基于Docker搭建大数据集群(六)Hive搭建
基于Docker搭建大数据集群(六)Hive搭建
前言
之前搭建的都是1.x版本,这次搭建的是hive3.1.2版本的。。还是有一点细节不一样的
Hive现在解析引擎可以选择spark,我是用spark做解析引擎的,存储还是用的HDFS
我是在docker里面搭建的集群,所以都是基于docker操作的
一、安装包准备
二、版本兼容
我使用的相关软件版本
- Hadoop ~ 2.7.7
- Spark ~ 2.4.4
- JDK ~ 1.8.0_221
- Scala ~ 2.12.9
三、环境准备
(1)解压hive压缩包
tar xivf apache-hive-3.1.2-bin -C /opt/hive/
(2)新建一个日志目录
mdkir /opt/hive/iotmp
原因
Hive启动时获取的 ${system:java.io.tmpdir} ${system:user.name}这两个变量获取绝对值有误,需要手动指定真实路径,替换其默认路径
报错截图
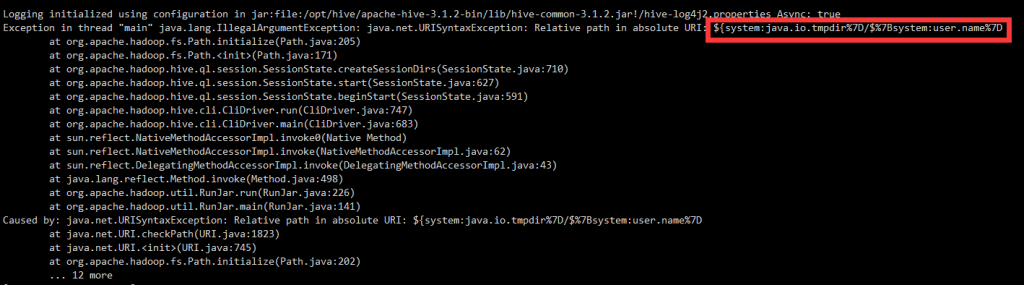
解决措施
将hive-site.xml配置里面所有相关变量全部替换掉
VI编辑器替换命令
:%s/${system:java.io.tmpdir}/\/opt\/hive\/iotmp/g
:%s/${system:user.name}/huan/g
(3)在MySQL上新建一个数据库用于存放元数据
create database hive;
(4)环境变量配置
- HIVE_OHME
- HADOOP_HOME
- SPARK_HOME
- JAVA_HOME
四、jar包
1. MySQL驱动
2. 将hive的jline包替换到hadoop的yarn下
mv /opt/hive/apache-hive-3.1.2-bin/lib/jline-2.12.jar /opt/hadoop/hadoop-2.7.7/share/hadoop/yarn/
3.将MySQL驱动放到hive的lib目录下
4.同步jar包到client节点
五、配置
我是用的是远程分布式架构,一个master提供服务,3个client远程连接master
第一步:复制或新建一个hvie-site.xml配置文件
cp hive-default.xml.template hive-site.xml
第二步:修改master节点配置文件
1. 使用mysql替换默认的derby存放元数据
<!--元数据库修改为MySQL-->
<property>
<name>hive.metastore.db.type</name>
<value>mysql</value>
<description>
Expects one of [derby, oracle, mysql, mssql, postgres].
Type of database used by the metastore. Information schema & JDBCStorageHandler depend on it.
</description>
</property>
<!--MySQL 驱动-->
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
<description>Driver class name for a JDBC metastore</description>
</property>
<!--MySQL URL-->
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://192.168.11.46:13306/hive?createDatabaseIfNotExist=true</value>
<description>
JDBC connect string for a JDBC metastore.
To use SSL to encrypt/authenticate the connection, provide database-specific SSL flag in the connection URL.
For example, jdbc:postgresql://myhost/db?ssl=true for postgres database.
</description>
</property>
<!--MySQL 用户名-->
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>root</value>
<description>Username to use against metastore database</description>
</property>
<!--MySQL 密码-->
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>root</value>
<description>password to use against metastore database</description>
<property>
2.设置解析引擎为spark
<property>
<name>hive.execution.engine</name>
<value>spark</value>
<description>
Expects one of [mr, tez, spark].
