【SpringCloud构建微服务系列】分布式链路跟踪Spring Cloud Sleuth
一、背景
随着业务的发展,系统规模越来越大,各微服务直接的调用关系也变得越来越复杂。通常一个由客户端发起的请求在后端系统中会经过多个不同的微服务调用协同产生最后的请求结果,几乎每一个前端请求都会形成一条复杂的分布式服务调用链路,对每个请求实现全链路跟踪,可以帮助我们快速发现错误根源以及监控分析每条请求链路上性能瓶颈。
针对分布式服务跟踪,Spring Cloud Sleuth提供了一套完整的解决方案。
二、原理
参考《SpringCloud微服务实战》第11章。
先查看跟踪日志了解每项的含义
2019-02-27 20:40:56.419 INFO [service-a,e79b41414a56743d,e79b41414a56743d,true] 8276 --- [nio-9001-exec-5] cn.sp.controller.ServiceController : ==<Call Service-a>==
- 第一个值service-a:记录了应用的名称,也就是spring.application.name的值。
- 第二个值e79b41414a56743d:SpringCloudSleuth生成的一个ID,叫TraceID,它用来标识一条请求链路。一条请求链路中包含一个TraceID,多个 SpanID。
- 第三个值e79b41414a56743d,SpringCloudSleuth生成的另外一个ID,叫SpanID,它表示一个基本的工作单元,比如发送一个HTTP请求。
- 第四个值true:表示是否要将该信息输出到Zipkin等服务中收集和展示。
三、编码
3.1创建一个Eureka注册中心
这个之前的文章有,故省略
3.2调用者service-a
1.创建项目引入依赖
- <dependency>
- <groupId>org.springframework.boot</groupId>
- <artifactId>spring-boot-starter-web</artifactId>
- </dependency>
- <dependency>
- <groupId>org.springframework.cloud</groupId>
- <artifactId>spring-cloud-starter-netflix-eureka-client</artifactId>
- </dependency>
- <dependency>
- <groupId>org.springframework.cloud</groupId>
- <artifactId>spring-cloud-starter-sleuth</artifactId>
- </dependency>
- <dependency>
- <groupId>org.springframework.cloud</groupId>
- <artifactId>spring-cloud-starter-zipkin</artifactId>
- </dependency>
其实spring-cloud-starter-zipkin中已经有了sleuth的依赖,spring-cloud-starter-sleuth可以省略。
2. 启动类
@EnableEurekaClient
@SpringBootApplication
public class ServiceAApplication {
public static void main(String[] args) {
SpringApplication.run(ServiceAApplication.class, args);
}
@Bean
@LoadBalanced
RestTemplate restTemplate(){
return new RestTemplate();
}
}
- ServiceController
@RestController
public class ServiceController {
private final Logger logger = LoggerFactory.getLogger(this.getClass());
@Autowired
