统计学习方法:KNN
作者:桂。
时间:2017-04-19 21:20:09
链接:http://www.cnblogs.com/xingshansi/p/6736385.html
声明:欢迎被转载,不过记得注明出处哦~

前言
本文为《统计学习方法》第三章:KNN(k-Nearest Neighbor),主要包括:
1)KNN原理及代码实现;
2)K-d tree原理;
内容为自己的学习记录,其中多有借鉴他人的地方,最后一并给出链接。
一、KNN原理及代码实现
KNN对应算法流程:

其实就是在指定准则下,最近的K个决定了自身的类别。
- LP距离

p=2时为欧式距离(Euclidean distance),p=1为曼哈顿距离(Manhattan distance),p=∞对应最大值。

- K值选择
K通常选较小的数值,且通过交叉验证来寻优。
试着写了三种距离下的KNN,给出主要代码:
function resultLabel = knn(test,data,labels,k,flag)
%%
% test:test database
% data:train database
% labels:train data labels
% flag: distance criteria selection.
% 'E':Euclid Distance.
% 'M':Manhanttan distance.
% 'C':Cosine similarity.
%%
resultLabel=zeros(1,size(test,1));
dats.f=flag;
switch flag
case 'C'
Ifg='descend';
otherwise
Ifg='ascend';
end
for i=1:size(test,1)
dats.tes=test(i,:);
dats.tra=data;
distanceMat =distmode(dats);
[B , IX] = sort(distanceMat,Ifg);
len = min(k,length(B));
resultLabel(1,i) = mode(labels(IX(1:len)));
end
end
dismode.m:
function distanceMat =distmode(dats)
%distance calculation.
%%
% dats.tra:train database;
% dats.tes:test database;
% dats.f: distance flag;
%%
switch dats.f
case 'E'%Euclidean distance
p=2;
datarow = size(dats.tra,1);
diffMat = abs(repmat(dats.tes,[datarow,1]) - dats.tra) ;
distanceMat=(sum(diffMat.^p,2)).^1/p;
case 'M'%Manhanttan distance
p=1;
datarow = size(dats.tra,1);
diffMat = abs(repmat(dats.tes,[datarow,1]) - dats.tra) ;
distanceMat=(sum(diffMat.^p,2)).^1/p;
case 'C'%Cosine similarity
datarow = size(dats.tra,1);
tesMat = repmat(dats.tes,[datarow,1]) ;
diffup=sum(tesMat.*dats.tra,2);
diffdown=sqrt(sum(tesMat.*tesMat,2)).*sqrt(sum(dats.tra.*dats.tra,2));
distanceMat=diffup./diffdown;
end
二、K-d tree原理
KNN方法对于一个测试数据,需要与所有训练样本比对,再排序寻K个最优,现在换一个思路:如果在比对之前,就按某种规则排序(即构成一个二叉搜索树),这样一来,对于一个新的数据点,只要在前后寻K个最优即可,这样就提高了搜索的效率。
给出构造平衡kd树的算法:


以一个例子分析该思路,给定一个数据集:

对应思路:
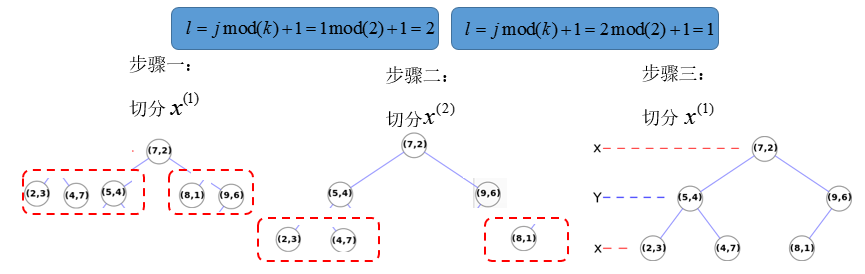
步骤一:x(1)的中位数:7,对应数据{7,2};按小于/大于分左右;
步骤二:1mod2+1=2,对x(2)的中位数,对第二层进行划分,左边中位数为5,右边中位数为9,依次划分;
步骤三:2mod2+1=1,对x(1)的第三层进行划分,结束,对应效果图:
为什么KD树可以这么构造?这也容易理解,对于一个数据点(x,y),距离公式为
,单单比较x是不够的,如果对x按大小已经切分,下一步怎么做?再按y进行切分,这样距离大小就被细化,查找范围进一步缩小,x切完y切,如果是三维,y切完z再切,对应数学表达就是
。
构造出了Kd tree之后,如何借助它解决kNN问题呢?
给出搜索kd tree的算法:


给出下图,现有(2,5)这个点,希望找出最近的K=3 个点:
分析步骤:
步骤一:包含(2,5)的叶节点,发现落在(4,7)节点区域内,(4,7)为当前最近点;
步骤二:检查(4,7)对应父节点(5,4)的另一个子节点(2,3),发现距离(2,5)更近,(2,5)记为当前最近点;
步骤三:向上回退到(5,4),此时(5,4)时子节点,其父节点为(7,2),依次类推。
具体如下图所示:
为什么KD树可以这么搜索?对应节点(右图)可以看出搜索按层回溯,对应左图就是先上下搜索,再往右推进。这样理解就比较直观,因为距离是越来越大的。
完成寻最优以后,最简单的办法是删除节点,重复寻最优,当然也可以存储不同结果,在少量样本中挑出K个最优

