(31)zabbix Aggregate checks聚合检测
概述
aggregate checks是一个聚合的检测,例如我想知道某个组的host负载平均值,硬盘剩余总量,或者某几台机器的这些数据,简单的说,这个方法就是用来了解一个整体水平,而不需要我们一台台看过去。这个方法的数据全部来之数据库,所以它不需要agent。文章的最后面我们会有一个简单的图例讲述aggregate checks.
aggregate item key语法如下:
|
1
|
groupfunc["Host group","Item key",itemfunc,timeperiod]
|
多个组使用逗号分隔.
支持按组的function
GROUP FUNCTION 描述
| grpavg | 平均值 |
| grpmax | 最大值 |
| grpmin | 最小值 |
| grpsum | 总和 |
支持按tiem的function
| ITEM FUNCTION | 描述 |
| avg | 平均值 |
| count | value个数 |
| last | 最新值 |
| max | 最大值 |
| min | 最小值 |
| sum | 总值 |
参数timeperiod为指定的采集时间,可以使用时间单位,例如可以使用1d代替86400(单位默认为秒),5m代替300.
备注:
- 如果第三个参数为last,那么timeperiod参数值将会被server忽略掉
- 只有被监控的HOST上启用的item才会被计入aggregate check
使用范例
示例1
组MySQL Servers剩余硬盘空间大小
|
1
|
grpsum["MySQL Servers","vfs.fs.size[/,total]",last,0]
|
示例2
组MySQL Servers的平均CPU负载
|
1
|
grpavg["MySQL Servers","system.cpu.load[,avg1]",last,0]
|
示例3
组MySQL Servers 5分钟内的平均查询速度(次/秒)
|
1
|
grpavg["MySQL Servers",mysql.qps,avg,5m]
|
示例4
多个组的cpu负载平均值
|
1
|
grpavg[["Servers A","Servers B","Servers C"],system.cpu.load,last,0]
|
示例(带图)
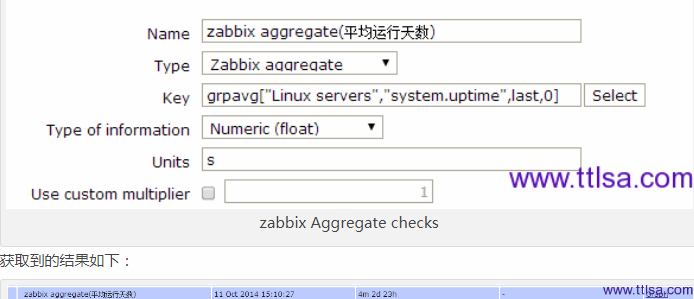
获取linux servers组内所有HOST平均运行天数
首先在zabbix server上配置item,名字就叫做:zabbix aggregate(平均运行天数),key为:grpavg["Linux servers","system.uptime",last,0]
具体请看图:
(31)zabbix Aggregate checks聚合检测的更多相关文章
- (14)zabbix Simple checks基本检测
1. 开始 Simple checks通常用来检查远程未安装代理或者客户端的服务 使用simple checks,被监控客户端无需安装zabbix agent客户端,zabbix server直接使用 ...
- (13)zabbix External checks 外部命令检测
1. 概述 zabbix server运行脚本或者二进制文件来执行外部检测,外部检测不需要在被监控端运行任何agentd item key语法如下: ARGUMENT DEFINITION scri ...
- (77)zabbix主动、被动检测的详细过程与区别
zabbix agent检测分为主动(agent active)和被动(agent)两种形式,主动与被动的说法均是相对于agent来讨论的.简单说明一下主动与被动的区别如下: 主动:agent请求se ...
- zabbix--Simple checks 基本检测
开始 Simple checks 通常用来检查远程未安装代理或者客户端的服务. 使用 simple checks,被监控客户端无需安装 zabbixagent 客户端, zabbix ser ...
- storm sum aggregate 原语 聚合 本地测试
编写storm程序,对数据进行聚合并且写入到mysql, 本文 主要说明数据中有多个字段需要进行sum或其他操作时的程序写法 1.主程序main方法,storm 拓扑运行入口 public clas ...
- zabbix 批量生成聚合图形
通过插入数据库的方式批量生成 zabbix 聚合图形 原型图形 聚合的 sql 批量操作 .在聚合图形创建好一个聚合图形A.找出图形A的ID (创建图形的时候记得填写好行数和列数) select sc ...
- zabbix 批量添加聚合图形
环境为centos 脚本要在centos zabbix服务器上运行,zabbix server上运行 1.先把脚本部署到zabbix客户端,把脚本保存为nic.sh 存放路径确保zabbix可以访问 ...
- HANA aggregate 数字聚合
在project 1 里面 具有服务店代码,金额.应该上一层aggregate 就自动聚合了.可是并没有.要自己手工设置一下.在columns 右键变成——convert to aggregated ...
- Aggregate report 聚合报告
随机推荐
- idea svn 问题
https://blog.csdn.net/liyantianmin/article/details/52837506
- nacos启动
nacos下载 https://github.com/alibaba/nacos 1.执行数据库脚本 2.修改配置文件application.propertiesspring.datasource.p ...
- MODBUS移植的参考文章
https://github.com/armink/FreeModbus_Slave-Master-RTT-STM32 http://www.360doc.com/content/14/0906/09 ...
- vue2 mint-ui loadmore(下拉刷新,上拉更多)
<template> <div class="page-loadmore"> <h1 class="page-title"> ...
- MVC dropdownlist 后端设置select属性后前端依然不能默认选中的解决方法
-----------------------------------来自网上的解决方法--------------------------------------------- ASP.Net MV ...
- Java .class文件的反编译与反汇编
转载请注明原文地址:https://www.cnblogs.com/ygj0930/p/10840818.html 一:反编译 通常用于第三方JAR包的逆向工程. 一般我们拿到的jar包都是经过编译后 ...
- CommonJS与ES6、AMD、CMD比较
Javascript,javascript是一种脚本编程语言,有自己独立的语法与语义,没有javascript,也就没有其他的那些概念了. 关于ES6,可直接理解为javascript的增强版(增加了 ...
- 将生成的Excel表发送到邮箱
本文接上一篇,将得到的Excel表发送到邮箱.. 在上一篇中,本人使用的是直接从数据库中获取数据,然后包装成Excel表.现在将该Excel表发送到目的邮箱,如果需要跟上篇一样,定时每天某时刻发送,就 ...
- DVWA之Brute Force教程
---恢复内容开始--- Brute Force暴力破解模块,是指黑客密码字典,使用穷举的方法猜出用户的口令,是一种广泛的攻击手法. LOW low级别的漏洞利用过程 1.使用burp suite工具 ...
- Lucene全文检索技术学习
---------------------------------------------------------------------------------------------------- ...