private RestTemplate restTemplate;
@GetMapping("/service-a")
public String test(){
logger.info("==<Call Service-a>==");
return restTemplate.getForEntity("http://service-b/test",String.class).getBody();
}
}
这里的url(http://service-b/test)用的是服务名当虚拟域名而不是ip+端口号的形式,至于为什么可以访问可以查看这篇文章【Spring Cloud中restTemplate是如何通过服务名主求到具体服务的】。
4.配置文件application.yml
- spring:
- application:
- name: service-a
- zipkin:
- base-url: http://localhost:9411
- # 抽样收集的百分比,默认10%
- sleuth:
- sampler:
- probability: 1
- eureka:
- client:
- serviceUrl:
- defaultZone: http://localhost:8761/eureka/
- server:
- port: 9001
3.3被调用者service-b
1.创建项目引入依赖pom文件同上
2.启动类添加注解 @EnableEurekaClient
3.ServiceController
@RestController
public class ServiceController {
private final Logger logger = LoggerFactory.getLogger(this.getClass());
@GetMapping("/test")
public String test(){
logger.info("==<Call Service-b>==");
return "OK";
}
}
4.配置文件application.yml
- spring:
- application:
- name: service-b
- zipkin:
- base-url: http://localhost:9411
- # 抽样收集的百分比,默认10%
- sleuth:
- sampler:
- probability: 1
- eureka:
- client:
- serviceUrl:
- defaultZone: http://localhost:8761/eureka/
- server:
- port: 9002
3.4创建zipkin-server
- pom.xml
- <dependency>
- <groupId>io.zipkin.java</groupId>
- <artifactId>zipkin-server</artifactId>
- <version>2.12.2</version>
- <exclusions>
- <exclusion>
- <groupId>org.springframework.boot</groupId>
- <artifactId>spring-boot-starter-log4j2</artifactId>
- </exclusion>
- </exclusions>
- </dependency>
- <!-- https://mvnrepository.com/artifact/io.zipkin.java/zipkin-autoconfigure-ui -->
- <dependency>
- <groupId>io.zipkin.java</groupId>
- <artifactId>zipkin-autoconfigure-ui</artifactId>
- <version>2.12.2</version>
- </dependency>
2.启动类添加注解 @EnableZipkinServer
注意: 这里我排除了log4j的依赖,因为已经有了相同的类文件启动会报错。
四、测试
- 依次启动eureka注册中,service-a,service-b,zipkin-server