同理,对于三维数据,可以依次类推:

给出Kd tree的测试代码的效果图,code对应链接点击这里:

参考:
- http://blog.csdn.net/silangquan/article/details/41483689
- 李航《统计学习方法》
- https://en.wikipedia.org/wiki/K-d_tree
统计学习方法:KNN的更多相关文章
- 统计学习方法笔记 -- KNN
K近邻法(K-nearest neighbor,k-NN),这里只讨论基于knn的分类问题,1968年由Cover和Hart提出,属于判别模型 K近邻法不具有显式的学习过程,算法比较简单,每次分类都是 ...
- 统计学习方法学习(四)--KNN及kd树的java实现
K近邻法 1基本概念 K近邻法,是一种基本分类和回归规则.根据已有的训练数据集(含有标签),对于新的实例,根据其最近的k个近邻的类别,通过多数表决的方式进行预测. 2模型相关 2.1 距离的度量方式 ...
- 统计学习方法c++实现之二 k近邻法
统计学习方法c++实现之二 k近邻算法 前言 k近邻算法可以说概念上很简单,即:"给定一个训练数据集,对新的输入实例,在训练数据集中找到与这个实例最邻近的k个实例,这k个实例的多数属于某个类 ...
- 《统计学习方法》极简笔记P5:决策树公式推导
<统计学习方法>极简笔记P2:感知机数学推导 <统计学习方法>极简笔记P3:k-NN数学推导 <统计学习方法>极简笔记P4:朴素贝叶斯公式推导
- 【NLP】基于统计学习方法角度谈谈CRF(四)
基于统计学习方法角度谈谈CRF 作者:白宁超 2016年8月2日13:59:46 [摘要]:条件随机场用于序列标注,数据分割等自然语言处理中,表现出很好的效果.在中文分词.中文人名识别和歧义消解等任务 ...
- 统计学习方法 --- 感知机模型原理及c++实现
参考博客 Liam Q博客 和李航的<统计学习方法> 感知机学习旨在求出将训练数据集进行线性划分的分类超平面,为此,导入了基于误分类的损失函数,然后利用梯度下降法对损失函数进行极小化,从而 ...
- 统计学习方法笔记--EM算法--三硬币例子补充
本文,意在说明<统计学习方法>第九章EM算法的三硬币例子,公式(9.5-9.6如何而来) 下面是(公式9.5-9.8)的说明, 本人水平有限,怀着分享学习的态度发表此文,欢迎大家批评,交流 ...
- 统计学习方法:罗杰斯特回归及Tensorflow入门
作者:桂. 时间:2017-04-21 21:11:23 链接:http://www.cnblogs.com/xingshansi/p/6743780.html 前言 看到最近大家都在用Tensor ...
- 统计学习方法:核函数(Kernel function)
作者:桂. 时间:2017-04-26 12:17:42 链接:http://www.cnblogs.com/xingshansi/p/6767980.html 前言 之前分析的感知机.主成分分析( ...
随机推荐
- SQL Sever数据库的基本操作和它的建立
SQL数据库: 1.数据库概述 (1) 用自定义文件格式保存数据的劣势. (2) DBMS(DataBase Management System,数据库管理系统)和数据库,平时谈到"数据库& ...
- css3滚动效果
.css{ -webkit-transition-duration: .3s; transition-duration: .3s; }
- 几种功能类似Linux命令汇总
wc 命令用于统计文本的行数.字数.字节数,格式为"wc [参数] 文本". -l 只显示行数 -w 只显示单词数 -c 只显示字节数 例:统计当前系统中的用户个数: [roo ...
- 自定义 Layout布局 UICollectionViewLayout
from: http://www.tuicool.com/articles/vuyIriN 当我们使用系统自带的UICollectionViewFlowLayout无法实现我们的布局时,我们就可以 ...
- node删除当前文件底下全部文件的正确姿势
今天在项目上犯了一个很愚蠢的错误 执行如下,结果删除掉了项目根目录底下的所有配置文件,导致本地虚拟机挂掉,这次多一个/的给我教训真是莫大的...哎 正确的姿势为:
- eclipse一直报An internal error occurred during: "Building workspace". GC overhead limit exceeded
最近导入到eclipse里的工程挺大的,每次eclipse启动之后都回update workspace,然后就一直报: An internal error occurred during: " ...
- mac环境下安装xampp
首先下载XAMPP,然后配置虚拟域名hosts,再配置Apache服务, 配置Apache服务 1.打开/Applications/XAMPP/xamppfiles/etc/httpd.conf文件, ...
- IOS推送--之开发模式测试
参考文章:http://blog.csdn.net/showhilllee/article/details/8631734#comments 第一步.下载你工程的开发证书 第二步.从钥匙串访问中导出秘 ...
- NGUI 解决UILable 在空行起始位置加‘\n’
NGUI 解决UILable 默认在顶满第一行时,在起始位置如键入空格无效,其原因就是会加入换行符,使字符串,整体换行了 解决办法加入bool变量控制 1在 UILable代码中添加 [HideInI ...
- Zookeeper-3.4.9 集群搭建
这里用了三台主机,系统为CentOS7 1.修改hosts #vim /etc/hosts 172.50.0.31 node1 172.50.0.34 node2 172.50.0.37 node3 ...