聚类-DBSCAN基于密度的空间聚类
1.DBSCAN介绍
密度聚类方法的指导思想是,只要样本点的密度大于某阈值,则将该样本添加到最近的簇中。
这类算法能克服基于距离的算法只能发现“类圆形”的聚类的缺点,可发现任意形状的聚类,且对噪声数据不敏感。但计算密度单元的计算复杂度大,需要建立空间索引来降低计算量。
- DBSCAN
- 密度最大值算法
DBSCAN(Density-Based Spatial Clustering of Applications with Noise,具有噪声的基于密度的聚类方法)是一种基于密度的空间聚类算法。 该算法将具有足够密度的区域划分为簇,并在具有噪声的空间数据库中发现任意形状的簇,它将簇定义为密度相连的点的最大集合。

基于密度这点有什么好处呢,我们知道kmeans聚类算法只能处理球形的簇,也就是一个聚成实心的团(这是因为算法本身计算平均距离的局限)。但往往现实中还会有各种形状,比如下面两张图,环形和不规则形,这个时候,那些传统的聚类算法显然就悲剧了。于是就思考,样本密度大的成一类呗。呐这就是DBSCAN聚类算法
推荐一个很形象的描述DBSCAN的网站,可视化
https://www.naftaliharris.com/blog/visualizing-dbscan-clustering/
2.DBSCAN的重要参数
(1)eps 相当于圈的半径,越大越小都不好,自己合适调节
(2)min_samples 相当于一个圈中最少的样本数,不到的话,就被划分为离散点
(3)metric

3.DBSCAN案例
import warnings
warnings.filterwarnings('ignore')
import numpy as np
import matplotlib.pyplot as plt
%matplotlib inline from sklearn import datasets
from sklearn.cluster import DBSCAN,KMeans
# noise控制叠加的噪声的大小
X,y = datasets.make_circles(n_samples=1000,noise = 0.1,factor = 0.3) # centers=[[1.5,1.5]] 坐标位置,在1.5,1.5生成
X3,y3 = datasets.make_blobs(n_samples=500,n_features=2,centers=[[1.5,1.5]],cluster_std=0.2) # 将两个数据级联
X = np.concatenate([X,X3]) y = np.concatenate([y,y3+2]) plt.scatter(X[:,0],X[:,1],c = y)
生成的数据:

# kmeans
# 有缺陷
kmeans = KMeans(3)
kmeans.fit(X)
y_ = kmeans.predict(X)
plt.scatter(X[:,0],X[:,1],c = y_)
kmeans形成的:可以看出,效果很不好
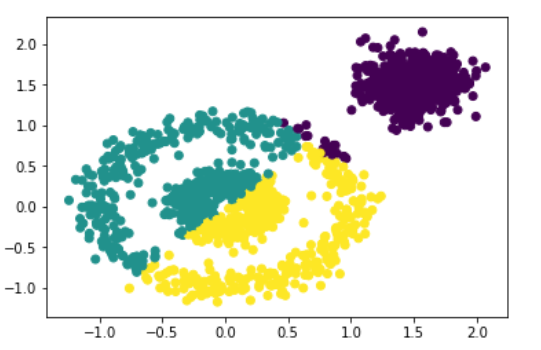
# dbcan
dbscan = DBSCAN(eps = 0.15,min_samples=5)
dbscan.fit(X)
# y_ = dbscan.fit_predict(X)
y_ = dbscan.labels_
plt.scatter(X[:,0],X[:,1],c = y_)
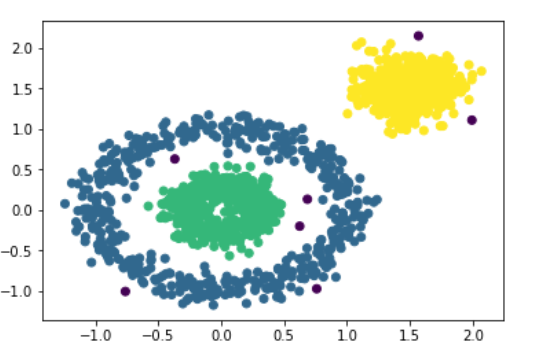
可以看出来,使用dbscan效果明显不错
之后,可以再使用之前kmeans中的评测指标才评测一下
4.总结一下DBSCAN流程:
DBSCAN 从一个没有被访问过的任意起始数据点开始。这个点的邻域是用距离 ε(ε 距离内的所有点都是邻域点)提取的。
如果在这个邻域内有足够数量的点(根据 minPoints),则聚类过程开始,并且当前数据点成为新簇的第一个点。否则,该点将会被标记为噪声(稍后这个噪声点可能仍会成为聚类的一部分)。在这两种情况下,该点都被标记为「已访问」。
对于新簇中的第一个点,其 ε 距离邻域内的点也成为该簇的一部分。这个使所有 ε 邻域内的点都属于同一个簇的过程将对所有刚刚添加到簇中的新点进行重复。
重复步骤 2 和 3,直到簇中所有的点都被确定,即簇的 ε 邻域内的所有点都被访问和标记过。
一旦我们完成了当前的簇,一个新的未访问点将被检索和处理,导致发现另一个簇或噪声。重复这个过程直到所有的点被标记为已访问。由于所有点都已经被访问,所以每个点都属于某个簇或噪声。
5.DBSCAN的优缺点
优点:
DBSCAN 与其他聚类算法相比有很多优点。首先,它根本不需要固定数量的簇。它也会将异常值识别为噪声,而不像均值漂移,即使数据点非常不同,也会简单地将它们分入簇中。另外,它能够很好地找到任意大小和任意形状的簇。
缺点:
DBSCAN 的主要缺点是当簇的密度不同时,它的表现不如其他聚类算法。这是因为当密度变化时,用于识别邻域点的距离阈值 ε 和 minPoints 的设置将会随着簇而变化。这个缺点也会在非常高维度的数据中出现,因为距离阈值 ε 再次变得难以估计。
补充:
密度最大值聚类:其实就是看哪个簇的密度最大的
高局部密度点距离:换句话说,就是找比你有钱的距离你最近的人的距离

