C# TorchSharp 图像分类实战:VGG大规模图像识别的超深度卷积网络
教程名称:使用 C# 入门深度学习
作者:痴者工良
教程地址:
电子书仓库:https://github.com/whuanle/cs_pytorch
Maomi.Torch 项目仓库:https://github.com/whuanle/Maomi.Torch
图像分类 | VGG大规模图像识别的超深度卷积网络
本文主要讲解用于大规模图像识别的超深度卷积网络 VGG,通过 VGG 实现自有数据集进行图像分类训练模型和识别,VGG 有 vgg11、vgg11_bn、vgg13、vgg13_bn、vgg16、vgg16_bn、vgg19、vgg19_bn 等变种,VGG 架构的实现可参考论文:https://arxiv.org/abs/1409.1556
论文中文版地址:
数据集
本文主要使用经典图像分类数据集 CIFAR-10 进行训练,CIFAR-10 数据集中有 10 个分类,每个类别均有 60000 张图像,50000 张训练图像和 10000 张测试图像,每个图像都经过了预处理,生成 32x32 彩色图像。
CIFAR-10 的 10 个分类分别是:
airplane
automobile
bird
cat
deer
dog
frog
horse
ship
truck
下面给出几种数据集的本地化导入方式。
直接下载
由于 CIFAR-10 是经典数据集,因此 TorchSharp 默认支持下载该数据集,但是由于网络问题,国内下载数据库需要开飞机,数据集自动下载和导入:
// 加载训练和验证数据
var train_dataset = datasets.CIFAR10(root: "E:/datasets/CIFAR-10", train: true, download: true, target_transform: transform);
var val_dataset = datasets.CIFAR10(root: "E:/datasets/CIFAR-10", train: false, download: true, target_transform: transform);
opendatalab 数据集社区
opendatalab 是一个开源数据集社区仓库,里面有大量免费下载的数据集,借此机会给读者讲解一下如何从 opendatalab 下载数据集,这对读者学习非常有帮助。
CIFAR-10 数据集仓库地址:
https://opendatalab.com/OpenDataLab/CIFAR-10/cli/main
打开 https://opendatalab.com 注册账号,然后在个人信息中心添加密钥。
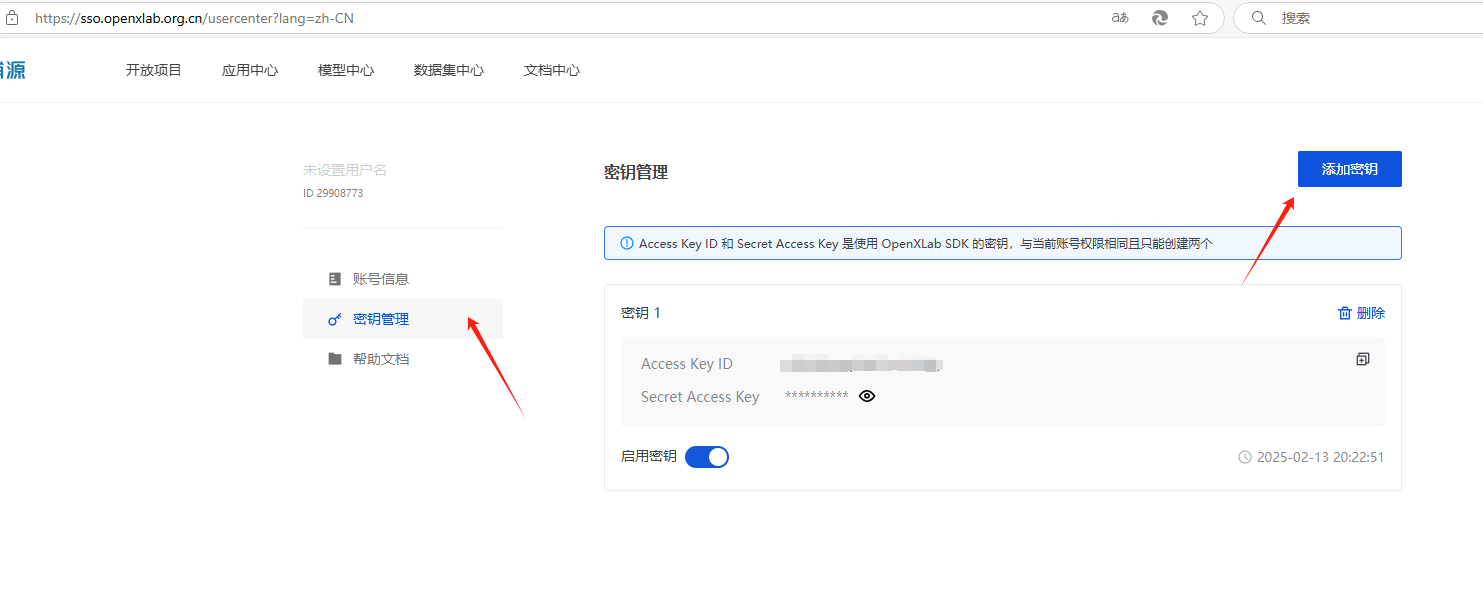
然后下载 openxlab 提供的 cli 工具:
pip install openxlab #安装
安装 openxlab 后,会要求添加路径到环境变量,环境变量地址是 Scripts 地址,示例:
C:\Users\%USER%\AppData\Roaming\Python\Python312\Scripts
接着进行登录,输入命令后按照提示输入 key 和 secret:
openxlab login # 进行登录,输入对应的AK/SK,可在个人中心查看AK/SK
然后打开空目录下载数据集,数据集仓库会被下载到 OpenDataLab___CIFAR-10 目录中:
openxlab dataset info --dataset-repo OpenDataLab/CIFAR-10 # 数据集信息及文件列表查看
openxlab dataset get --dataset-repo OpenDataLab/CIFAR-10 #数据集下载
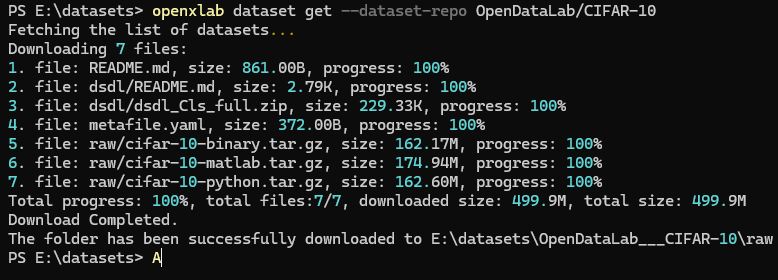
数据集信息及文件列表查看
openxlab dataset info --dataset-repo OpenDataLab/CIFAR-10

下载的文件比较多,但是我们只需要用到 cifar-10-binary.tar.gz,直接解压 cifar-10-binary.tar.gz 到目录中(也可以不解压)。