- 访问http://localhost:8761/看到有两个注册实例,说明启动成功。

- 游览器访问http://localhost:9001/service-a请求服务A
如果报错日志打印java.lang.IllegalStateException: No instances available for service-b,那可能是服务B还没注册完成等会儿再试下即可。 - 正常情况会看到游览器显示 OK
服务A的日志如下:

2019-02-27 21:18:05.119 INFO [service-a,3e487761c9b13a2e,3e487761c9b13a2e,true] 8276 --- [nio-9001-exec-9] cn.sp.controller.ServiceController : ==<Call Service-a>==
服务B的日志如下:
2019-02-27 21:18:05.128 INFO [service-b,3e487761c9b13a2e,8d49352c6645c6f9,true] 13860 --- [nio-9002-exec-8] cn.sp.controller.ServiceController : ==<Call Service-b>==
- 访问http://localhost:9411/zipkin/进入可视化界面
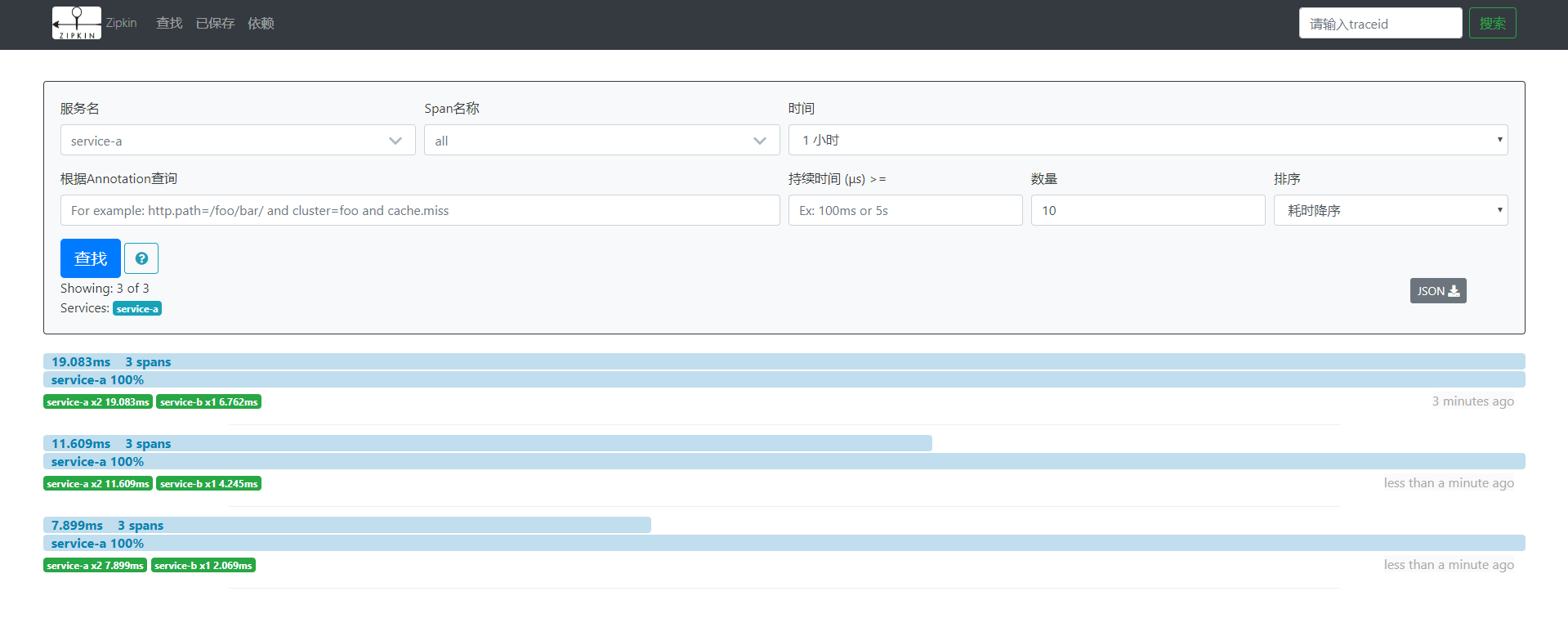

点击查找,服务名选择service-a即可看到最近的统计数据,还可以根据条件进行筛选。
点击依赖,依赖分析就可以看到服务之前的依赖关系。

完整代码地址。
五、总结
基本是根据《SpringCloud微服务实战》这本书来的,但是中间还是踩了几个坑,比如开始报No instances available for service-b的时候我一直以为是代码哪里出了问题,浪费了很多时间。
SpringCloudSleuth除了把请求链路数据整合到Zipkin中外,还可以保存到消息队列,ELK等,还算比较强大。但是除了HTTP请求,不知道对于GRPC这样的通信方式是否也能实现链路跟踪。
查了下资料支持Grpc的,demo地址:https://github.com/tkvangorder/sleuth-grpc-sample
官方文档:https://cloud.spring.io/spring-cloud-sleuth/single/spring-cloud-sleuth.html#_grpc
【SpringCloud构建微服务系列】分布式链路跟踪Spring Cloud Sleuth的更多相关文章
- Spring cloud系列十四 分布式链路监控Spring Cloud Sleuth
1. 概述 Spring Cloud Sleuth实现对Spring cloud 分布式链路监控 本文介绍了和Sleuth相关的内容,主要内容如下: Spring Cloud Sleuth中的重要术语 ...
- 【SpringCloud构建微服务系列】微服务网关Zuul
一.为什么要用微服务网关 在微服务架构中,一般不同的微服务有不同的网络地址,而外部客户端(如手机APP)可能需要调用多个接口才能完成一次业务需求.例如一个电影购票的手机APP,可能会调用多个微服务的接 ...
- 【SpringCloud构建微服务系列】Feign的使用详解
一.简介 在微服务中,服务消费者需要请求服务生产者的接口进行消费,可以使用SpringBoot自带的RestTemplate或者HttpClient实现,但是都过于麻烦. 这时,就可以使用Feign了 ...
- 【SpringCloud构建微服务系列】使用Spring Cloud Config统一管理服务配置
一.为什么要统一管理微服务配置 对于传统的单体应用而言,常使用配置文件来管理所有配置,比如SpringBoot的application.yml文件,但是在微服务架构中全部手动修改的话很麻烦而且不易维护 ...
- 【SpringCloud构建微服务系列】学习断路器Hystrix
一.Hystrix简介 在微服务架构中经常包括多个服务层,比如A为B提供服务,B为C和D提供服务,如果A出故障了就会导致B也不可用,最终导致C和D也不可用,这就形成了雪崩效应. 所以为了应对这种情况, ...