根据高局部密度点距离,可以识别簇中心:

聚类-DBSCAN基于密度的空间聚类的更多相关文章
- 基于密度峰值的聚类(DPCA)
1.背景介绍 密度峰值算法(Clustering by fast search and find of density peaks)由Alex Rodriguez和Alessandro Laio于20 ...
- sklearn聚类模型:基于密度的DBSCAN;基于混合高斯模型的GMM
1 sklearn聚类方法详解 2 对比不同聚类算法在不同数据集上的表现 3 用scikit-learn学习K-Means聚类 4 用scikit-learn学习DBSCAN聚类 (基于密度的聚类) ...
- DBSCAN聚类︱scikit-learn中一种基于密度的聚类方式
一.DBSCAN聚类概述 基于密度的方法的特点是不依赖于距离,而是依赖于密度,从而克服基于距离的算法只能发现"球形"聚簇的缺点. DBSCAN的核心思想是从某个核心点出发,不断向密 ...
- 基于密度聚类的DBSCAN和kmeans算法比较
根据各行业特性,人们提出了多种聚类算法,简单分为:基于层次.划分.密度.图论.网格和模型的几大类. 其中,基于密度的聚类算法以DBSCAN最具有代表性. 场景 一 假设有如下图的一组数据, 生成数据 ...
- 简单易学的机器学习算法——基于密度的聚类算法DBSCAN
一.基于密度的聚类算法的概述 最近在Science上的一篇基于密度的聚类算法<Clustering by fast search and find of density peaks> ...
- 聚类:层次聚类、基于划分的聚类(k-means)、基于密度的聚类、基于模型的聚类
一.层次聚类 1.层次聚类的原理及分类 1)层次法(Hierarchicalmethods)先计算样本之间的距离.每次将距离最近的点合并到同一个类.然后,再计算类与类之间的距离,将距离最近的类合并为一 ...
- R与数据分析旧笔记(十六) 基于密度的方法:DBSCAN
基于密度的方法:DBSCAN 基于密度的方法:DBSCAN DBSCAN=Density-Based Spatial Clustering of Applications with Noise 本算法 ...
- 【Python机器学习实战】聚类算法(2)——层次聚类(HAC)和DBSCAN
层次聚类和DBSCAN 前面说到K-means聚类算法,K-Means聚类是一种分散性聚类算法,本节主要是基于数据结构的聚类算法--层次聚类和基于密度的聚类算法--DBSCAN两种算法. 1.层次聚类 ...
- 基于密度的聚类之Dbscan算法
一.算法概述 DBSCAN(Density-Based Spatial Clustering of Applications with Noise)是一个比较有代表性的基于密度的聚类算法.与划分和层次 ...
随机推荐
- WinDbg命令系统
WinDbg命令系统 WinDbug三种命令 WinDbug是一个强大的调试器,大部分很多功能都是通过命令来实现的,命令在命令窗口中输入,主要分为以下三类: 标准命令 标准命令提供了调试器的基本功能, ...
- 面向对象的7个设计原则->开车理解->贴近生活
设计模式在我们的开发中是不可或缺的一部分,很多人会说,我没用那些设计模式啊,我也开发的挺好的,其实不然,我们在开发中都用到了这些设计模式,只不过我们并没有在意这些,今天我就用开车的方法来解释一下我们的 ...
- 【排列组合】给定一个M*N的格子或棋盘,从左下角走到右上角的走法总数(每次只能向右或向上移动一个方格边长的距离)
版权声明:本文为CSDN博主「梵解君」的原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接及本声明. 原文链接:https://blog.csdn.net/hadeso/art ...
- [Java] 生成二维码源码,可以在二维码中间加logo,底部可以加文字介绍
链接:https://pan.baidu.com/s/1bc1h-ix-No-2o9Ysd4_B3Q提取码:0ad4
- VS环境下基于C++的单链表实现
------------恢复内容开始------------ #include<iostream> using namespace::std; typedef int ElemType; ...
- P3665 [USACO17OPEN]Switch Grass
题目描述 N个点M条边的无向图,每个点有一个初始颜色,每次改变一个点的颜色,求改变后整张图上颜色不同的点之间的距离最小值. 思路 考虑整张图的距离最小值一定是一条边,而不可能是一条路径,那么显然这条边 ...
- StringBuffer 和 StringBuilde
String 字符串常量StringBuffer 字符串变量(线程安全)StringBuilder 字符串变量(非线程安全) 简要的说, String 类型和 StringBuffer 类型的主要性能 ...
- Docker 开篇 1 | 树莓派中搭建Docker
官网三种安装方式,故不再赘述 大部分内容可参考官网链接:https://docs.docker.com/install/linux/docker-ce/debian/#install-docker-c ...
- unittest使用总结
unittest简介 Unittest是python内置的一个单元测试框架,主要用于自动化测试用例的开发与执行 简单的使用如下 import unittest class TestStringMeth ...
- php ffmpeg截取视频第一帧保存为图片的方法
php ffmpeg截取视频第一帧保存为图片的方法 <pre> $xiangmupath = $this->getxiangmupath(); $filename = 'chengs ...