外部排序&多路归并排序
外部排序:
一、定义问题
外部排序指的是大文件的排序,即待排序的记录存储在外存储器上,待排序的文件无法一次装入内存,需要在内存和外部存储器之间进行多次数据交换,以达到排序 整个文件的目的。外部排序最常用的算法是多路归并排序,即将原文件分解成多个能够一次性装入内存的部分,分别把每一部分调入内存完成排序。然后,对已经排 序的子文件进行多路归并排序。
二、处理过程
(1)按可用内存的大小,把外存上含有n个记录的文件分成若干个长度为L的子文件,把这些子文件依次读入内存,并利用有效的内部排序方法对它们进行排序,再将排序后得到的有序子文件重新写入外存;
(2)对这些有序子文件逐趟归并,使其逐渐由小到大,直至得到整个有序文件为止。
先从一个例子来看外排序中的归并是如何进行的?
假设有一个含10000 个记录的文件,首先通过10 次内部排序得到10 个初始归并段R1~R10 ,其中每一段都含1000 个记录。然后对它们作如图10.11 所示的两两归并,直至得到一个有序文件为止 如下图

三 、多路归并排序算法以及败者树
多路归并排序算法在常见数据结构书中都有涉及。从2路到多路(k路),增大k可以减少外存信息读写时间,但k个归并段中选取最小的记录需要比较k-1次, 为得到u个记录的一个有序段共需要(u-1)(k-1)次,若归并趟数为s次,那么对n个记录的文件进行外排时,内部归并过程中进行的总的比较次数为 s(n-1)(k-1),也即(向上取整)(logkm)(k-1)(n-1)=(向上取整)(log2m/log2k)(k-1)(n-1),而(k- 1)/log2k随k增而增因此内部归并时间随k增长而增长了,抵消了外存读写减少的时间,这样做不行,由此引出了“败者树”tree of loser的使用。在内部归并过程中利用败者树将k个归并段中选取最小记录比较的次数降为(向上取整)(log2k)次使总比较次数为(向上取整) (log2m)(n-1),与k无关。
败者树是完全二叉树, 因此数据结构可以采用一维数组。其元素个数为k个叶子结点、k-1个比较结点、1个冠军结点共2k个。ls[0]为冠军结点,ls[1]--ls[k- 1]为比较结点,ls[k]--ls[2k-1]为叶子结点(同时用另外一个指针索引b[0]--b[k-1]指向)。另外bk为一个附加的辅助空间,不 属于败者树,初始化时存着MINKEY的值。
多路归并排序算法的过程大致为:
1):首先将k个归并段中的首元素关键字依次存入b[0]--b[k-1]的叶子结点空间里,然后调用CreateLoserTree创建败者树,创建完毕之后最小的关键字下标(即所在归并段的序号)便被存入ls[0]中。然后不断循环:
2)把ls[0]所存最小关键字来自于哪个归并段的序号得到为q,将该归并段的首元素输出到有序归并段里,然后把下一个元素关键字放入上一个元素本来所 在的叶子结点b[q]中,调用Adjust顺着b[q]这个叶子结点往上调整败者树直到新的最小的关键字被选出来,其下标同样存在ls[0]中。循环这个 操作过程直至所有元素被写到有序归并段里。
外部排序之多路归并
该外部排序上场了.
外部排序干嘛的?
- 内存极少的情况下,利用分治策略,利用外存保存中间结果,再用多路归并来排序;
- map-reduce的嫡系.


1.分
内存中维护一个极小的核心缓冲区bigdata按行读入,搜集到memBuffer中的数据调用内排进行排序,排序后将有序结果写入磁盘文件
循环利用

2.合
现在有了n个有序的小文件,怎么合并成1个有序的大文件?
把所有小文件读入内存,然后内排?
(⊙o⊙)…
no!
利用如下原理进行归并排序:
我们举个简单的例子:

文件1:3,6,9
文件2:2,4,8
文件3:1,5,7第一回合:
文件1的最小值:3 , 排在文件1的第1行
文件2的最小值:2,排在文件2的第1行
文件3的最小值:1,排在文件3的第1行
那么,这3个文件中的最小值是:min(1,2,3) = 1
也就是说,最终大文件的当前最小值,是文件1、2、3的当前最小值的最小值,绕么?
上面拿出了最小值1,写入大文件.
