华为云·寻找黑马程序员#海量数据的分页怎么破?【华为云技术分享】
欢迎添加华为云小助手微信(微信号:HWCloud002 或 HWCloud003),验证通过后,输入关键字“加群”,加入华为云线上技术讨论群;输入关键字“最新活动”,获取华为云最新特惠促销。华为云诸多技术大咖、特惠活动等你来撩!
一、背景
分页应该是极为常见的数据展现方式了,一般在数据集较大而无法在单个页面中呈现时会采用分页的方法。
各种前端UI组件在实现上也都会支持分页的功能,而数据交互呈现所相应的后端系统、数据库都对数据查询的分页提供了良好的支持。
以几个流行的数据库为例:
查询表 t_data 第 2 页的数据(假定每页 5 条)
- MySQL 的做法:
select * from t_data limit ,
- PostGreSQL 的做法:
select * from t_data limit offset
- MongoDB 的做法:
db.t_data.find().limit().skip();
尽管每种数据库的语法不尽相同,通过一些开发框架封装的接口,我们可以不需要熟悉这些差异。如 SpringData 提供的分页接口:
public interface PagingAndSortingRepository
extends CrudRepository { Page findAll(Pageable pageable);
}
这样看来,开发一个分页的查询功能是非常简单的。
然而万事皆不可能尽全尽美,尽管上述的数据库、开发框架提供了基础的分页能力,在面对日益增长的海量数据时却难以应对,一个明显的问题就是查询性能低下!
那么,面对千万级、亿级甚至更多的数据集时,分页功能该怎么实现?
下面,我以 MongoDB 作为背景来探讨几种不同的做法。
二、传统方案
就是最常规的方案,假设 我们需要对文章 articles 这个表(集合) 进行分页展示,一般前端会需要传递两个参数:
- 页码(当前是第几页)
- 页大小(每页展示的数据个数)
按照这个做法的查询方式,如下图所示:
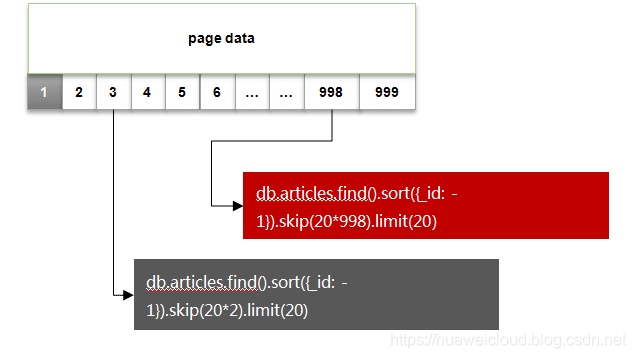
因为是希望最后创建的文章显示在前面,这里使用了_id 做降序排序。
其中红色部分语句的执行计划如下:
{
"queryPlanner" : {
"plannerVersion" : ,
"namespace" : "appdb.articles",
"indexFilterSet" : false,
"parsedQuery" : {
"$and" : []
},
"winningPlan" : {
"stage" : "SKIP",
"skipAmount" : ,
"inputStage" : {
"stage" : "FETCH",
"inputStage" : {
"stage" : "IXSCAN",
"keyPattern" : {
"_id" :
},
"indexName" : "_id_",
"isMultiKey" : false,
"direction" : "backward",
"indexBounds" : {
"_id" : [
"[MaxKey, MinKey]"
]
...
}
可以看到随着页码的增大,skip 跳过的条目也会随之变大,而这个操作是通过 cursor 的迭代器来实现的,对于cpu的消耗会比较明显。
而当需要查询的数据达到千万级及以上时,会发现响应时间非常的长,可能会让你几乎无法接受!
或许,假如你的机器性能很差,在数十万、百万数据量时已经会出现瓶颈
三、改良做法
既然传统的分页方案会产生 skip 大量数据的问题,那么能否避免呢?答案是可以的。
改良的做法为:
1. 选取一个唯一有序的关键字段,比如 _id,作为翻页的排序字段;
2. 每次翻页时以当前页的最后一条数据_id值作为起点,将此并入查询条件中。
如下图所示:

