Java集合--LinkedList源码可视化
集合节点保存的都是对象的引用,而非具体值,文中案例仅仅为了方便实现原理的演示。
1. 底层数据结构
LinkedList 基于 双向链表 实现,内部通过 Node<E> 节点相互连接:
private static class Node<E> {
E item;
Node<E> next;
Node<E> prev;
Node(Node<E> prev, E element, Node<E> next) {
this.item = element;
this.next = next;
this.prev = prev;
}
}
在 LinkedList 类中,通过以下字段维护链表头尾:
transient Node<E> first; // 链表的头节点引用
transient Node<E> last; // 链表的尾节点引用
first 始终指向第一个节点,last 始终指向最后一个节点。
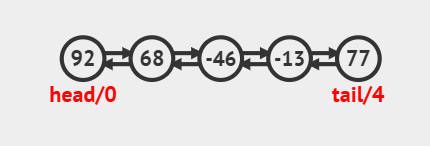
双向链表支持从头或尾进行 快速插入/删除。但不能像数组一样,根据索引下标进行地址计算,所以不支持 随机访问,通过索引访问需要 遍历节点。
1.1. LinkedList 特性
顺序存储:维护插入顺序,但本质为链式结构;
节点插入/删除:在任意位置插入或删除均为 O(1)(找到节点后);
访问效率:按索引访问需 O(n),因为需要从头或尾遍历;
支持 null 元素,保存的是对象引用。
2. 元素插入(增)
LinkedList 提供四种常用插入方式:
| 方法 | 说明 |
|---|---|
add(E e) |
在末尾插入 |
add(int index, E element) |
在指定位置插入 |
addFirst(E e) / offerFirst(E e) |
在头部插入 |
addLast(E e) / offerLast(E e) |
在尾部插入 |
2.1. linkFirst和linkLast 核心源码
link指的是连接节点的意思,first和last分别表示从头部连接(插入)节点和从尾部连接(插入)节点。所以,在学习插入元素时,需要相对这两块源码熟悉。
private void linkFirst(E e) {
final Node<E> f = first;
final Node<E> newNode = new Node<>(null, e, f);
first = newNode;
if (f == null)
last = newNode;
else
f.prev = newNode;
size++;
modCount++;
}
private void linkLast(E e) {
final Node<E> l = last;
final Node<E> newNode = new Node<>(l, e, null);
last = newNode;
if (l == null)
first = newNode;
else
l.next = newNode;
size++;
modCount++;
}
创建新节点并调整前后指针;
首次插入时
first和last同时指向该节点;size++、modCount++支持 fail-fast。
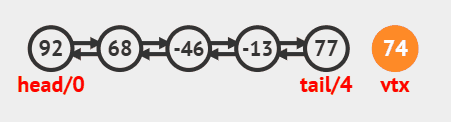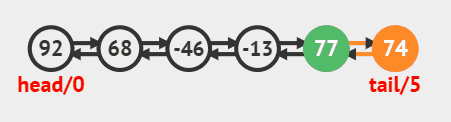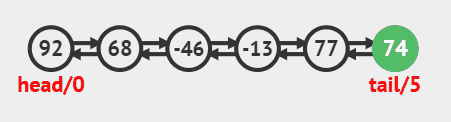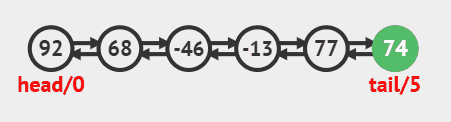
在尾部插入调用linkLast方法即可,源码如下
public void addLast(E e) {
linkLast(e);
}
尾部插入动画效果
在头部插入调用linkFirst方法即可,源码如下
public void addFirst(E e) {
linkFirst(e);
}
头部插入动画效果

2.2. 在中间位置插入
public void add(int index, E element) {
checkPositionIndex(index);
if (index == size)
linkLast(element);
else
linkBefore(element, node(index));
}
void linkBefore(E e, Node<E> succ) {
final Node<E> pred = succ.prev;
final Node<E> newNode = new Node<>(pred, e, succ);
succ.prev = newNode;
if (pred == null)
first = newNode;
else
pred.next = newNode;
size++;
modCount++;
}
node(index)根据索引返回目标节点,内部会判断从头或尾遍历更快;连接新节点至前后节点。
在中间插入的动画效果