第二回合:
文件1的最小值:3 , 排在文件1的第1行
文件2的最小值:2,排在文件2的第1行
文件3的最小值:5,排在文件3的第2行
那么,这3个文件中的最小值是:min(5,2,3) = 2
将2写入大文件.也就是说,最小值属于哪个文件,那么就从哪个文件当中取下一行数据.(因为小文件内部有序,下一行数据代表了它当前的最小值)
败者树可以改善时间复杂度:
胜者树与败者树
胜者树和败者树都是完全二叉树,是树形选择排序的一种变型。每个叶子结点相当于一个选手,每个中间结点相当于一场比赛,每一层相当于一轮比赛。
不同的是,胜者树的中间结点记录的是胜者的标号;而败者树的中间结点记录的败者的标号。
胜者树与败者树可以在log(n)的时间内找到最值。任何一个叶子结点的值改变后,利用中间结点的信息,还是能够快速地找到最值。在k路归并排序中经常用到。
一、胜者树
胜者树的一个优点是,如果一个选手的值改变了,可以很容易地修改这棵胜者树。只需要沿着从该结点到根结点的路径修改这棵二叉树,而不必改变其他比赛的结果。
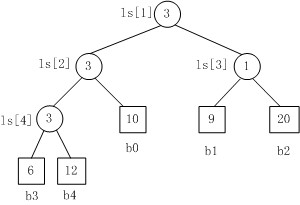
Fig. 1
Fig.1是一个胜者树的示例。规定数值小者胜。
1. b3 PK b4,b3胜b4负,内部结点ls[4]的值为3;
2. b3 PK b0,b3胜b0负,内部结点ls[2]的值为3;
3. b1 PK b2,b1胜b2负,内部结点ls[3]的值为1;
4. b3 PK b1,b3胜b1负,内部结点ls[1]的值为3。.
当Fig. 1中叶子结点b3的值变为11时,重构的胜者树如Fig. 2所示。
1. b3 PK b4,b3胜b4负,内部结点ls[4]的值为3;
2. b3 PK b0,b0胜b3负,内部结点ls[2]的值为0;
3. b1 PK b2,b1胜b2负,内部结点ls[3]的值为1;
4. b0 PK b1,b1胜b0负,内部结点ls[1]的值为1。.
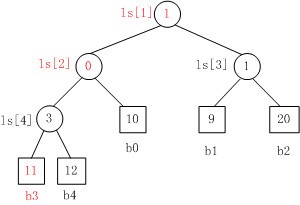
Fig. 2
二、败者树
败者树是胜者树的一种变体。在败者树中,用父结点记录其左右子结点进行比赛的败者,而让胜者参加下一轮的比赛。败者树的根结点记录的是败者,需要加一个结点来记录整个比赛的胜利者。采用败者树可以简化重构的过程。
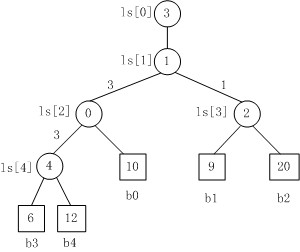
Fig. 3
Fig. 3是一棵败者树。规定数大者败。
1. b3 PK b4,b3胜b4负,内部结点ls[4]的值为4;
2. b3 PK b0,b3胜b0负,内部结点ls[2]的值为0;
3. b1 PK b2,b1胜b2负,内部结点ls[3]的值为2;
4. b3 PK b1,b3胜b1负,内部结点ls[1]的值为1;
5. 在根结点ls[1]上又加了一个结点ls[0]=3,记录的最后的胜者。
败者树重构过程如下:
· 将新进入选择树的结点与其父结点进行比赛:将败者存放在父结点中;而胜者再与上一级的父结点比较。
· 比赛沿着到根结点的路径不断进行,直到ls[1]处。把败者存放在结点ls[1]中,胜者存放在ls[0]中。
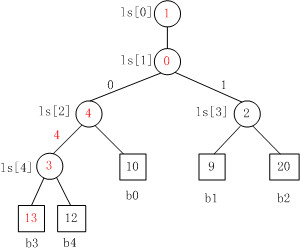
Fig. 4
Fig. 4是当b3变为13时,败者树的重构图。
注意,败者树的重构跟胜者树是不一样的,败者树的重构只需要与其父结点比较。对照Fig.
3来看,b3与结点ls[4]的原值比较,ls[4]中存放的原值是结点4,即b3与b4比较,b3负b4胜,则修改ls[4]的值为结点3。同理,以此
类推,沿着根结点不断比赛,直至结束。
由上可知,败者树简化了重构。败者树的重构只是与该结点的父结点的记录有关,而胜者树的重构还与该结点的兄弟结点有关。
二 使用败者树加快合并排序
外部排序最耗时间的操作时磁盘读写,对于有m个初始归并段,k路平衡的归并排序,磁盘读写次数为
|logkm|,可见增大k的值可以减少磁盘读写的次数,但增大k的值也会带来负面效应,即进行k路合并
的时候会增加算法复杂度,来看一个例子。
把n个整数分成k组,每组整数都已排序好,现在要把k组数据合并成1组排好序的整数,求算法复杂度
u1: xxxxxxxx
u2: xxxxxxxx
u3: xxxxxxxx
.......
uk: xxxxxxxx
算法的步骤是:每次从k个组中的首元素中选一个最小的数,加入到新组,这样每次都要比较k-1次,故
算法复杂度为O((n-1)*(k-1)),而如果使用败者树,可以在O(logk)的复杂度下得到最小的数,算法复杂
度将为O((n-1)*logk), 对于外部排序这种数据量超大的排序来说,这是一个不小的提高。
外部排序&多路归并排序的更多相关文章
- sphinx索引分析——文件格式和字典是double array trie 检索树,索引存储 – 多路归并排序,文档id压缩 – Variable Byte Coding
1 概述 这是基于开源的sphinx全文检索引擎的架构代码分析,本篇主要描述index索引服务的分析.当前分析的版本 sphinx-2.0.4 2 index 功能 3 文件表 4 索引文件结构 4. ...