- SpringCloud(7)服务链路追踪Spring Cloud Sleuth
1.简介 Spring Cloud Sleuth 主要功能就是在分布式系统中提供追踪解决方案,并且兼容支持了 zipkin,你只需要在pom文件中引入相应的依赖即可.本文主要讲述服务追踪组件zipki ...
- 史上最简单的SpringCloud教程 | 第九篇: 服务链路追踪(Spring Cloud Sleuth)(Finchley版本)
转载请标明出处: 原文首发于:>https://www.fangzhipeng.com/springcloud/2018/08/30/sc-f9-sleuth/ 本文出自方志朋的博客 这篇文章主 ...
- 史上最简单的SpringCloud教程 | 第九篇: 服务链路追踪(Spring Cloud Sleuth)
这篇文章主要讲述服务追踪组件zipkin,Spring Cloud Sleuth集成了zipkin组件. 注意情况: 该案例使用的spring-boot版本1.5.x,没使用2.0.x, 另外本文图3 ...
- SpringCloud教程 | 第九篇: 服务链路追踪(Spring Cloud Sleuth)
版权声明:本文为博主原创文章,欢迎转载,转载请注明作者.原文超链接 ,博主地址:http://blog.csdn.net/forezp. http://blog.csdn.net/forezp/art ...
随机推荐
- 代码空间项目 -- InstantiationException的异常
java.lang.InstantiationException实例化异常.当试图通过newInstance()方法创建某个类的实例,而该类是一个抽象类或接口时,抛出该异常. 这次项目中查询type时 ...
- wifi方式调试android程序
1. 通过wifi, 利用adb来连接手机. 在pc的cmd中输入命令: adb connect 192.168.1.100 其中adb就是手机的ip. 如果连接成功, 就可以进入android的sh ...
- Codeforces Round #261 (Div. 2) B. Pashmak and Flowers 水题
题目链接:http://codeforces.com/problemset/problem/459/B 题意: 给出n支花,每支花都有一个漂亮值.挑选最大和最小漂亮值得两支花,问他们的差值为多少,并且 ...
- js里=、== 和===有什么区别?
说明:该文章是转载后进行修改完善的,望大家有收获. =是赋值运算符,==是关系运算符; ===是全等运算符. ”==”与”===”是不同的,一个是判断值是否相等,一个是判断值及类型是否完全相等.第一个 ...
- void类型和void *指针类型(网上摘抄总结)【转】
http://www.blogjava.net/fhtdy2004/archive/2009/07/09/286004.html 现在在学linux编程过程中遇到很多void *指针类型,由于c很早学 ...
- 树堆(Treap)
平衡树 简介: 平衡二叉树(Balanced Binary Tree)具有以下性质:它是一 棵空树或它的左右两个子树的高度差的绝对值不超过1,并且左右两个子树都是一棵平衡二叉树.平衡二叉树的常用实现方 ...
- windows下使用emacs+plink远程编辑erlang文件
1)plink.exe属于putty套件, 注册到环境变量;emacs的bin目录也要注册到环境变量中; 2)在.emacs中增加如下: (require 'tramp)(setq tramp-def ...
- vue-router 获得上一级路由以及返回上一级路由的方法
if (this.$store.state.previousRouter.name) { this.$router.push({name: this.$store.state.previousRout ...
- AtCoder Grand Contest 012 D:Colorful Balls
题目传送门:https://agc012.contest.atcoder.jp/tasks/agc012_d 题目翻译 给你一排一共\(N\)个球,每个球有一个颜色\(c_i\)和一个重量\(w_i\ ...
- poj2226Muddy Fields——二分图匹配
题目:http://poj.org/problem?id=2226 把行连通块作为左部点,列连通块作为右部点,行列连通块有相交的格子就连边: 则问题转化为求最小点覆盖,即最大匹配. 代码如下: #in ...