一种Cortex-M内核中的精确延时方法
本文介绍一种Cortex-M内核中的精确延时方法
前言
为什么要学习这种延时的方法?
- 很多时候我们跑操作系统,就一般会占用一个硬件定时器——SysTick,而我们一般操作系统的时钟节拍一般是设置100-1000HZ,也就是1ms——10ms产生一次中断。很多裸机教程使用延时函数又是基于SysTick的,这样一来又难免产生冲突。
- 很多人会说,不是还有定时器吗,定时器的计时是超级精确的。这点我不否认,但是假设,如果一个系统,总是进入定时器中断(10us一次/1us一次/0.5us一次),那整个系统就会经常被打断,线程的进行就没办法很好运行啊。此外还消耗一个硬件定时器资源,一个硬件定时器可能做其他事情呢!
- 对应ST HAL库的修改,其实杰杰个人觉得吧,ST的东西什么都好,就是出的HAL库太恶心了,没办法,而HAL库中有一个HAL_Delay(),他也是采用SysTick延时的,在移植操作系统的时候,会有诸多不便,不过好在,HAL_Delay()是一个弱定义的,我们可以重写这个函数的实现,那么,采用内核延时当然是最好的办法啦(个人是这么觉得的)当然你有能力完全用for循环写个简单的延时还是可以的。