- Hark的数据结构与算法练习之多路归并排序
算法说明 多路归并排序也叫k路归并排序,实际上是归并排序的扩展版,同样也是归并排序的一种,通常的应用场景的针对大数据量的排序. 实现过程: 1.从字面可以看出,多路归并就是将待排的大数据量分成K路,然 ...
- 大数据排序算法:外部排序,bitmap算法;大数据去重算法:hash算法,bitmap算法
外部排序算法相关:主要用到归并排序,堆排序,桶排序,重点是先分成不同的块,然后从每个块中找到最小值写入磁盘,分析过程可以看看http://blog.csdn.net/jeason29/article/ ...
- Java排序之归并排序
Java排序之归并排序 1. 简介 归并排序的算法是将多个有序数据表合并成一个有序数据表.如果参与合并的只有两个有序表,则成为二路合并.对于一个原始的待排序数列,往往可以通过分割的方法来归结为多路合并 ...
- Go实现分布式外部排序
Go实现分布式外部排序 项目路径: https://github.com/Draymonders/go_external_sort 默认读入文件: small.in 默认输出文件:small.out ...
- sphinx 源码阅读之分词,压缩索引,倒排——单词对应的文档ID列表本质和lucene无异 也是外部排序再压缩 解压的时候需要全部扫描doc_ids列表偏移量相加获得最终的文档ID
转自:http://github.tiankonguse.com/blog/2014/12/03/sphinx-token-inverted-sort.html 外部排序 现在我们的背景是有16个已经 ...
- 经典排序算法 - 归并排序Merge sort
经典排序算法 - 归并排序Merge sort 原理,把原始数组分成若干子数组,对每个子数组进行排序, 继续把子数组与子数组合并,合并后仍然有序,直到所有合并完,形成有序的数组 举例 无序数组[6 2 ...
- java泛型中使用的排序算法——归并排序及分析
一.引言 我们知道,java中泛型排序使用归并排序或TimSort.归并排序以O(NlogN)最坏时间运行,下面我们分析归并排序过程及分析证明时间复杂度:也会简述为什么java选择归并排序作为泛型的排 ...
- 程序员必知的8大排序(四)-------归并排序,基数排序(java实现)
程序员必知的8大排序(一)-------直接插入排序,希尔排序(java实现) 程序员必知的8大排序(二)-------简单选择排序,堆排序(java实现) 程序员必知的8大排序(三)-------冒 ...
随机推荐
- geotrellis使用(二十九)迁移geotrellis至1.1.1版
目录 前言 升级过程 总结 一.前言 由于忙着安装OpenStack等等各种事情,有半年的时间没有再亲密的接触geotrellis,甚至有半年的时间没能畅快的写代码.近来OpenStac ...
- CJOJ 1071 【Uva】硬币问题(动态规划)
CJOJ 1071 [Uva]硬币问题(动态规划) Description 有n种硬币,面值分别为v1, v2, ..., vn,每种都有无限多.给定非负整数S,可以选用多少个硬币,使得面值之和恰好为 ...
- MVC MVC+EF快速搭建
MVC+EF快速搭建 一.准备: vs2017(个人用的) 二.开始MVC+EF之旅吧: 1.创建mvc项目: Web-ASP.NET Web Application(.NET Framework) ...
- java.util.Arrays类
前言:java.util.Arrays类的技术文档请查看Oracle官网 1.Arrays类常见方法: 本文参考资料:百度文库:Oracle官网:第三方中文技术文档
- 获取cpu真实型号
感谢文洋兄的思路.亲测有效. [root@storage GetCpuType]# ./main.o Intel(R) Xeon(R) CPU C5528 @ 2.13GHz #include < ...
- 【canvas学习笔记二】绘制图形
上一篇我们已经讲述了canvas的基本用法,学会了构建canvas环境.现在我们就来学习绘制一些基本图形. 坐标 canvas的坐标原点在左上角,从左到右X轴坐标增加,从上到下Y轴坐标增加.坐标的一个 ...
- 终极锁实战:单JVM锁+分布式锁
目录 1.前言 2.单JVM锁 3.分布式锁 4.总结 =========正文分割线================= 1.前言 锁就像一把钥匙,需要加锁的代码就像一个房间.出现互斥操作的场景:多人同 ...
- MySQL Database Command Line Client
.输入密码:****** 1.1.create datatable Name;创建数据库 1.2.source D://taotao.sql; source后面加sql文件是批量导入sql语句 .ue ...
- CentOS 6 下无法wget https链接的解决方法
CentOS6下最高版本的wget是1.11,但非常遗憾的是这个版本有bug,是没办法用来下载https链接的东西的,所以有些人为了避免这种情况会帮脚本加上不检查ssl的参数--no-check-ce ...
- 独立ip的优势
独立ip的建站优势 我想很多人都想知道,那我就在这里给大家简单介绍下独立ip的优势有那些. 网站设计是需要很多专业知识的结合,整站不是那么容易就可以设计完成的 ...