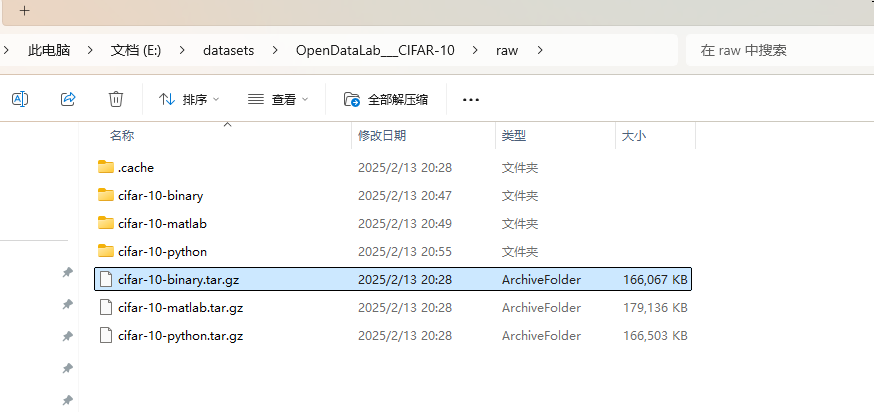
然后导入数据:
// 加载训练和验证数据
var train_dataset = datasets.CIFAR10(root: "E:/datasets/OpenDataLab___CIFAR-10", train: true, download: false, target_transform: transform);
var val_dataset = datasets.CIFAR10(root: "E:/datasets/OpenDataLab___CIFAR-10", train: false, download: false, target_transform: transform);
自定义数据集
Maomi.Torch 提供了自定义数据集导入方式,降低了开发者制作数据集的难度。自定义数据集也要区分训练数据集和测试数据集,训练数据集用于特征识别和训练,而测试数据集用于验证模型训练的准确率和损失值。
测试数据集和训练数据集可以放到不同的目录中,具体名称没有要求,然后每个分类单独一个目录,目录名称就是分类名称,按照目录名称的排序从 0 生成标签值。
├─test
│ ├─airplane
│ ├─automobile
│ ├─bird
│ ├─cat
│ ├─deer
│ ├─dog
│ ├─frog
│ ├─horse
│ ├─ship
│ └─truck
└─train
│ ├─airplane
│ ├─automobile
│ ├─bird
│ ├─cat
│ ├─deer
│ ├─dog
│ ├─frog
│ ├─horse
│ ├─ship
│ └─truck

读者可以参考 exportdataset项目,将 CIFAR-10 数据集生成导出到目录中。
通过自定义目录导入数据集的代码为:
var train_dataset = MM.Datasets.ImageFolder(root: "E:/datasets/t1/train", target_transform: transform);
var val_dataset = MM.Datasets.ImageFolder(root: "E:/datasets/t1/test", target_transform: transform);
模型训练
定义图像预处理转换代码,代码如下所示:
Device defaultDevice = MM.GetOpTimalDevice();
torch.set_default_device(defaultDevice);
Console.WriteLine("当前正在使用 {defaultDevice}");
// 数据预处理
var transform = transforms.Compose([
transforms.Resize(32, 32),
transforms.ConvertImageDtype( ScalarType.Float32),
MM.transforms.ReshapeTransform(new long[]{ 1,3,32,32}),
transforms.Normalize(means: new double[] { 0.485, 0.456, 0.406 }, stdevs: new double[] { 0.229, 0.224, 0.225 }),
MM.transforms.ReshapeTransform(new long[]{ 3,32,32})
]);
因为 TorchSharp 对图像维度处理的兼容性不好,没有 Pytorch 的自动处理,因此导入的图片维度和批处理维度、transforms 处理的维度兼容性不好,容易报错,因此这里需要使用 Maomi.Torch 的转换函数,以便在导入图片和进行图像批处理的时候,保障 shape 符合要求。
分批加载数据集:
// 加载训练和验证数据
var train_dataset = datasets.CIFAR10(root: "E:/datasets/CIFAR-10", train: true, download: true, target_transform: transform);