- 可能我说的话没啥权威,那我就引用Cortex-M3权威指南中的一句话——“DWT 中有剩余的计数器,它们典型地用于程序代码的“性能速写”(profiling)。通过编程它们,就可以让它们在计数器溢出时发出事件(以跟踪数据包的形式)。最典型地,就是使用 CYCCNT寄存器来测量执行某个任务所花的周期数,这也可以用作时间基准相关的目的(操作系统中统计 CPU使用率可以用到它)。”
Cortex-M中的DWT
在Cortex-M里面有一个外设叫DWT(Data Watchpoint and Trace),是用于系统调试及跟踪,
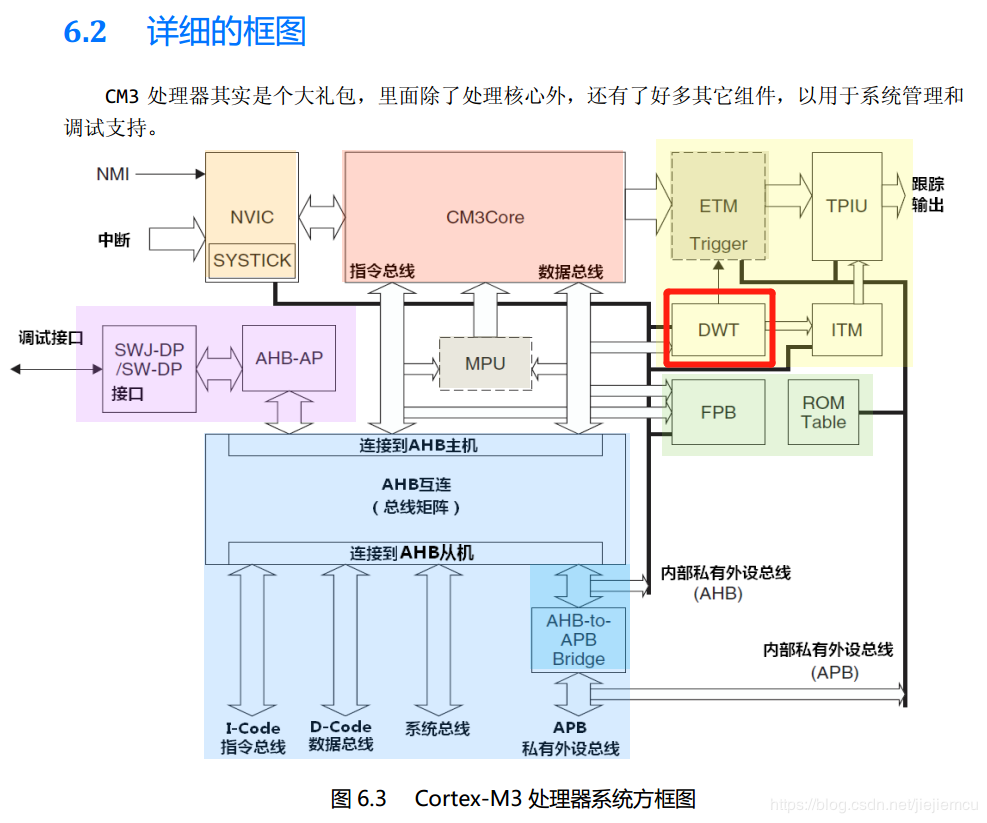 它有一个32位的寄存器叫CYCCNT,它是一个向上的计数器,记录的是内核时钟运行的个数,内核时钟跳动一次,该计数器就加1,精度非常高,决定内核的频率是多少,如果是F103系列,内核时钟是72M,那精度就是1/72M = 14ns,而程序的运行时间都是微秒级别的,所以14ns的精度是远远够的。最长能记录的时间为:60s=2的32次方/72000000(假设内核频率为72M,内核跳一次的时间大概为1/72M=14ns),而如果是H7这种400M主频的芯片,那它的计时精度高达2.5ns(1/400000000 = 2.5),而如果是 i.MX RT1052这种比较牛逼的处理器,最长能记录的时间为: 8.13s=2的32次方/528000000 (假设内核频率为528M,内核跳一次的时间大概为1/528M=1.9ns) 。当CYCCNT溢出之后,会清0重新开始向上计数。
