十年大厂员工终明白:MySQL性能优化的尽头,是对B+树的极致理解
存储引擎
存储引擎是数据库管理系统(DBMS)或键值存储系统的核心组件,它定义了数据在持久化存储介质上如何组织、存储、检索和管理。不同的存储引擎针对特定负载(如读密集型、写密集型、混合型)和数据模型(如关系型、键值型、文档型)进行优化。
目前常见的存储引擎使用的存储数据结构有如下几种。
1)哈希表(Hash Table):提供O(1)平均时间复杂度的单点查询(精确键匹配)。非常适合键值(Key-Value)存储,但天然不支持范围查询或有序遍历(除非对整个数据集扫描)。
2)B+树(Balance+ Tree):为磁盘I/O优化的多路平衡搜索树。广泛用于关系型数据库(如MySQL InnoDB, PostgreSQL)的索引和数据存储。支持高效的单点查询、范围查询和有序遍历。对读密集型和混合型负载友好。
3)LSM树(Log-Structured Merge Tree):专为高写入吞吐量设计的结构。通过将随机写转换为内存中的有序写入和磁盘上的顺序批量写入来优化写性能。广泛应用于写密集型的NoSQL数据库(如Google Bigtable, Apache HBase, Cassandra, RocksDB, LevelDB)。
MySQL B+树
MySQL的存储引擎,主要分InnoDB和MyISAM。InnoDB是MySQL的默认引擎,InnoDB使用B+树存储数据。表中的数据(主键索引)和辅助索引最终都会使用 B+ 树来存储,其中前者会以 <id, row> 的方式存储,而后者会以 <index, id> 的方式进行存储。

为了分析 InnoDB 选择 B+ 树作为其索引结构的原因,可以将其与 B 树和哈希表进行对比。随着互联网的快速发展,数据存储规模已攀升至千万甚至亿级,而典型的互联网应用场景往往是读多写少。例如,热点新闻的访问、商品列表的展示以及基于价格、地理位置等条件的智能化推荐排序,都需要高效的数据查询和排序能力。因此,数据存储结构需要满足以下核心需求。
1)高效的查询性能:尤其是在范围查询和排序操作上,需要具备优异的性能表现。
2)充分利用顺序 I/O 和 Page Cache 机制:通过优化 I/O 性能,减少磁盘访问的延迟。
3)支持大规模数据存储:在保证高效查询的同时,尽可能减少写入操作的 I/O 开销。

由于哈希映射关系,哈希表在查找单条数据时候,能保证O(1)的时间复杂读。但哈希表在范围查询和排序遍历时候,只能进行全表扫描并依次判断是否满足条件。全表扫描对数据库的性能影响非常大。比如如下的SQL语句:
SELECT * FROM commodity WHERE price > 10 AND price < 100
SELECT * FROM commodity WHERE ORDER BY price DESC
平均时间复杂度比O(1)稍慢的是O(logn),这类数据结构有平衡二叉树(AVL Tree),红黑树(RB Tree)、B树(B Tree)、B+树(B+ Tree)等。他们天然就支持排序、范围查找操作。
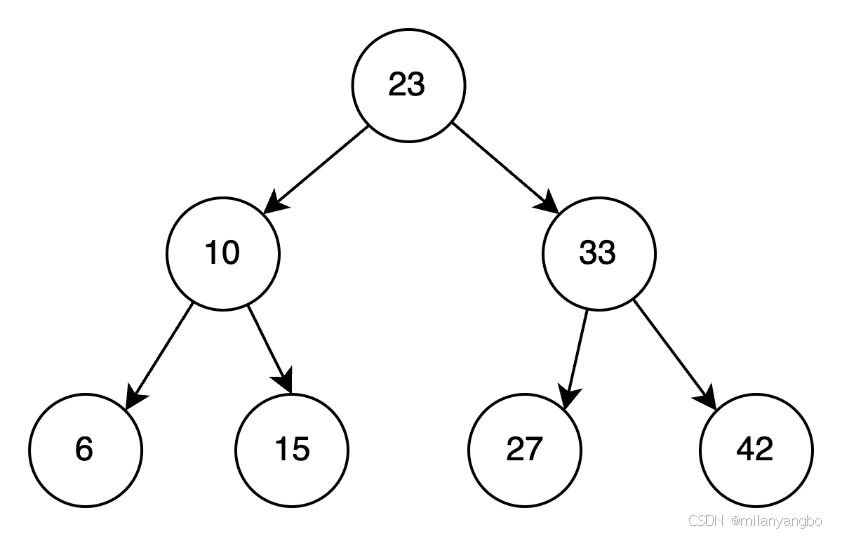
平衡二叉树在一般情况下查询性能非常好,但平衡二叉树单个节点只能保存一个数据,因此当覆盖大量数据时候,平衡二叉树的树高度很高。这意味着当需要通过遍历获取存储在硬盘上的数据时候,需要更多次的I/O操作。硬盘读取时间远远超过数据在内存中比较的时间,这将导致程序大部分时间会阻塞在硬盘 I/O 上。
B树