var val_dataset = datasets.CIFAR10(root: "E:/datasets/CIFAR-10", train: false, download: true, target_transform: transform);
var train_loader = new DataLoader(train_dataset, batchSize: 1024, shuffle: true, device: defaultDevice, num_worker: 10);
var val_loader = new DataLoader(val_dataset, batchSize: 1024, shuffle: false, device: defaultDevice, num_worker: 10);
初始化 vgg16 网络:
var model = torchvision.models.vgg16(num_classes: 10);
model.to(device: defaultDevice);
设置损失函数和优化器:
var criterion = nn.CrossEntropyLoss();
var optimizer = optim.SGD(model.parameters(), learningRate: 0.001, momentum: 0.9);
训练模型并保存:
int num_epochs = 150;
for (int epoch = 0; epoch < num_epochs; epoch++)
{
model.train();
double running_loss = 0.0;
int i = 0;
foreach (var item in train_loader)
{
var (inputs, labels) = (item["data"], item["label"]);
var inputs_device = inputs.to(defaultDevice);
var labels_device = labels.to(defaultDevice);
optimizer.zero_grad();
var outputs = model.call(inputs_device);
var loss = criterion.call(outputs, labels_device);
loss.backward();
optimizer.step();
running_loss += loss.item<float>() * inputs.size(0);
Console.WriteLine($"[{epoch}/{num_epochs}][{i % train_loader.Count}/{train_loader.Count}]");
i++;
}
double epoch_loss = running_loss / train_dataset.Count;
Console.WriteLine($"Train Loss: {epoch_loss:F4}");
model.eval();
long correct = 0;
int total = 0;
using (torch.no_grad())
{
foreach (var item in val_loader)
{
var (inputs, labels) = (item["data"], item["label"]);
var inputs_device = inputs.to(defaultDevice);
var labels_device = labels.to(defaultDevice);
var outputs = model.call(inputs_device);
var predicted = outputs.argmax(1);
total += (int)labels.size(0);
correct += (predicted == labels_device).sum().item<long>();
}
}
double val_accuracy = 100.0 * correct / total;
Console.WriteLine($"Validation Accuracy: {val_accuracy:F2}%");
}
model.save("model.dat");
