python练习-爬虫
场景:
1、网址hppt://xxx.yyy.zzz.cn
2、打开网页后显示 :

3、填上姓名 身份证和验证码,点击查询后,返回查询结果。

4、页面有cookie。
方案一:
- 程序中嵌入浏览器根据网址打开得到页面,
- 然后程序读取记录自动填写数据,
- 程序截取验证码图片,然后解析,并且填入验证码
- 然后程序点击查询得到查询页面,
- 再从查询结果页面DOM解析得到相关数据
方案二:
采用Python。真是牛逼得一塌糊涂。
import requests
from PIL import Image
import pytesseract # 获取cookie
session = requests.Session()
response = session.get("http://example.com")
cookie = response.cookies.get_dict() # 发送HTTP请求,获取响应数据
headers = {
"Cookie": "; ".join([f"{key}={value}" for key, value in cookie.items()]),
}
response = session.get("http://example.com", headers=headers)
content = response.text # 解析响应数据,获取验证码URL
start_position = content.find('<img src="/verifyCode')
end_position = content.find('"', start_position + 10)
captcha_url = 'http://example.com' + content[start_position + 10:end_position] # 发送带cookie的HTTP请求,获取验证码的二进制数据
response = session.get(captcha_url, headers=headers)
captcha_data = response.content # 将二进制图片保存为本地文件
with open('captcha.png', 'wb') as f:
f.write(captcha_data)
# 识别图片中的文字
image = Image.open('captcha.png')
code = pytesseract.image_to_string(image) # 打印验证码内容
print("验证码内容:", code)
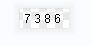
# 7386
至此,关键问题得到解决。
注意得问题:
1、安装requests
2、安装PIL
3、安装pytesseract。其中要另外单独安装与pytesseract配套的Python的OCR识别库。
4.1下载OCR识别库地址 https://digi.bib.uni-mannheim.de/tesseract/
根据你系统进行选择。
4.2下载OCR安装识别库
其中:
4.3配置OCR路径:
4.3.1看一下你安装得目录。如:D:\Program Files\Tesseract-OCR\tesseract.exe
4.3.2系统环境变量中,把D:\Program Files\Tesseract-OCR\tesseract.exe配置进去。
4.4.找到脚本文件 pytesseract.py。编辑修改:
tesseract_cmd = r'D:\Program Files\Tesseract-OCR\tesseract.exe'from os import remove
from os.path import normcase
from os.path import normpath
from os.path import realpath
from pkgutil import find_loader
from tempfile import NamedTemporaryFile
from time import sleep from packaging.version import InvalidVersion
from packaging.version import parse
from packaging.version import Version
from PIL import Image tesseract_cmd = r'D:\Program Files\Tesseract-OCR\tesseract.exe' numpy_installed = find_loader('numpy') is not None
if numpy_installed:
from numpy import ndarray pandas_installed = find_loader('pandas') is not None
if pandas_installed:
import pandas as pd DEFAULT_ENCODING = 'utf-8'
5.可能出现得问题:
常见问题:FileNotFoundError:[WinError 2]系统找不到指定文件。
解决办法:
打开文件pytesseract.py,找到如下代码,将tesseract_cmd的值修改为全路径,再次使用就不会报这个错了。
没了,goodluck!
python练习-爬虫的更多相关文章
- Python简单爬虫入门三
我们继续研究BeautifulSoup分类打印输出 Python简单爬虫入门一 Python简单爬虫入门二 前两部主要讲述我们如何用BeautifulSoup怎去抓取网页信息以及获取相应的图片标题等信 ...
- Ubuntu下配置python完成爬虫任务(笔记一)
Ubuntu下配置python完成爬虫任务(笔记一) 目标: 作为一个.NET汪,是时候去学习一下Linux下的操作了.为此选择了python来边学习Linux,边学python,熟能生巧嘛. 前期目 ...
- Python简单爬虫入门二
接着上一次爬虫我们继续研究BeautifulSoup Python简单爬虫入门一 上一次我们爬虫我们已经成功的爬下了网页的源代码,那么这一次我们将继续来写怎么抓去具体想要的元素 首先回顾以下我们Bea ...
- [Python] 网络爬虫和正则表达式学习总结
以前在学校做科研都是直接利用网上共享的一些数据,就像我们经常说的dataset.beachmark等等.但是,对于实际的工业需求来说,爬取网络的数据是必须的并且是首要的.最近在国内一家互联网公司实习, ...