修改后的语句执行计划如下:
{
"queryPlanner" : {
"plannerVersion" : ,
"namespace" : "appdb.articles",
"indexFilterSet" : false,
"parsedQuery" : {
"_id" : {
"$lt" : ObjectId("5c38291bd4c0c68658ba98c7")
}
},
"winningPlan" : {
"stage" : "FETCH",
"inputStage" : {
"stage" : "IXSCAN",
"keyPattern" : {
"_id" :
},
"indexName" : "_id_",
"isMultiKey" : false,
"direction" : "backward",
"indexBounds" : {
"_id" : [
"(ObjectId('5c38291bd4c0c68658ba98c7'), ObjectId('000000000000000000000000')]"
]
...
}
可以看到,改良后的查询操作直接避免了昂贵的 skip 阶段,索引命中及扫描范围也是非常合理的!
性能对比
为了对比这两种方案的性能差异,下面准备了一组测试数据。
测试方案
准备10W条数据,以每页20条的参数从前往后翻页,对比总体翻页的时间消耗
db.articles.remove({});
var count = ;
var items = [];
for(var i=; i<=count; i++){
var item = {
"title": "论年轻人思想建设的重要性-" + i,
"author" : "王小兵-" + Math.round(Math.random() * ),
"type" : "杂文-" + Math.round(Math.random() * ) ,
"publishDate" : new Date(),
} ;
items.push(item);
if(i%==){
db.test.insertMany(items);
print("insert", i);
items = [];
}
}
传统翻页脚本
function turnPages(pageSize, pageTotal){
print("pageSize:", pageSize, "pageTotal", pageTotal)
var t1 = new Date();
var dl = [];
var currentPage = ;
//轮询翻页
while(currentPage < pageTotal){
var list = db.articles.find({}, {_id:}).sort({_id: -}).skip(currentPage*pageSize).limit(pageSize);
dl = list.toArray();
//没有更多记录
if(dl.length == ){
break;
}
currentPage ++;
//printjson(dl)
}
var t2 = new Date();
var spendSeconds = Number((t2-t1)/).toFixed()
print("turn pages: ", currentPage, "spend ", spendSeconds, ".")
}
改良翻页脚本
function turnPageById(pageSize, pageTotal){
print("pageSize:", pageSize, "pageTotal", pageTotal)
var t1 = new Date();
var dl = [];
var currentId = ;
var currentPage = ;
while(currentPage ++ < pageTotal){
//以上一页的ID值作为起始值
var condition = currentId? {_id: {$lt: currentId}}: {};
var list = db.articles.find(condition, {_id:}).sort({_id: -}).limit(pageSize);
dl = list.toArray();
//没有更多记录
if(dl.length == ){
break;
}
//记录最后一条数据的ID
currentId = dl[dl.length-]._id;
}
var t2 = new Date();
var spendSeconds = Number((t2-t1)/).toFixed()
print("turn pages: ", currentPage, "spend ", spendSeconds, ".")
}
以100、500、1000、3000页数的样本进行实测,结果如下:

可见,当页数越大(数据量越大)时,改良的翻页效果提升越明显!
这种分页方案其实采用的就是时间轴(TImeLine)的模式,实际应用场景也非常的广,比如Twitter、微博、朋友圈动态都可采用这样的方式。
而同时除了上述的数据库之外,HBase、ElasticSearch 在Range Query的实现上也支持这种模式。
四、完美的分页
时间轴(TimeLine)的模式通常是做成“加载更多”、上下翻页这样的形式,但无法自由的选择某个页码。
那么为了实现页码分页,同时也避免传统方案带来的 skip 性能问题,我们可以采取一种折中的方案。
这里参考Google搜索结果页作为说明:

通常在数据量非常大的情况下,页码也会有很多,于是可以采用页码分组的方式。
以一段页码作为一组,每一组内数据的翻页采用ID 偏移量 + 少量的 skip 操作实现
具体的操作如下图所示:

实现步骤
对页码进行分组(groupSize=8, pageSize=20),每组为8个页码;
提前查询 end_offset,同时获得本组页码数量:
db.articles.find({ _id: { $lt: start_offset } }).sort({_id: -}).skip(*).limit()
- 分页数据查询以本页组 start_offset 作为起点,在有限的页码上翻页(skip),由于一个分组的数据量通常很小(8*20=160),在分组内进行skip产生的代价会非常小,因此性能上可以得到保证。
小结
随着物联网,大数据业务的白热化,一般企业级系统的数据量也会呈现出快速的增长。而传统的数据库分页方案在海量数据场景下很难满足性能的要求。
在本文的探讨中,主要为海量数据的分页提供了几种常见的优化方案(以MongoDB作为实例),并在性能上做了一些对比,旨在提供一些参考。
来源:华为云社区 作者:zale
欢迎添加华为云小助手微信(微信号:HWCloud002 或 HWCloud003),验证通过后,输入关键字“加群”,加入华为云线上技术讨论群;输入关键字“最新活动”,获取华为云最新特惠促销。华为云诸多技术大咖、特惠活动等你来撩!
HDC.Cloud 华为开发者大会2020 即将于2020年2月11日-12日在深圳举办,是一线开发者学习实践鲲鹏通用计算、昇腾AI计算、数据库、区块链、云原生、5G等ICT开放能力的最佳舞台。