2.3. node(index)检索算法(重要)
链表数据结构无法像数组那样,可以直接根据索引下标和首地址来计算目标元素地址,只能从头部first节点或尾部tail节点一步一步的遍历到目标位置,从而获取到目标节点。
源码如下,(具体检索过程的动图可到修改元素章节感受)
Node<E> node(int index) {
// 如果索引在前半部分,从 head 开始向后遍历
if (index < (size >> 1)) {
Node<E> x = first;
for (int i = 0; i < index; i++)
x = x.next;
return x;
} else {
// 否则从 tail 向前遍历
Node<E> x = last;
for (int i = size - 1; i > index; i--)
x = x.prev;
return x;
}
}
算法解析:
将链表逻辑分为两段:前半段
[0, size/2)和后半段[size/2, size);若目标索引位于前半段,则从
first开始,依次沿next找到第index个节点;若在后半段,则从
last开始,沿prev向前遍历直到到达;这种折半遍历相当于对链表元素位置进行“裁剪”,最坏需要遍历
size/2步,平均遍历size/4步,但仍为 O(n)。
适用场景:在随机访问时,通过双向遍历能显著减少平均查找距离,提高链表访问效率。
3. 移除元素(删)
LinkedList 提供多种删除方式:
| 方法 | 说明 |
|---|---|
remove() |
删除并返回头节点元素 |
remove(int index) |
删除指定索引元素 |
remove(Object o) |
删除首次匹配的元素 |
removeFirst() / pollFirst() |
删除头部节点 |
removeLast() / pollLast() |
删除尾部节点 |
3.1. unlink核心源码
unlink指的是断开节点连接,删除的本质是断开节点连接,使其前后节点重新连接,此时删除的节点在内存中就成了游离状态,后续会被GC清理回收。
E unlink(Node<E> x) {
final E element = x.item;
final Node<E> next = x.next;
final Node<E> prev = x.prev;
if (prev == null)
first = next;
else
prev.next = next;
if (next == null)
last = prev;
else
next.prev = prev;
x.item = null;
x.next = null;
x.prev = null;
size--;
modCount++;
return element;
}
调整前后节点指针,再断开目标节点;
GC 清理旧引用;
size--、modCount++。
3.2. 删除头部节点
删除头部节点并返回的源码:
// 删除并返回头部节点
public E remove() {
return removeFirst();
}
public E removeFirst() {
final Node<E> f = first;
if (f == null)
throw new NoSuchElementException();
return unlinkFirst(f);
}
删除过程效果图:

3.3. 删除尾部节点
删除尾部节点并返回的源码:
public E removeLast() {
final Node<E> l = last;
if (l == null)
throw new NoSuchElementException();
return unlinkLast(l);
}
删除过程效果图:
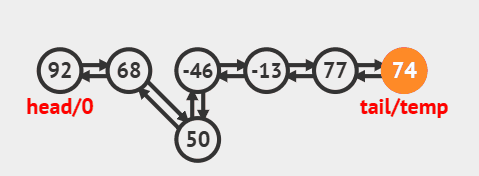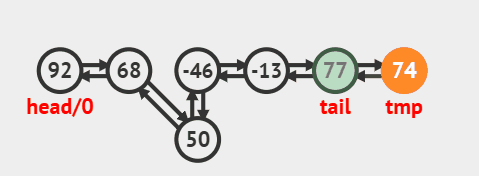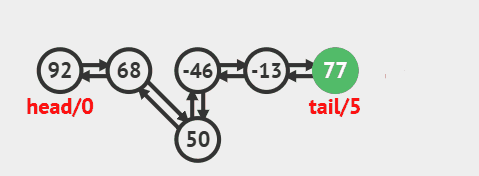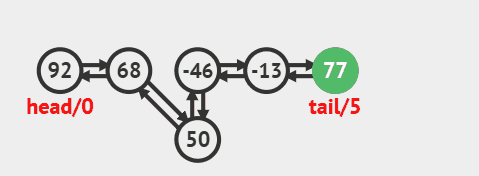
3.4. 删除指定索引节点
删除指定索引节点并返回的源码:
public E remove(int index) {
checkElementIndex(index);
return unlink(node(index));
}
删除过程效果图:

4. 修改元素(改)
set(int index, E element):找到指定索引节点后直接覆盖
public E set(int index, E element) {
checkElementIndex(index);
Node<E> x = node(index);
E oldVal = x.item;
x.item = element;
return oldVal;
}
检索算法还是node(index),找到节点后直接修改节点内容的指向。
效果如图:将索引为2的-46改为88

如果在-46元素后面还多一个元素呢?效果如下:

5. 获取和检索元素(查)
5.1. 获取元素
public E get(int index) {
checkElementIndex(index);
return node(index).item;
}
通过 node(index) 遍历链表查找节点,复杂度 O(n)。
5.2. 检索元素
contains(Object o)/indexOf/lastIndexOf:同ArrayList,但比较的是链表节点的item,需线性遍历,时间复杂度O(n);
6. LinkedList 的迭代器
LinkedList 实现了 双向迭代:
Iterator<E> iterator()返回基于头到尾的迭代器;ListIterator<E> listIterator()支持从任意位置开始双向遍历。
核心与 ArrayList 类似,使用 modCount 检测并发修改,next()/previous() 拿到节点后返回 item。
7. 并发安全问题
LinkedList 同样线程不安全;
多线程操作同一实例时需自行同步:
Collections.synchronizedList(new LinkedList<>())使用
CopyOnWriteArrayList不适用于链表,可改用ConcurrentLinkedDeque作为替代;
8. 时间复杂度汇总
| 操作 | 时间复杂度 | 备注 |
|---|---|---|
| 头/尾插入 | O(1) | linkFirst / linkLast |
| 中间插入 | O(n) | 查找节点 O(n) + 插入 O(1) |
| 头/尾删除 | O(1) | unlinkFirst / unlinkLast |
| 中间删除 | O(n) | 查找节点 O(n) + 删除 O(1) |
| 修改元素 | O(n) | 查找节点 O(n) |
| 获取元素 | O(n) | 查找节点 O(n) |
| 检索/contains/indexOf | O(n) | 遍历比较 |
| 迭代 | O(n) | 每次 next O(1) 总 O(n) |
9. 总结
LinkedList 适合频繁插入/删除的场景,尤其是在头尾操作;不适合随机访问,大规模 get/set 性能较差;在并发场景下需要显式同步或选用合适的并发链表实现;
根据场景选择:
读多写少、随机访问 用
ArrayList;插入/删除频繁、双端操作 用
LinkedList。