它有一个32位的寄存器叫CYCCNT,它是一个向上的计数器,记录的是内核时钟运行的个数,内核时钟跳动一次,该计数器就加1,精度非常高,决定内核的频率是多少,如果是F103系列,内核时钟是72M,那精度就是1/72M = 14ns,而程序的运行时间都是微秒级别的,所以14ns的精度是远远够的。最长能记录的时间为:60s=2的32次方/72000000(假设内核频率为72M,内核跳一次的时间大概为1/72M=14ns),而如果是H7这种400M主频的芯片,那它的计时精度高达2.5ns(1/400000000 = 2.5),而如果是 i.MX RT1052这种比较牛逼的处理器,最长能记录的时间为: 8.13s=2的32次方/528000000 (假设内核频率为528M,内核跳一次的时间大概为1/528M=1.9ns) 。当CYCCNT溢出之后,会清0重新开始向上计数。

m3、m4、m7杰杰实测可用(m0不可用)。
精度:1/内核频率(s)。
要实现延时的功能,总共涉及到三个寄存器:DEMCR 、DWT_CTRL、DWT_CYCCNT,分别用于开启DWT功能、开启CYCCNT及获得系统时钟计数值。
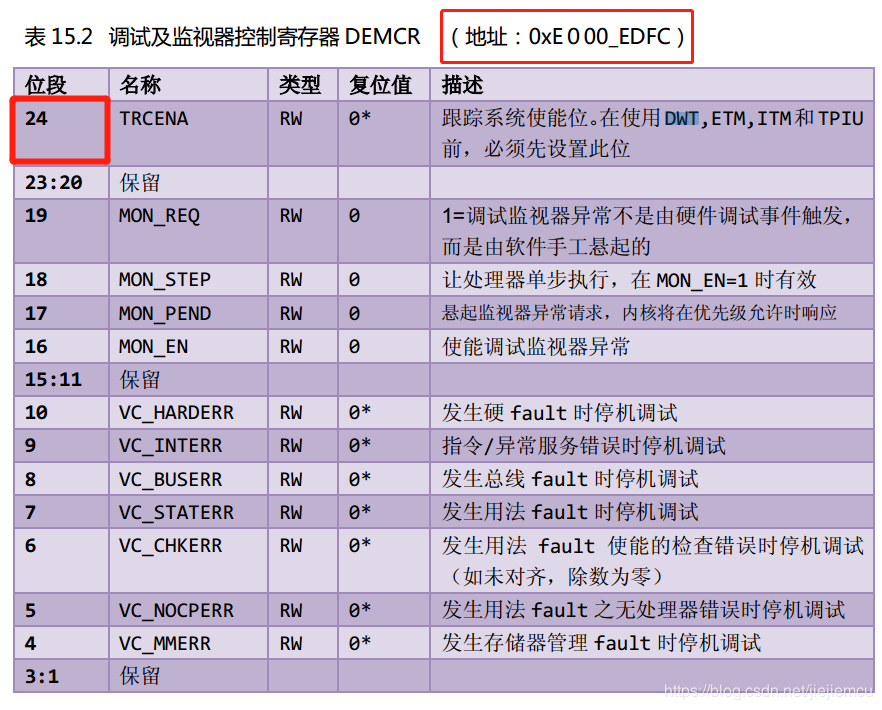
DEMCR
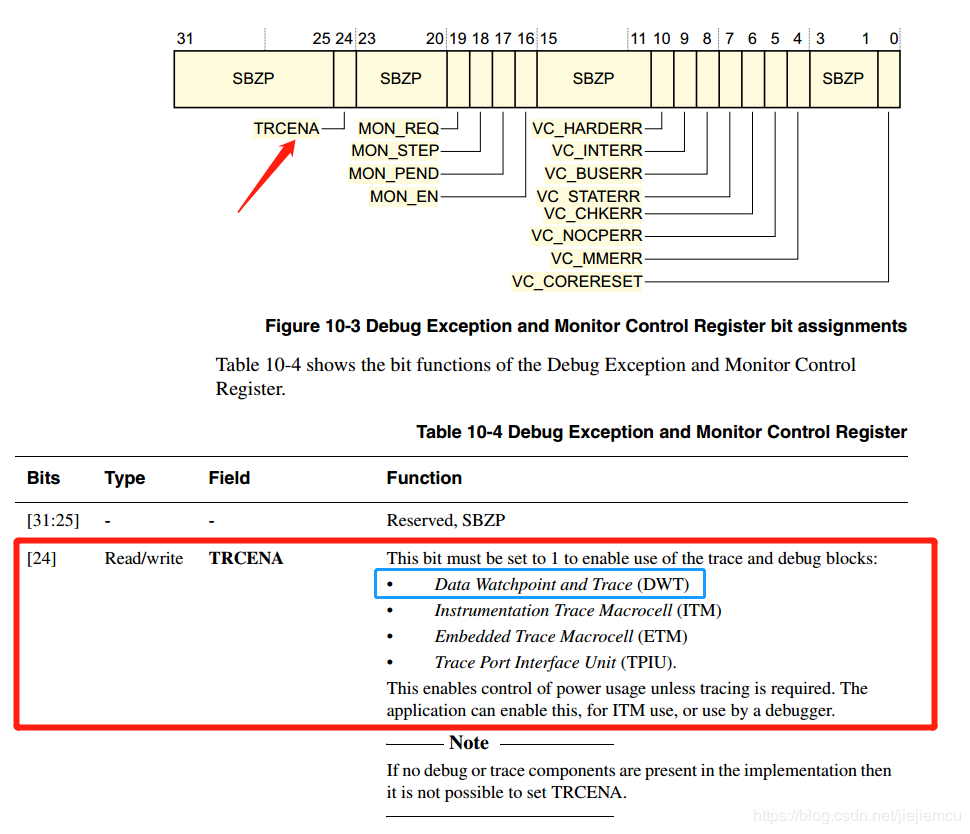
想要使能DWT外设,需要由另外的内核调试寄存器DEMCR的位24控制,写1使能(划重点啦,要考试!!)。
DEMCR的地址是0xE000 EDFC
关于DWT_CYCCNT
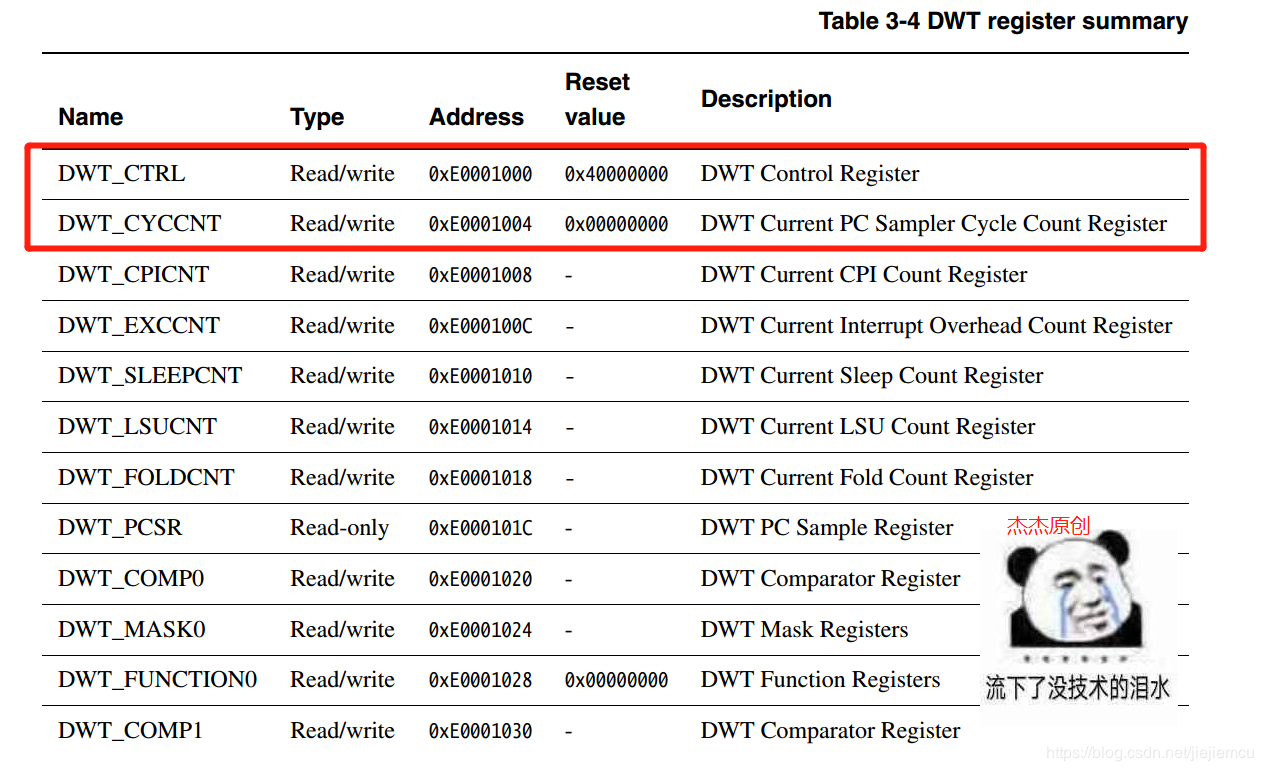
使能DWT_CYCCNT寄存器之前,先清0。
让我们看看DWT_CYCCNT的基地址,从ARM-Cortex-M手册中可以看到其基地址是0xE000 1004,复位默认值是0,而且它的类型是可读可写的,我们往0xE000 1004这个地址写0就将DWT_CYCCNT清0了。
关于CYCCNTENA
CYCCNTENA Enable the CYCCNT counter. If not enabled, the counter does not count and no event is
generated for PS sampling or CYCCNTENA. In normal use, the debugger must initialize
the CYCCNT counter to 0.