华为云·寻找黑马程序员#海量数据的分页怎么破?【华为云技术分享】的更多相关文章
- 移动端开发语言的未来的猜想#华为云·寻找黑马程序员#【华为云技术分享】
版权声明:本文为博主原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接和本声明. 本文链接:https://blog.csdn.net/devcloud/article/detai ...
- 华为云·寻找黑马程序员#【代码重构之路】如何“消除”if/else【华为云技术分享】
1. 背景 if/else是高级编程语言中最基础的功能,虽然 if/else 是必须的,但滥用 if/else,特别是各种大量的if/else嵌套,会对代码的可读性.可维护性造成很大伤害,对于阅读代码 ...
- Python正则表达式,看完这篇文章就够了...#华为云·寻找黑马程序员#【华为云技术分享】
版权声明:本文为博主原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接和本声明. 本文链接:https://blog.csdn.net/devcloud/article/detai ...
- 重磅!华为云社区·CSDN【寻找黑马程序员】有奖征文活动奖项公布!!
华为云社区·CSDN[寻找黑马程序员]第一期有奖征文活动在大家的鼎力支持下顺利落幕啦,非常感谢大家一直以来的支持~现在小宅就要隆重公布本次活动的奖项了!! 请各位获奖的伙伴在8月18日前私信联系提供联 ...
- #华为云·寻找黑马程序员#【代码重构之路】如何“消除”if/else
1. 背景 if/else是高级编程语言中最基础的功能,虽然 if/else 是必须的,但滥用 if/else,特别是各种大量的if/else嵌套,会对代码的可读性.可维护性造成很大伤害,对于阅读代码 ...
- 大型情感剧集Selenium:1_介绍 #华为云·寻找黑马程序员#
学习selenium能做什么? 很多书籍.文章中是这么定义selenium的: Selenium 是开源的自动化测试工具,它主要是用于Web 应用程序的自动化测试,不只局限于此,同时支持所有基于web ...
- python让你再也不为文章配图与素材发愁,让高清图片占满你的硬盘! #华为云·寻找黑马程序员#
欢迎添加华为云小助手微信(微信号:HWCloud002 或 HWCloud003),输入关键字"加群",加入华为云线上技术讨论群:输入关键字"最新活动",获取华 ...
- #华为云·寻找黑马程序员# 如何实现一个优雅的Python的Json序列化库
在Python的世界里,将一个对象以json格式进行序列化或反序列化一直是一个问题.Python标准库里面提供了json序列化的工具,我们可以简单的用json.dumps来将一个对象序列化.但是这种序 ...
- 使用Python开发小说下载器,不再为下载小说而发愁 #华为云·寻找黑马程序员#
需求分析 免费的小说网比较多,我看的比较多的是笔趣阁.这个网站基本收费的章节刚更新,它就能同步更新,简直不要太叼.既然要批量下载小说,肯定要分析这个网站了- 在搜索栏输入地址后,发送post请求获取数 ...
随机推荐
- [考试反思]1003csp-s模拟测试58:沉淀
稳住阵脚. 还可以. 至少想拿到的分都拿到了,最后一题的确因为不会按秩合并和线段树分治而想不出来. 对拍了,暴力都拍了.挺稳的. 但是其实也有波折,险些被卡内存. 如果内存使用不连续或申请的内存全部使 ...
- CSPS模拟 91
T1 sz最多根号种 T2 没计算内存,水过了..CSPS这样的话要爆零的qaq T3 感谢miku带我重学ST表%%%%%
- hadoop2.9.0之前的版本yarn RM fairScheduler调度性能优化
对一般小公司来说 可能yarn调度能力足够了 但是对于大规模集群1000 or 2000+的话 yarn的调度性能捉襟见肘 恰好网上看到一篇很好的文章https://tech.meituan.com ...
- LNMP+Redis架构部署
工作机制 L(Linux)N(Nginx)M(Mysql)P(PHP)架构想必大家都知道,LNMP架构主要作用是让前端服务与后端存储以及后端的一下服务进行连接起来,来实现php程序的动态请求. 而今天 ...
- haproxy+keepalived练习
小的网站结构 说明:如果部署在云上,比如阿里云上,不需要自己部署keepalived,直接买阿里云的slb即可,slb然后分发流量到两台haproxy机器 一.先部署两个web服务器 编译安装ngin ...
- 致和我一样迷茫的Java程序员们
缘起 从事近7年Java开发之后,在2019年这个寒冷的冬天里,我终于迎来了人生中的第一次裁员. 啊,30岁之后的裁员真让人焦虑. 按照以往惯例,在面试心仪的公司之前,需要先面试一些不那么心仪的公司热 ...
- Weblogic 12c 的 Apache HTTP Server 整合插件(Plug-In)下载地址
资料来源:到哪里下载Weblogic 12c 的Plug-In 为 Apache HTTP Server 摘录如下: 最新的Weblogic 12c不再为 Apache HTTP Server提供缺省 ...
- 《计算机网络 自顶向下方法》 第3章 运输层 Part1
由于个人精力和智商有限,又喜欢想太多.钻牛角尖,导致学习系统性知识很痛苦,尝试改变学习方式,慢慢摸索 现在看到 rdt2.0,又有点看不下去 现在的想法: 要有个目标,且有截止时间(作业模式.考试模式 ...
- SqlServer2005 查询 第三讲 between
在数据库的查询中最重要的是要知道命令的顺序,因为在sql命令中有许多的参数,例如distinct,top,in,order by,group by.......如果你不能理解什么时候该执行什么的话,很 ...
- 将 /u 转变为 utf-8 编码
将 /u 转变为 utf-8 编码 PHP实例: $result = {"errno":-1,"message":"\u8bbf\u95ee\u5fa ...