查看往期设计模式文章的:设计模式
觉得还不错的,三连支持:点赞、分享、推荐↓
Java集合--LinkedList源码可视化的更多相关文章
- Java集合---LinkedList源码解析
一.源码解析1. LinkedList类定义2.LinkedList数据结构原理3.私有属性4.构造方法5.元素添加add()及原理6.删除数据remove()7.数据获取get()8.数据复制clo ...
- Java集合——LinkedList源码详解
)LinkedList直接继承于AbstractSequentialList,同时实现了List接口,也实现了Deque接口. AbstractSequentialList为顺序访问的数据存储结构提供 ...
- Java集合-LinkedList源码分析
目录 1.数据结构-链表 2.ArrayList结构特性 3.构造方法 4.成员变量 5.常用的成员方法 6.Node节点 7.序列化原理 8.迭代器 9.总结 1.数据结构-链表 链表(Linked ...
- 【java集合框架源码剖析系列】java源码剖析之LinkedList
注:博主java集合框架源码剖析系列的源码全部基于JDK1.8.0版本. 在实际项目中LinkedList也是使用频率非常高的一种集合,本博客将从源码角度带领大家学习关于LinkedList的知识. ...
- 【java集合框架源码剖析系列】java源码剖析之ArrayList
注:博主java集合框架源码剖析系列的源码全部基于JDK1.8.0版本. 本博客将从源码角度带领大家学习关于ArrayList的知识. 一ArrayList类的定义: public class Arr ...
- 自己根据java的LinkedList源码编写的一个简单的LinkedList实现
自己实现了一个简单的LinkedList /** * Create by andy on 2018-07-03 11:44 * 根据 {@link java.util.LinkedList}源码 写了 ...
- 【java集合框架源码剖析系列】java源码剖析之TreeSet
本博客将从源码的角度带领大家学习TreeSet相关的知识. 一TreeSet类的定义: public class TreeSet<E> extends AbstractSet<E&g ...
- 【java集合框架源码剖析系列】java源码剖析之HashSet
注:博主java集合框架源码剖析系列的源码全部基于JDK1.8.0版本.本博客将从源码角度带领大家学习关于HashSet的知识. 一HashSet的定义: public class HashSet&l ...
- 【java集合框架源码剖析系列】java源码剖析之TreeMap
注:博主java集合框架源码剖析系列的源码全部基于JDK1.8.0版本.本博客将从源码角度带领大家学习关于TreeMap的知识. 一TreeMap的定义: public class TreeMap&l ...
- 【java集合框架源码剖析系列】java源码剖析之HashMap
前言:之所以打算写java集合框架源码剖析系列博客是因为自己反思了一下阿里内推一面的失败(估计没过,因为写此博客已距阿里巴巴一面一个星期),当时面试完之后感觉自己回答的挺好的,而且据面试官最后说的这几 ...
随机推荐
- MAMP使用简单教程
这个配置,没有域名访问,平时可以放些demo使用,如果需要域名访问请看MAMP PRO教程 启用服务 打开Launchpad中灰色的MAMP,进入界面后,点击Preferences,然后只需拿着鼠标点 ...
- Delphi 禁止重复运行程序的方法
第一种方法,使用"过程调用" procedure Del; // 自定义过程 var Mutex: THandle; begin Mutex := CreateMutex(nil, ...
- [每日算法 - 华为机试] leetcode463. 岛屿的周长
入口 力扣(LeetCode)官网 - 全球极客挚爱的技术成长平台备战技术面试?力扣提供海量技术面试资源,帮助你高效提升编程技能,轻松拿下世界 IT 名企 Dream Offer.https://le ...
- Sublime Text 3汉化教程
一.初始化插件仓库 ctrl+`(esc键下方那一个)打开控制台输入以下代码回车 import urllib.request,os,hashlib; h = '6f4c264a24d933ce70df ...
- 如何开发 MCP 服务?保姆级教程!
最近这段时间有个 AI 相关的概念特别火,叫 MCP,全称模型上下文协议(Model Context Protocol).这是由 Anthropic 推出的一项开放标准,目标是为大型语言模型和 AI ...
- 修显示器led屏幕能亮但是显示异常
用电吹风热风大风 对着显示器的 ' led 区域 ' 吹十分钟 吹显示器线插口 电源线 插口 机箱 断电吹 // 温度挺高 还得吹显卡接口 线也要换新的 插口需要用线的接口 打磨金属 ...
- 想构建一个Web学习数据库管理系统
有过爬虫的学习基础,凭借兴趣学习到 视频爬取和反向解析那里(没学完). 以及最新出来的技术 分布式多线程.selenium.scrpy 等技术 3 3 防盗链 抓取梨视频(1)_哔哩哔哩_bil ...
- eolinker请求预处理:请求数据中有中文,提示参数错误的解决方法
特别注意:需要使用全局变量或者预处理前务必阅读本链接https://www.cnblogs.com/becks/p/13713278.html 如下图,请求参pageName参数为中文,提交后报错 需 ...
- 1678. 设计 Goal 解析器
1678. 设计 Goal 解析器 class Solution { public String interpret(String command) { char[] ch = command.toC ...
- 【工具】Vscode翻译插件推荐(不用谷歌翻译api、支持短句英汉互译、支持查词、支持自动补全、不需要浏览器)
2024/04/24说明:这篇暂时修改为粉丝可见,因为正在冲粉丝量,等到我弄完了粉丝量的要求,我就改回来!不方便看到全文的小伙伴不好意思!! 需求: 1)偶尔需要查英文生词: 2)有时候想不起来中文对 ...