Chooses execution engine. Options are: mr (Map reduce, default), tez, spark. While MR
remains the default engine for historical reasons, it is itself a historical engine
and is deprecated in Hive 2 line. It may be removed without further warning.
</description>
</property>
3. 自动初始化元数据
<property>
<name>datanucleus.schema.autoCreateAll</name>
<value>true</value>
<description>Auto creates necessary schema on a startup if one doesn't exist. Set this to false, after creating it once.To enable auto create also set hive.metastore.schema.verification=false. Auto creation is not recommended for production use cases, run schematool command instead.
</description>
</property>
4. 关闭校验
<!--听说是JDK版本使用1.8的问题。。-->
<property>
<name>hive.metastore.schema.verification</name>
<value>false</value>
<description>
Enforce metastore schema version consistency.
True: Verify that version information stored in is compatible with one from Hive jars. Also disable automatic
schema migration attempt. Users are required to manually migrate schema after Hive upgrade which ensures
proper metastore schema migration. (Default)
False: Warn if the version information stored in metastore doesn't match with one from in Hive jars.
</description>
</property>
<property>
<name>hive.conf.validation</name>
<value>false</value>
<description>Enables type checking for registered Hive configurations</description>
</property>
5. 删除 description 中的 ,这个解析会报错
<property>
<name>hive.txn.xlock.iow</name>
<value>true</value>
<description>
Ensures commands with OVERWRITE (such as INSERT OVERWRITE) acquire Exclusive locks fortransactional tables. This ensures that inserts (w/o overwrite) running concurrently
are not hidden by the INSERT OVERWRITE.
</description>
</property>
第三步:将hive-site.xml发送到client结点
scp hive-site.xml 目的结点IP或目的结点主机名:目的主机保存目录
第四步:修改client节点的hive-site.xml
<property>
<name>hive.metastore.uris</name>
<value>thrift://cluster-master:9083</value>
<description>Thrift URI for the remote metastore. Used by metastore client to connect to remote metastore.</description>
</property>
6. 替换相对路径
:%s/${system:java.io.tmpdir}/\/opt\/hive\/iotmp/g
:%s/${system:user.name}/huan/g
六、启动
master节点
启动时会自动初始化元数据,可以查看数据库是否有表生成
./hive --service metastore &
client节点
hive
基于Docker搭建大数据集群(六)Hive搭建的更多相关文章
- 基于Docker搭建大数据集群(七)Hbase部署
基于Docker搭建大数据集群(七)Hbase搭建 一.安装包准备 Hbase官网下载 微云下载 | 在 tar 目录下 二.版本兼容 三.角色分配 节点 Master Regionserver cl ...
- 基于Docker搭建大数据集群(一)Docker环境部署
本篇文章是基于Docker搭建大数据集群系列的开篇之作 主要内容 docker搭建 docker部署CentOS 容器免密钥通信 容器保存成镜像 docker镜像发布 环境 Linux 7.6 一.D ...
- Docker搭建大数据集群 Hadoop Spark HBase Hive Zookeeper Scala
Docker搭建大数据集群 给出一个完全分布式hadoop+spark集群搭建完整文档,从环境准备(包括机器名,ip映射步骤,ssh免密,Java等)开始,包括zookeeper,hadoop,hiv ...
- 关于在真实物理机器上用cloudermanger或ambari搭建大数据集群注意事项总结、经验和感悟心得(图文详解)
写在前面的话 (1) 最近一段时间,因担任我团队实验室的大数据环境集群真实物理机器工作,至此,本人秉持负责.认真和细心的态度,先分别在虚拟机上模拟搭建ambari(基于CentOS6.5版本)和clo ...
- CDH搭建大数据集群(5.10.0)
纠结了好久,还是花钱了3个4核8G的阿里云主机,且行且珍惜,想必手动搭建过Hadoop集群的完全分布式.HBase的完全分布式的你(当然包括我,哈哈),一定会抱怨如此多的配置,而此时CDH正是解决我们 ...