它是DWT控制寄存器的第一位,写1使能,则启用CYCCNT计数器,否则CYCCNT计数器将不会工作。

综上所述
想要使用DWT的CYCCNT步骤:
- 先使能DWT外设,这个由另外内核调试寄存器DEMCR的位24控制,写1使能
- 使能CYCCNT寄存器之前,先清0。
- 使能CYCCNT寄存器,这个由DWT的CYCCNTENA 控制,也就是DWT控制寄存器的位0控制,写1使能
代码实现
/**
******************************************************************
* @file core_delay.c
* @author fire
* @version V1.0
* @date 2018-xx-xx
* @brief 使用内核寄存器精确延时
******************************************************************
* @attention
*
* 实验平台:野火 STM32开发板
* 论坛 :http://www.firebbs.cn
* 淘宝 :https://fire-stm32.taobao.com
*
******************************************************************
*/
#include "./delay/core_delay.h"
/*
**********************************************************************
* 时间戳相关寄存器定义
**********************************************************************
*/
/*
在Cortex-M里面有一个外设叫DWT(Data Watchpoint and Trace),
该外设有一个32位的寄存器叫CYCCNT,它是一个向上的计数器,
记录的是内核时钟运行的个数,最长能记录的时间为:
10.74s=2的32次方/400000000
(假设内核频率为400M,内核跳一次的时间大概为1/400M=2.5ns)
当CYCCNT溢出之后,会清0重新开始向上计数。
使能CYCCNT计数的操作步骤:
1、先使能DWT外设,这个由另外内核调试寄存器DEMCR的位24控制,写1使能
2、使能CYCCNT寄存器之前,先清0
3、使能CYCCNT寄存器,这个由DWT_CTRL(代码上宏定义为DWT_CR)的位0控制,写1使能
*/
#define DWT_CR *(__IO uint32_t *)0xE0001000
#define DWT_CYCCNT *(__IO uint32_t *)0xE0001004
#define DEM_CR *(__IO uint32_t *)0xE000EDFC
#define DEM_CR_TRCENA (1 << 24)
#define DWT_CR_CYCCNTENA (1 << 0)
/**
* @brief 初始化时间戳
* @param 无
* @retval 无
* @note 使用延时函数前,必须调用本函数
*/
HAL_StatusTypeDef HAL_InitTick(uint32_t TickPriority)
{
/* 使能DWT外设 */
DEM_CR |= (uint32_t)DEM_CR_TRCENA;
/* DWT CYCCNT寄存器计数清0 */
DWT_CYCCNT = (uint32_t)0u;
/* 使能Cortex-M DWT CYCCNT寄存器 */
DWT_CR |= (uint32_t)DWT_CR_CYCCNTENA;
return HAL_OK;
}
/**
* @brief 读取当前时间戳
* @param 无
* @retval 当前时间戳,即DWT_CYCCNT寄存器的值
*/
uint32_t CPU_TS_TmrRd(void)
{
return ((uint32_t)DWT_CYCCNT);
}
/**
* @brief 读取当前时间戳
* @param 无
* @retval 当前时间戳,即DWT_CYCCNT寄存器的值
*/
uint32_t HAL_GetTick(void)
{
return ((uint32_t)DWT_CYCCNT/SysClockFreq*1000);
}
/**
* @brief 采用CPU的内部计数实现精确延时,32位计数器
* @param us : 延迟长度,单位1 us
* @retval 无
* @note 使用本函数前必须先调用CPU_TS_TmrInit函数使能计数器,
或使能宏CPU_TS_INIT_IN_DELAY_FUNCTION
最大延时值为8秒,即8*1000*1000
*/
void CPU_TS_Tmr_Delay_US(uint32_t us)
{
uint32_t ticks;
uint32_t told,tnow,tcnt=0;
/* 在函数内部初始化时间戳寄存器, */