启动项目后可以直接执行训练,训练一百多轮后,准确率在 70% 左右,损失值在 0.0010 左右,继续训练已经提高不了准确率了。
导出的模型还是比较大的:
513M model.dat
下面来编写图像识别测试,在示例项目 vggdemo 中自带了三张图片,读者可以直接导入使用。
model.load("model.dat");
model.to(device: defaultDevice);
model.eval();
var classes = new string[] {
"airplane",
"automobile",
"bird",
"cat",
"deer",
"dog",
"frog",
"horse",
"ship",
"truck"
};
List<Tensor> imgs = new();
imgs.Add(transform.call(MM.LoadImage("airplane.jpg").to(defaultDevice)).view(1, 3, 32, 32));
imgs.Add(transform.call(MM.LoadImage("cat.jpg").to(defaultDevice)).view(1, 3, 32, 32));
imgs.Add(transform.call(MM.LoadImage("dog.jpg").to(defaultDevice)).view(1, 3, 32, 32));
using (torch.no_grad())
{
foreach (var data in imgs)
{
var outputs = model.call(data);
var index = outputs[0].argmax(0).ToInt32();
// 转换为归一化的概率
// outputs.shape = [1,10],所以取 [dim:1]
var array = torch.nn.functional.softmax(outputs, dim: 1);
var max = array[0].ToFloat32Array();
var predicted1 = classes[index];
Console.WriteLine($"识别结果 {predicted1},准确率:{max[index] * 100}%");
}
}
识别结果:
当前正在使用 cuda:0
识别结果 airplane,准确率:99.99983%
识别结果 cat,准确率:99.83113%
识别结果 dog,准确率:100%
用到的三张图片均从网络上搜索而来:



C# TorchSharp 图像分类实战:VGG大规模图像识别的超深度卷积网络的更多相关文章
- 全卷积网络Fully Convolutional Networks (FCN)实战
全卷积网络Fully Convolutional Networks (FCN)实战 使用图像中的每个像素进行类别预测的语义分割.全卷积网络(FCN)使用卷积神经网络将图像像素转换为像素类别.与之前介绍 ...
- 全卷积网络(FCN)实战:使用FCN实现语义分割
摘要:FCN对图像进行像素级的分类,从而解决了语义级别的图像分割问题. 本文分享自华为云社区<全卷积网络(FCN)实战:使用FCN实现语义分割>,作者: AI浩. FCN对图像进行像素级的 ...
- 【Android自己定义View实战】之自己定义超简单SearchView搜索框
[Android自己定义View实战]之自己定义超简单SearchView搜索框 这篇文章是对之前文章的翻新,至于为什么我要又一次改动这篇文章?原因例如以下 1.有人举报我抄袭,原文链接:http:/ ...
- GAN实战笔记——第四章深度卷积生成对抗网络(DCGAN)
深度卷积生成对抗网络(DCGAN) 我们在第3章实现了一个GAN,其生成器和判别器是具有单个隐藏层的简单前馈神经网络.尽管很简单,但GAN的生成器充分训练后得到的手写数字图像的真实性有些还是很具说服力 ...
- [caffe]深度学习之图像分类模型VGG解读
一.简单介绍 vgg和googlenet是2014年imagenet竞赛的双雄,这两类模型结构有一个共同特点是go deeper.跟googlenet不同的是.vgg继承了lenet以及alexnet ...
