grep的用法(CentOS7)及有关正则表达式的使用
环境准备:alias grep="grep --color"
1、grep以整行为单位进行处理,行中有的匹配显示出来
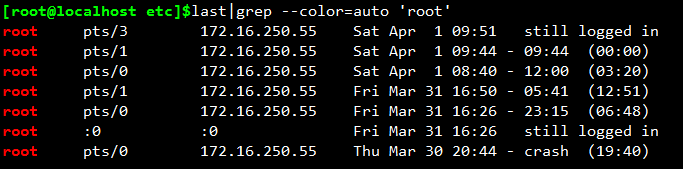
Last中取出符合root的行:grep '查找字符串'
last|grep 'root'
2、取出没有root的行:last|grep -vn 'root'
-v:反向选择,显示出没有'root'行的数据;
-n: 输出行号;

3、取出查找到的'eth0'行和此行的前两行与后两行:dmesg|grep -n -A 2 -B 2 'eth0'
-A:after,显示按要求查出的行以及后#行
-B:before,显示按要求查出的行以及前#行
-C: 除了显示所匹配的那一列之外,并显示该列之前后的内容
dmesg:显示内核信息。

那么,各取出查找行的前后各三行呢?可以用上面的-A -B,当然,也可以使用-C来表示。
查找出'eth0'的前后各三行:dmesg |grep -n -A 3 -B 3 'eth0'或者 dmesg|grep -n -C 3 'eth0'

4、[]的使用:[]里出现的字符被查找出来,[]里面可以有多个字符,但一个[]代表一个字符。
grep -n 't[ae]st' regular_express.txt

[A-Z]:表示A到Z大写的26个英文字母中的一个;也可用[:upper:];
[a-z]:表示a到z小写的26个英文字母中的一个;也可用[:lower:];
[0-9]:表示0到9的10个数字中的一个数字;也可用[:digit:];
[:alpha:]:表示大小写英文字母;
grep -n '[^g]oo' regular_express.txt

解释:'[^g]oo'查找oo前面没有g的字符串。第19行,也可以组成oo前面是oo,故而符合要求。
5、行首匹配用^,行尾匹配用$
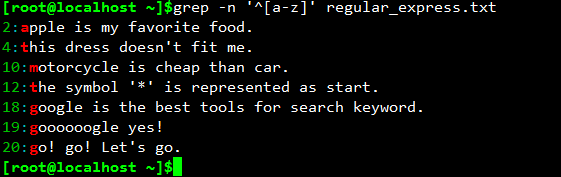
grep -n '^[a-z]' regular_express.txt
匹配出行首是小写字母的行。
区别:[^](^在[]里面)表示取补集,取返。
^[](^在[]外)表示在行首 。
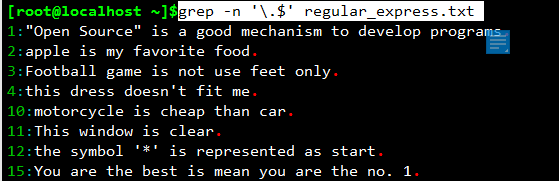
取出以.号结尾的行:grep -n '\.$' regular_express.txt
转义字符的详细情况,请自行查阅 。
6、整个单词的匹配:\bword\b或者\<word\>。其中,\b和\<表示词首锚定,\b和\>表示词尾锚定。
显示用户lp默认的shell程序:cat /etc/passwd | grep '\blp\b'

