Hadoop核心组件之HDFS
HDFS:分布式文件系统
一句话总结
一个文件先被拆分为多个Block块(会有Block-ID:方便读取数据),以及每个Block是有几个副本的形式存储
1个文件会被拆分成多个Block
blocksize:128M(Hadoop2.0以后默认的块大小,可以自定义配置)
130M ==> 2个Block: 128M 和 2M
HDFS设计目标
- 巨大的分布式文件系统
- 满足大数据场景基本数据存储的要求
- 廉价的机器上
- 当你的存储空间不够,你可以水平横向扩展机器方式提高
HDFS架构
NameNode + N个DataNode
典型的主从架构,即:
1 Master(NameNode/NN) 带 N个Slaves(DataNode/DN)
建议:NN和DN是部署在不同的节点上
PS:
常见的主从架构还有:HDFS/YARN/HBase
主从架构一个难题就是:如何保证HA的问题,很多时候会使用Zookeeper来配置使用
NameNode/NN:主节点Master
1)负责客户端请求的响应
2)负责元数据(文件的名称、副本系数、Block存放的DN)的管理
DataNode/DN:从节点Slaves
1)存储用户的文件对应的数据块(Block)
2)要定期向NN发送心跳信息,汇报本身及其所有的block信息,健康状况
HDFS副本机制
replication factor:副本系数、副本因子
一个大的文件会被拆分为许多块,最终以多副本的方式存储在多个节点上
一个文件,除了最后一个,其余所有块的大小都是一致的
问题:那么如何为每个Block选择存储在哪些节点上呢?
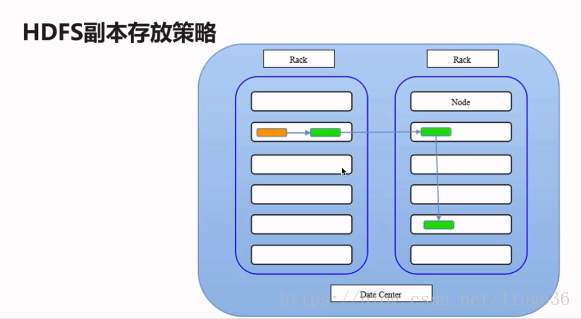
Rack代表的是机架:一般三份副本分别是这样存储的
第一份副本:存储在当前提交存储的机架中当前节点上
第二份副本:存储在非当前机架上的某一节点上
第三份副本:和第二副本统一机架的不同节点之上
建议:生产只能够,起码划分两个及其以上的机架
HDFS Shell
Usage: hdfs dfs [COMMAND [COMMAND_OPTIONS]]
hadoop fs -ls / 等价 hdfs dfs -ls /
[root@hadoop000 data]# ls
hadoop-tmp hello.txt
上传:
[root@hadoop000 data]# hadoop fs -put hello.txt /
下载:
[root@hadoop000 data]# hadoop fs -get /test/a/b/h.txt
查看内容:
[root@hadoop000 data]# hadoop fs -text /hello.txt
[root@hadoop000 data]# hadoop fs -cat /hello.txt
建立目录;
[root@hadoop000 data]# hadoop fs -mkdir /test
创建递归的目录
[root@hadoop000 data]# hadoop fs -mkdir -p /test/a/b
递归展示目录文件:
[root@hadoop000 data]# hadoop fs -ls -R /
本地拷贝到hdfs:
[root@hadoop000 data]# hadoop fs -copyFromLocal hello.txt /test/a/b/h.txt
删除文件:
[root@hadoop000 data]# hadoop fs -rm /hello.txt
递归删除文件夹:
[root@hadoop000 data]# hadoop fs -rm -R /test
HSFS的读写流程,工作原理(面试)
漫画图解
https://blog.csdn.net/eric_sunah/article/details/41546863
Client:客户端,通过HDFS Shell或Java API发起读写请求
1个NameNode:全局把控
N 个DataNode: 数据存储
写数据流程:
1.客户端把文件拆分为多个Block
2.NameNode:提供刚才拆分出来的Block块的具体datanode存储位置
3.DataNode:存储Block块的数据,把3个副本数据写完
读数据流程:
1.用户提供文件名就可以给客户端
2.客户端发起请求给NameNode
3.NameNode就会告诉客户端具体的存储位置和块
4.发起最近距离节点请求给DataNode下载数据
HDFS的优缺点
优点:
数据冗余,硬件容错
一次写入,多次读取数据
适合存储大文件
构建在廉价机器上
缺点:
延时性高
不适合小文件存储
Hadoop核心组件之HDFS的更多相关文章
- hadoop核心组件概述及hadoop集群的搭建
什么是hadoop? Hadoop 是 Apache 旗下的一个用 java 语言实现开源软件框架,是一个开发和运行处理大规模数据的软件平台.允许使用简单的编程模型在大量计算机集群上对大型数据集进行分 ...
