语法基础先导篇(Python小白零基础光速入门上手)
从零开始的Python世界生活--语法基础先导篇(Python小白零基础光速入门上手) 1. 准备阶段 1.1 下载并安装Python 1.1.1 下载步骤: 访问Python官方网站:点击这里下载P ...
- 第二章 dubbo源码解析目录
6.1 如何在spring中自定义xml标签 dubbo自定义了很多xml标签,例如<dubbo:application>,那么这些自定义标签是怎么与spring结合起来的呢?我们先看一个 ...
- SpringSecurity详解
认证+授权代码实现 Spring Security是 一种基于 Spring AOP 和 Servlet 过滤器的安全框架.它提供全面的安全性解决方案,同时在 Web 请求级和方法调用级处理身份确认和 ...
- ZUC-生成随机序列
问题 ZUC国标上的三个例子生成随机序列 例子1 例子2 例子3 代码1 #define _CRT_SECURE_NO_WARNINGS #include <stdio.h> #inclu ...