- 深度学习原理与框架-卷积网络细节-图像分类与图像位置回归任务 1.模型加载 2.串接新的全连接层 3.使用SGD梯度对参数更新 4.模型结果测试 5.各个模型效果对比
对于图像的目标检测任务:通常分为目标的类别检测和目标的位置检测 目标的类别检测使用的指标:准确率, 预测的结果是类别值,即cat 目标的位置检测使用的指标:欧式距离,预测的结果是(x, y, w, h ...
- 【Android实战】----从Retrofit源代码分析到Java网络编程以及HTTP权威指南想到的
一.简单介绍 接上一篇[Android实战]----基于Retrofit实现多图片/文件.图文上传中曾说非常想搞明确为什么Retrofit那么屌. 近期也看了一些其源代码分析的文章以及亲自查看了源代码 ...
- 经典卷积网络VGG,GoodLeNet,Inception
目录 ImageNet LeNet-5 LeNet-5 Demo AlexNet VGG 1*1 Convolution GoogLeNet Stack more layers? ImageNet L ...
- 深度学习原理与框架-卷积网络细节-经典网络架构 1.AlexNet 2.VGG
1.AlexNet是2012年最早的第一代神经网络,整个神经网络的构架是8层的网络结构.网络刚开始使用11*11获得较大的感受野,随后使用5*5和3*3做特征的提取,最后使用3个全连接层做得分值得运算 ...
- CV3——学习笔记-实战项目(上):如何搭建和训练一个深度学习网络
http://www.mooc.ai/course/353/learn?lessonid=2289&groupId=0#lesson/2289 1.AlexNet, VGGNet, Googl ...
随机推荐
- 使用docker部署自己的网页版chatgpt
如果你有了一个Chat GPT账号想分享给多个人使用,最好还不用禾斗学上网别人就能访问,那么chatgpt-web这个项目可能刚好满足你的需求. 少点命令行,多点可视化,这里采用更直观的方式来搭建ch ...
- 利用Catalina快速重新指定tomcat的代码路径
思路: 在/tomcat/conf/Catalina/localhost目录下,建立对应的xml文件,来定义. 方法: 比如:想在 Http://localhost/test-api 显示,且代码放在 ...
- 出现警告信息 Please enter a commit message to explain why this merge is necessary,
Please enter a commit message to explain why this merge is necessary, # especially if it merges an u ...
- M1芯片pod问题
M1芯片pod问题 换了M1芯片的mac后,在Xcode跑项目报pod错误,提示run pod install更新pod,但是去终端跑命令时又报错 然后在github上看到一个老哥的方法 https: ...
- Fake JSON Server
Fake JSON Server https://github.com/ttu/dotnet-fake-json-server Fake JSON Server 是 Fake REST API,可以作 ...
- 在TOMCAT8.5使用 JOSSO 单点登录(Agent 端)
网上找到的玩法都是用 josso 给的命令行工具加工 tomcat,这个办法有不少问题: 1. tomcat8.5 还不支持 2. 很难配置,这让我险些放弃 tomcat8.5,用 tomcat8,但 ...
- 【服务器安全问题】双防火墙有什么意义?SSH暴力破解如何防范
发现我的服务器有大量的陌生IP尝试SSH登录,似乎想暴力破解. 我个人习惯是服务器提供商开放了所有端口的,同时也没有开启运维软件提供的防火墙emm 这倒是让我想到了 一般服务器提供商(比如阿里云.华为 ...
- Python设计模式(第2版)中文的pdf电子书
Python设计模式(第2版)中文的pdf电子书下载地址:百度云盘,提取码:dmem
- vmstorage如何将原始指标转换为有组织的历史
vmstorage如何将原始指标转换为有组织的历史 参考自:vmstorage-how-it-handles-data-ingestion vmstorage是VictoriaMetrics中负责处理 ...
- 视频直播技术干货(十二):从入门到放弃,快速学习Android端直播技术
本文由陆业聪分享,原题"一文掌握直播技术:实时音视频采集.编码.传输与播放",本文进行了排版和内容优化. 1.引言 从游戏.教育.电商到娱乐,直播技术的应用场景无处不在.随着移动端 ...