- 对Hadoop分布式文件系统HDFS的操作实践
原文地址:https://dblab.xmu.edu.cn/blog/290-2/ Hadoop分布式文件系统(Hadoop Distributed File System,HDFS)是Hadoop核 ...
- Hadoop学习笔记—HDFS
目录 搭建安装 三个核心组件 安装 配置环境变量 配置各上述三组件守护进程的相关属性 启停 监控和性能 Hadoop Rack Awareness yarn的NodeManagers监控 命令 hdf ...
- Hadoop官方文档翻译——HDFS Architecture 2.7.3
HDFS Architecture HDFS Architecture(HDFS 架构) Introduction(简介) Assumptions and Goals(假设和目标) Hardware ...
- hadoop 2.5 hdfs namenode –format 出错Usage: java NameNode [-backup] |
在 cd /home/hadoop/hadoop-2.5.2/bin 下 执行的./hdfs namenode -format 报错[hadoop@node1 bin]$ ./hdfs nameno ...
- Hadoop 分布式文件系统 - HDFS
当数据集超过一个单独的物理计算机的存储能力时,便有必要将它分不到多个独立的计算机上.管理着跨计算机网络存储的文件系统称为分布式文件系统.Hadoop 的分布式文件系统称为 HDFS,它 是为 以流式数 ...
- Hadoop 2.x HDFS新特性
Hadoop 2.x HDFS新特性 1.HDFS联邦 2. HDFS HA(要用到zookeeper等,留在后面再讲) 3.HDFS快照 回顾: HDFS两层模型 Namespa ...
- 何时使用hadoop fs、hadoop dfs与hdfs dfs命令(转)
hadoop fs:使用面最广,可以操作任何文件系统. hadoop dfs与hdfs dfs:只能操作HDFS文件系统相关(包括与Local FS间的操作),前者已经Deprecated,一般使用后 ...
- 何时使用hadoop fs、hadoop dfs与hdfs dfs命令
hadoop fs:使用面最广,可以操作任何文件系统. hadoop dfs与hdfs dfs:只能操作HDFS文件系统相关(包括与Local FS间的操作),前者已经Deprecated,一般使用后 ...
随机推荐
- wcf项目跨域问题处理
最近做了一个wcf项目,请求发起的项目是一个webform项目,所以这是分开的两个项目端口必然不一样,理所当然存在跨域问题. 有的人当下就反应过来jsonp,jsonp只能用于get请求,对于参数比较 ...
- 分布式配置中心Apollo——QuickStart
分布式配置中心 剥离配置文件,实现动态修改,自动更新. [假设没有分布式配置中心,修改配置文件后都需要重启服务,对于数量庞多的微服务开发来说,就会非常繁琐] 分布式配置中心有哪些 disconf(依赖 ...
- java程序员学习路线阶段总结20190903
算法:锻炼写代码的逻辑 刷题位置:leetcode 书籍:小灰漫画算法 leecode使用方法: 转载自http://blog.csdn.net/tostq 又到了一年毕业就业季了,三年前的校招季我逃 ...
- SDU暑期集训排位(2)
A. Art solved by sdcgvhgj 3min 签到 B. Biology solved by sdcgvhgj 85min 暴力 C - Computer Science solved ...
- 分析一次double强转float的翻车原因
背景 人逢喜事精神爽,总算熬到下班撩~~ 正准备和同事打个招呼回家,被同事拖住问了.
- Java SPI详解
1.什么是SPI SPI全称Service Provider Interface,是Java提供的一套用来被第三方实现或者扩展的接口,它可以用来启用框架扩展和替换组件. SPI的作用就是为这些被扩展的 ...
- 设置普通用户输入sudo,免密进入root账户
满足给开发用户开权限,赋予sudo权限.又不让其输入密码的方式: 方式一: 开始系统内部的wheel用户组, 在/etc/suoers 中编辑配置文件如下: %wheel ALL=(ALL) NOPA ...
- zabbix -- 学习之一
网上说这东西是运维必须学会的东西,于是乎捣鼓的第一步就开始了. 首先,在度娘上搜索了一下,找到了官网,按照官网的说法没操作成功.后来照这博主的帖子(https://www.cnblogs.com/xi ...
- Java中String为什么是不可变的
1.在Java中,String类是不可变类,一个不可变类是一个简单的类,并且这个的实例也不能被修改, 这个类的实例创建的时候初始化所有的信息,并且这些信息不能够被修改 2.字符串常量池 字符串常量池是 ...
- 新书推荐《再也不踩坑的Kubernetes实战指南》
<再也不踩坑的Kubernetes实战指南>终于出版啦.目前可以在京东.天猫购买,京东自营和当当网预计一个星期左右上架. 本书贴合生产环境经验,解决在初次使用或者是构建集群中的痛点,帮 ...