- 基于Docker搭建大数据集群(二)基础组件配置
主要内容 jdk环境搭建 scala环境搭建 zookeeper部署 mysql部署 前提 docker容器之间能免密钥登录 yum源更换为阿里源 安装包 微云分享 | tar包目录下 JDK 1.8 ...
- 基于Docker搭建大数据集群(三)Hadoop部署
主要内容 Hadoop安装 前提 zookeeper正常使用 JAVA_HOME环境变量 安装包 微云下载 | tar包目录下 Hadoop 2.7.7 角色划分 角色分配 NN DN SNN clu ...
- 基于Docker搭建大数据集群(五)Mlsql部署
主要内容 mlsql部署 前提 zookeeper正常使用 spark正常使用 hadoop正常使用 安装包 微云下载 | tar包目录下 mlsql-cluster-2.4_2.11-1.4.0.t ...
- 基于Docker搭建大数据集群(四)Spark部署
主要内容 spark部署 前提 zookeeper正常使用 JAVA_HOME环境变量 HADOOP_HOME环境变量 安装包 微云下载 | tar包目录下 Spark2.4.4 一.环境准备 上传到 ...
随机推荐
- 版本管理·玩转git(快速入门git)
如果你用过Word文档写过文章,那么你一定会有这样的经历. 我觉得某一段或者某一句写得不够好,但是,删掉之后我可能会后悔把它删掉了,进而又想把删掉的段落找回来,这时,你想到了一个好办法,将每次的修改都 ...
- CENTOS服务器基础教程-U盘系统盘制作
什么都要用到一点点,会一点点,现在的USB3.0基本上服务器都已经支持.小编给大家介绍基础篇:如何使用U盘制作系统安装盘 工具/原料 U盘 UltraISO工具 方法/步骤 准备一个U ...
- Scratch 3下载,最新版Scratch下载,macOS、Windows版
下载地址:https://scratch.mit.edu/download 废话不多说,先上下载地址! 之前小弟学习Scratch,用的2.0发现诸多BUG,到度娘想下最新版却没有发现一篇比较正经的文 ...
- d3.js 教程 模仿echarts柱状图
由于最近工作不是很忙,隧由把之前的charts项目用d3.js重写的一下,其实d3.js文档很多,但是入门不是很难,可是想真的能做一个完成的,交互良好的图还是要下一番功夫的.今天在echarts找到了 ...
- 交完论文才发现spss数据分析做错了
上周,终于把毕业论文交给导师了.然而,今天导师却邮件我,叫我到他办公室谈谈.具体是谈什么呢?我百思不得其解:对论文几次大修小修后,重复率已经低于学校的上限了,论文结构也很完整,我已经在做答辩的ppt了 ...
- HDU-3478Catch二分图的否命题
HDU-3478Catch 题意:考虑Thief能否: 由于我推着推着就想到必须要三点可以互通,和二分图的结论正好相反,所以就试了一发, 真没想到thief的初始位置是不用考虑的. 下面是ac代码: ...
- hdu 3065病毒侵袭持续中(ac自动机)
题目链接 http://acm.hdu.edu.cn/showproblem.php?pid=3065 中文题题意不解释了. 依旧稍微改一下ac自动机模版就能过了.还有一个坑点!是多组数据!!! #i ...
- poj 1417 True Liars(并查集+背包dp)
题目链接:http://poj.org/problem?id=1417 题意:就是给出n个问题有p1个好人,p2个坏人,问x,y是否是同类人,坏人只会说谎话,好人只会说实话. 最后问能否得出全部的好人 ...
- 深入分析Mybatis 使用useGeneratedKeys获取自增主键
摘要 我们经常使用useGenerateKeys来返回自增主键,避免多一次查询.也会经常使用on duplicate key update,来进行insertOrUpdate,来避免先query 在i ...
- C++中的Inline函数的使用
转载自:https://www.cnblogs.com/KellyHuang/p/4001470.html 在大多数机器上,函数调用does a lot of work:在调用函数前保存寄存器,调用结 ...