跟平衡二叉树的不同是,B树是一种多叉树。阶数m决定了B树的节点大小和树的高度。较大的阶数可以容纳更多的键值对,减少树的高度和硬盘访问次数。
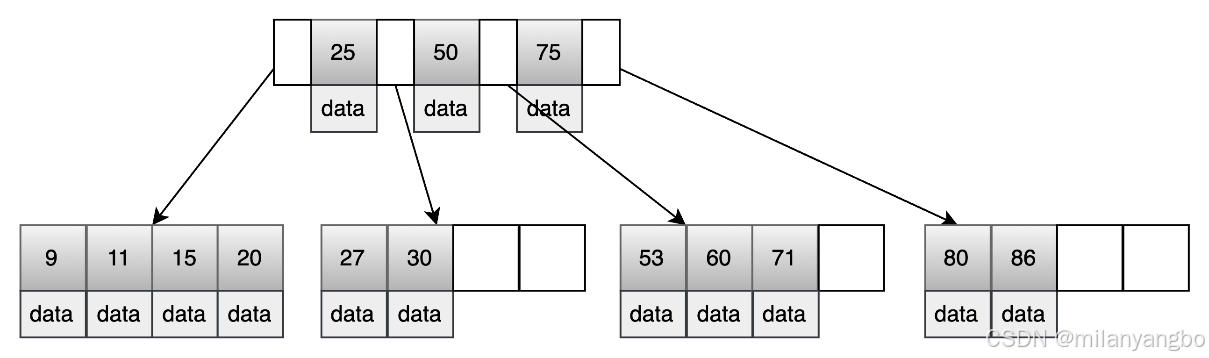
B树中每个节点都存放着索引和数据,从下图可见,查询索引为 50 的节点就在第一层,B树只需一次硬盘 I/O 即可完成查找。因此B树的查询最好时间复杂度是 O(1)。
B+树
B+树是B树的一种变种,它与B树的区别是:
叶子节点保存了完整的索引和数据,而非叶子节点只保存索引值。所以查询索引为 50的数据,必须要遍历到叶子节点才能取到,因此查询时间固定为 O(logn)。
常见的B+树阶数可以是100或更大,以适应硬盘上的大量数据。

数据查询
B树的范围查询,比如上图要查询“大于10小于30的数据”,需要进行4次硬盘的随机 I/O 。范围查询的随机 I/O次数不稳定和放大,也是 B 树最大的性能问题:
1)遍历根节点的第一个元素是25,大于 10。
2)遍历左子节点的元素,找到第一个大于10的数据是11。
3)重新遍历根节点,发现不包含小于30的数据。
4)遍历载右子节点的元素,找到最后一个小于30的数据是27。
而B+树叶子节点保存指向下一个叶子节点的指针,叶子节点之间类似于单链表连接起来,因此叶子节点的数据在硬盘里是顺序存储的。当读到某个叶子节点数据时候,硬盘根据局部性原理会提前将相关的数据都读进内存,这使得范围查询和排序很高效。
操作系统在读文件时,根据Page Cache机制将数据加载到页缓存中,页的默认大小是4KB。由于B+树非叶子节点都只是索引值,这就意味B+树一次I/O,相比于B树能读出的索引值更多,从而减少查询时候需要的I/O次数。
不同于操作系统,InnoDB引擎的页大小默认是16KB,如下估算:
1)非叶子节点存放(key,pointer),假设主键ID为bigint类型,长度为8字节,而指针在InnoDB源码中为6字节,一共14字节,即非叶子节点能存放 16KB/14 左右的(key,pointer)。
2)叶子节点中保存的一行记录的数据大小为1KB,大约可以存储16K/1K = 16记录数。
如果B+树高度为2,那么存放总记录数为:根节点指针数单个叶子节点记录行数 = 16KB/14 * 16 大约 1.8w+ 数据。
如果B+树高度为3,那么存放总记录数为:根节点指针数单个叶子节点记录行数 = 16KB/14 * 16KB/14 * 16 大约2kw+数据。
数据写入
相比于数据读取场景,B+树在写密集型场景的性能并不理想。这主要原因是:B+树在写入(插入、删除、更新)时,为维持树的平衡,可能触发节点分裂、合并。这些操作可能涉及多个磁盘页的修改,导致随机I/O,且需要更新Page Cache中的对应页,使其失效。因此,在写密集型场景下,B+树性能不如专为写入优化的结构。

因此B+树也通过一些优化策略来提高写操作的性能。比如使用写缓冲区(Write Buffer)来缓存写操作,然后定期将缓冲区中的数据批量刷入硬盘,将随机I/O合并为后续的顺序I/O。此外可以使用多版本并发控制机制(MVCC)来减少写入时候的锁竞争和提高并发性能。
未完待续
很高兴与你相遇!如果你喜欢本文内容,记得关注哦!!!
十年大厂员工终明白:MySQL性能优化的尽头,是对B+树的极致理解的更多相关文章
- Java面试准备十六:数据库——MySQL性能优化
2017年04月20日 13:09:43 阅读数:6837 这里只是为了记录,由于自身水平实在不怎么样,难免错误百出,有错的地方还望大家多多指出,谢谢. 来自MySQL性能优化的最佳20+经验 为查询 ...