- python简易爬虫来实现自动图片下载
菜鸟新人刚刚入住博客园,先发个之前写的简易爬虫的实现吧,水平有限请轻喷. 估计利用python实现爬虫的程序网上已经有太多了,不过新人用来练手学习python确实是个不错的选择.本人借鉴网上的部分实现 ...
- GJM : Python简单爬虫入门(二) [转载]
感谢您的阅读.喜欢的.有用的就请大哥大嫂们高抬贵手"推荐一下"吧!你的精神支持是博主强大的写作动力以及转载收藏动力.欢迎转载! 版权声明:本文原创发表于 [请点击连接前往] ,未经 ...
- Python分布式爬虫原理
转载 permike 原文 Python分布式爬虫原理 首先,我们先来看看,如果是人正常的行为,是如何获取网页内容的. (1)打开浏览器,输入URL,打开源网页 (2)选取我们想要的内容,包括标题,作 ...
- Python 网页爬虫 & 文本处理 & 科学计算 & 机器学习 & 数据挖掘兵器谱(转)
原文:http://www.52nlp.cn/python-网页爬虫-文本处理-科学计算-机器学习-数据挖掘 曾经因为NLTK的缘故开始学习Python,之后渐渐成为我工作中的第一辅助脚本语言,虽然开 ...
- 关于Python网络爬虫实战笔记③
Python网络爬虫实战笔记③如何下载韩寒博客文章 Python网络爬虫实战笔记③如何下载韩寒博客文章 target:下载全部的文章 1. 博客列表页面规则 也就是, http://blog.sina ...
- 关于Python网络爬虫实战笔记①
python网络爬虫项目实战笔记①如何下载韩寒的博客文章 python网络爬虫项目实战笔记①如何下载韩寒的博客文章 1. 打开韩寒博客列表页面 http://blog.sina.com.cn/s/ar ...
随机推荐
- Note -「拟阵交」& Solution -「CF 1284G」Seollal
\(\mathscr{Description}\) Link. 给定张含空格和障碍格的 \(n\times m\) 的地图.构造在四连通的空格中间放置墙壁的方案,使得: 所有空格在四连通意义下 ...
- MAUI APK安装到其他手机闪退问题
在本地VS调试一切正常的,生成的APK安装到其他手机 发生闪退了 先是用abd连接 检查日志看: adb -s 192.168.1.10 logcat -v time > e:\log.txt ...
- RabbitMQ-要点简介
Windows下安装RabbitMQ RabbitMQ是流行的开源消息队列系统,用erlang语言开发,RabbitMQ是AMQP(高级消息队列协议)的标准实现. 要安装RabbitMQ,首先要安装E ...
- 如何快速的开发一个完整的iOS直播app(点赞功能)
客户端代码 点击小红心,发送socket给服务器,并且要传递房间Key给服务器,通知给哪个主播点赞,就能传入到对应的分组socket中 怎么传递房间key,房间Key在主播界面,一般一个客户端,只会产 ...
- ElasticSearch架构及详解
1. 图解es内部机制 1.1. 图解es分布式基础 1.1.1es对复杂分布式机制的透明隐藏特性 分布式机制:分布式数据存储及共享. 分片机制:数据存储到哪个分片,副本数据写入. 集群发现机制:cl ...
- 《Linux shell 脚本攻略》第1章——读书笔记
目录 文件描述符及重定向 函数和参数 迭代器 算术比较 文件系统相关测试 字符串进行比较 文件描述符及重定向 echo "This is a sample text 1" > ...
- 安装K8s集群
因阿里云加速服务调整,镜像加速服务自2024年7月起不再支持,拉取镜像,下载网络插件等操作,需要国际联网访问DockerHub. 安装全过程均使用ROOT权限. 1.安装前准备工作 这里采用3台Cen ...
- MongoDB:文档基本CRUD
- K8s 灰度发布实战:通过 Ingress 注解轻松实现流量分割与渐进式发布
在现代微服务架构中,应用的更新和发布是一个高频且关键的操作.如何在不影响用户体验的前提下,安全.平稳地将新版本应用推送到生产环境,是每个开发者和运维团队必须面对的挑战.灰度发布(Gray Releas ...
- 服务器主机:复杂理论的视角与SEO策略
本文分享自天翼云开发者社区<服务器主机:复杂理论的视角与SEO策略>,作者:不知不觉 在数字世界的演变中,服务器主机在信息存储和数据处理方面发挥着核心作用.本文将带你重新认识服务器主机的价 ...