7、不区分大小写匹配查找:
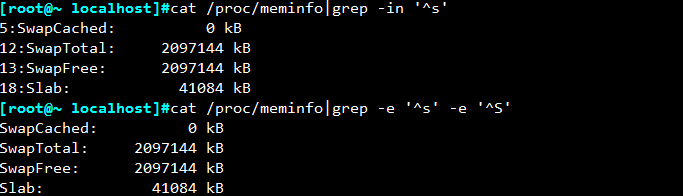
显示/proc/meminfo文件中以大小s开头的行:
cat /proc/meminfo|grep -in '^s'或者 cat /proc/meminfo|grep -e '^s' -e '^S'
8、仅显示匹配到的字符串
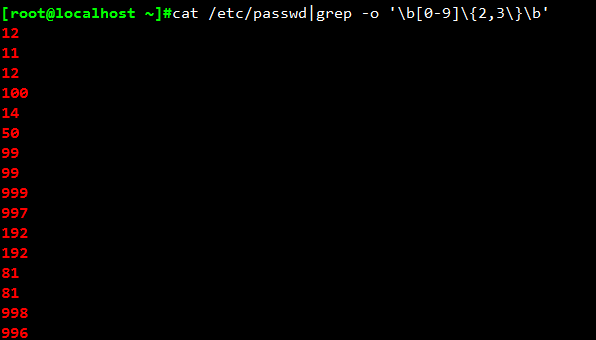
找出/etc/passwd中的两位或三位数的数字:cat /etc/passwd|grep -o '\b[0-9]\{2,3\}\b'
其中,-o表示仅显示匹配到的字符串。
\{m,n\}表示前面的字符至少出现m次,至多出现n次。此处是至少出现2位数,至多出现3位数。
9、分组的使用:
找出/etc/passwd用户名同shell名的行:cat /etc/passwd|grep '^\(\b.*\b\):.*\1$'
其中:\(\)是分组的表示,\1是引用分组变量。
注意:\(\)是分组的使用;\{\}是前面字符出现次数的使用;[]是匹配任意一个中括号里面指定的字符。
附:
egrep:
egrep = grep -E 可以使用基本的正则表达外, 还可以用扩展表达式. 注意区别.
扩展表达式:
+ 匹配一个或者多个先前的字符, 至少一个先前字符.
? 匹配0个或者多个先前字符.
a|b|c 匹配a或b或c
() 字符组, 如: love(able|ers) 匹配loveable或lovers.
(..)(..)\1\2 模板匹配. \1代表前面第一个模板, \2代第二个括弧里面的模板.
x{m,n} =x\{m,n\} x的字符数量在m到n个之间.
grep的用法(CentOS7)及有关正则表达式的使用的更多相关文章
- 文本三剑客之grep的用法
第1章 正则表达式 1.1 正则表达式的介绍 正则是用来过滤文件内容 为处理大量文本|字符串而定义的一套规则和方法. ...
- grep的用法
grep的用法首先创建我们练习grep命令时需要用到的demo文件demo_file. $ cat demo_file THIS LINE IS THE 1ST UPPER CASE LINE IN ...
- grep精确匹配搜索某个单词的用法 (附: grep高效用法小结))
grep(global search regular expression(RE) and print out the line,全面搜索正则表达式并把行打印出来)是一种强大的文本搜索工具,它能使用正 ...
- grep常用用法
grep常用用法 [root@www ~]# grep [-acinv] [--color=auto] '搜寻字符串' filename 选项与参数: -a :将 binary 文件以 text 文件 ...
- <三剑客> 老三:grep命令用法
grep(global search regular expression(RE) and print out the line,全面搜索正则表达式并把行打印出来)是一种强大的文本搜索工具,它能使用正 ...
- grep简单用法
grep 常用参数: -c: 打印符合要求的行数 -i :忽略大小写 -n:输出行和行号 -v:打印不符合要求的行,即反选 -A:后跟数字(有无空格都可以),例如-A2 表示打印筛选行及前2行 -B: ...
- linux grep的用法
linux grep的用法<pre>[root@iZ23uewresmZ ~]# cat /home/ceshis.txtb124230 b034325 a081016 m7187998 ...
- Ubuntu下,grep的用法
grep(Global search Regular Expression and Print out the line)是一种强大的文本搜索工具,它能使用正则表达式搜索文本,并把匹配的行打印出来.U ...
- grep命令用法
linux中grep命令的用法 作为linux中最为常用的三大文本(awk,sed,grep)处理工具之一,掌握好其用法是很有必要的. 首先谈一下grep命令的常用格式为:grep [选项] ”模 ...
随机推荐
- Socket的UDP协议在erlang中的实现
现在我们看看UDP协议(User Datagram Protocol,用户数据报协议).使用UDP,互联网上的机器之间可以互相发送小段的数据,叫做数据报.UDP数据报是不可靠的,这意味着如果客户端发送 ...
- 【NOI2015】【程序自己主动分析】【并查集+离散化】
Description 在实现程序自己主动分析的过程中,经常须要判定一些约束条件能否被同一时候满足. 考虑一个约束满足问题的简化版本号:如果x1,x2,x3,-代表程序中出现的变量.给定n个形如xi= ...
- 【CF830C】Bamboo Partition 分块
[CF830C]Bamboo Partition 题解:给你n个数a1,a2...an和k,求最大的d使得$\sum\limits_{i=1}^n((d-a[i] \% d) \% d) \le k$ ...
- 【BZOJ2457】[BeiJing2011]双端队列 贪心+模拟
[BZOJ2457][BeiJing2011]双端队列 Description Sherry现在碰到了一个棘手的问题,有N个整数需要排序. Sherry手头能用的工具就是若 ...
- sqlite与sqlserver区别
1.查询时把两个字段拼接在一起 --sqlserver-- select Filed1+'@'+Filed2 from table --sqlite-- select Filed1||'@'||Fil ...
- 不依赖外部js es 库 实现 点击内容 切换
<!DOCTYPE html> <html lang="zh-cmn-Hans"> <head> <meta http-equiv=&qu ...
- imagecopyresampled()改变图片大小后质量要比imagecopyresized()高。
php程序中改变图片大小的函数大多数人都想到用imagecopyresized(),不过经过测试比较发现,使用imagecopyresampled()改变的图片质量更高. 下面我们来看看两者的比较结果 ...
- PHP获取 当前页面名称、主机名、URL完整地址、URL参数、获取IP
$URL['PHP_SELF'] = isset($_SERVER['PHP_SELF']) ? $_SERVER['PHP_SELF'] : (isset($_SERVER['SCRIPT_NAME ...
- Machine Learning No.4: Regularization
1. Underfit = High bias Overfit = High varience 2. Addressing overfitting: (1) reduce number of feat ...
- Step 0: 安装及启动
一.Setting up a Single Node Cluster: http://hadoop.apache.org/docs/r2.6.5/hadoop-project-dist/hadoop- ...