- [MySQL性能优化系列]LIMIT语句优化
1. 背景 假设有如下SQL语句: SELECT * FROM table1 LIMIT offset, rows 这是一条典型的LIMIT语句,常见的使用场景是,某些查询返回的内容特别多,而客户端处 ...
- mysql 性能优化方案
网 上有不少MySQL 性能优化方案,不过,mysql的优化同sql server相比,更为麻烦与复杂,同样的设置,在不同的环境下 ,由于内存,访问量,读写频率,数据差异等等情况,可能会出现不同的结果 ...
- mysql 性能优化方案1
网 上有不少mysql 性能优化方案,不过,mysql的优化同sql server相比,更为麻烦与复杂,同样的设置,在不同的环境下 ,由于内存,访问量,读写频率,数据差异等等情况,可能会出现不同的结果 ...
- mysql 性能优化方案 (转)
网 上有不少mysql 性能优化方案,不过,mysql的优化同sql server相比,更为麻烦与复杂,同样的设置,在不同的环境下 ,由于内存,访问量,读写频率,数据差异等等情况,可能会出现不同的结果 ...
- MySQL 性能优化
内容简介:这是一篇关于mysql 性能,mysql性能优化,mysql 性能优化的文章.网上有不少mysql 性能优化方案,不过,mysql的优化同sql server相比,更为麻烦与负责,同样的设置 ...
- 涨姿势:Mysql 性能优化完全手册
涨姿势:Mysql 性能优化完全手册 深入理解MySQL服务器架构 客户端层 MySQL逻辑架构整体分为三层,最上层为客户端层,诸如:连接处理.授权认证.安全等功能均在这一层处理. 中间层 MySQL ...
- Mysql 性能优化教程
Mysql 性能优化教程 目录 目录 1 背景及目标 2 Mysql 执行优化 2 认识数据索引 2 为什么使用数据索引能提高效率 2 如何理解数据索引的结构 2 优化实战范例 3 认识影响结果集 4 ...
- 转 Mysql性能优化教程
Mysql性能优化教程 背景及目标 厦门游家公司(4399.com)用于员工培训和分享. 针对用户群为已经使用过mysql环境,并有一定开发经验的工程师 针对高并发,海量数据的互联网环境. 本文语言为 ...
- MySQL 性能优化系列之一 单表预处理
MySQL 性能优化系列之一 单表预处理 背景介绍 我们经常在写多表关联的SQL时,会想到 left jion(左关联),right jion(右关联),inner jion(内关联)等. 但是,当表 ...
随机推荐
- Ubuntu 通过 docker 部署禅道
# 拉取镜像 docker pull easysoft/zentao:latest # 运行容器(简单配置) docker run --name zentao -p 8080:80 -e MYSQL_ ...
- VS下进行CUDA编译时error MSB3721相关的原因之一
报错:"1>D:\Microsoft Visual Studio\2019\Community\MSBuild\Microsoft\VC\v160\BuildCustomization ...
- 使用Oracle数据库的递归查询语句生成菜单树
SQL 格式 SELECT * FROM TABLE WHERE [...结果过滤语句] START WITH [...递归开始条件] CONNECT BY PRIOR [...递归执行条件] 查询所 ...
- 国贸股份 x 袋鼠云:推进全链业务深度数字化,为产业综合服务插上数字化翅膀
数据治理是推动大型集团企业转型升级.提升竞争优势.实现高质量发展的重要引擎.通过全链数据结构化,实现业务对象.业务规则.业务流程数字化,推进全链业务深度数字化,夯实数据运营底座. 厦门国贸集团股份有限 ...
- hot100之栈
有效的括号(020) 跳过 最小栈(155) class MinStack { private final Deque<int[]> stack = new ArrayDeque<& ...
- 总结下参与以及看到的一些好的业务设计的 pattern
B端C端进行分离: 单场景业务应用表:业务表进行分离 对于B端系统来说,如发钱系统,B端需要存储 订单id.是否发放成功.通知状态等信息,有可能还会有发放失败,审核驳回等无用数据记录,但是对于C端用户 ...
- 利用DNSLOG测试Fastjson远程命令执行漏洞
由于内容比较简单,我直接贴图,怕我自己忘了. 测试Fastjson版本号:1.2.15 直接发送用burpsuite发送payload,将dataSourceName改成dnslog获取到的域名. p ...
- SpringMVC三层结构
Java SpringMVC的工程结构一般来说分为三层,自下而上是Modle层(模型,数据访问层).Cotroller层(控制,逻辑控制层).View层(视图,页面显示层),其中Modle层分为两层: ...
- 富文本里解析vue、react组件
react 封装的渲染富文本的组件: RenderRtf.tsx import { useState, useEffect, useRef } from "react"; impo ...
- vue开发组件并发包到npm
其实很早之前就做过,时间久了,就忘记了.这次复习,做个笔记官方文档:https://cli.vuejs.org/zh/guide/build-targets.html#%E5%BA%93 创建组件项目 ...