#if (CPU_TS_INIT_IN_DELAY_FUNCTION)
/* 初始化时间戳并清零 */
HAL_InitTick(5);
#endif
ticks = us * (GET_CPU_ClkFreq() / 1000000); /* 需要的节拍数 */
tcnt = 0;
told = (uint32_t)CPU_TS_TmrRd(); /* 刚进入时的计数器值 */
while(1)
{
tnow = (uint32_t)CPU_TS_TmrRd();
if(tnow != told)
{
/* 32位计数器是递增计数器 */
if(tnow > told)
{
tcnt += tnow - told;
}
/* 重新装载 */
else
{
tcnt += UINT32_MAX - told + tnow;
}
told = tnow;
/*时间超过/等于要延迟的时间,则退出 */
if(tcnt >= ticks)break;
}
}
}
/*********************************************END OF FILE**********************/
#ifndef __CORE_DELAY_H
#define __CORE_DELAY_H
#include "stm32h7xx.h"
/* 获取内核时钟频率 */
#define GET_CPU_ClkFreq() HAL_RCC_GetSysClockFreq()
#define SysClockFreq (218000000)
/* 为方便使用,在延时函数内部调用CPU_TS_TmrInit函数初始化时间戳寄存器,
这样每次调用函数都会初始化一遍。
把本宏值设置为0,然后在main函数刚运行时调用CPU_TS_TmrInit可避免每次都初始化 */
#define CPU_TS_INIT_IN_DELAY_FUNCTION 0
/*******************************************************************************
* 函数声明
******************************************************************************/
uint32_t CPU_TS_TmrRd(void);
HAL_StatusTypeDef HAL_InitTick(uint32_t TickPriority);
//使用以下函数前必须先调用CPU_TS_TmrInit函数使能计数器,或使能宏CPU_TS_INIT_IN_DELAY_FUNCTION
//最大延时值为8秒
void CPU_TS_Tmr_Delay_US(uint32_t us);
#define HAL_Delay(ms) CPU_TS_Tmr_Delay_US(ms*1000)
#define CPU_TS_Tmr_Delay_S(s) CPU_TS_Tmr_Delay_MS(s*1000)
#endif /* __CORE_DELAY_H */
注意事项:
使用者如果不是在HAL库中使用,注释掉:
uint32_t HAL_GetTick(void)
{
return ((uint32_t)DWT_CYCCNT/SysClockFreq*1000);
}
同时建议重新命名HAL_InitTick()函数。
按照自己的平台重写以下宏定义:
/* 获取内核时钟频率 */
#define GET_CPU_ClkFreq() HAL_RCC_GetSysClockFreq()
#define SysClockFreq (218000000)
后记
其实在ucos-iii 源码中,有一个功能是测量关中断时间的功能,就是使用STM32的时间戳,即记录程序运行的某个时刻,如果记录下程序前后的两个时刻点,即可以算出这段程序的运行时间。
但是有关内核寄存器的描述的资料非常少,还好找到一个(arm手册),里面有这些内核寄存器的详细描述,其中时间戳相关的寄存器在第10章和11章有详细的描述。关于资料想看的可以后台找我拿。
喜欢就关注我吧!

相关代码可以在公众号后台回复 “ DWT ”获取。
更多资料欢迎关注“物联网IoT开发”公众号!
一种Cortex-M内核中的精确延时方法的更多相关文章
- Keil C51程序设计中几种精确延时方法
1 使用定时器/计数器实现精确延时 单片机系统一般常选用11.059 2 MHz.12 MHz或6 MHz晶振.第一种更容易产生各种标准的波特率,后两种的一个机器周期分别为1 μs和2 μs,便于精确 ...
- 在bat批处理中简单的延时方法
使用for命令: 延时1s左右的方法: @echo off echo %time% ,,) do echo %%i>nul echo %time% pause %time%是用来显示延时时间,实 ...
- Linux2.6 内核中结构体初始化(转载)
转自:http://hnniyan123.blog.chinaunix.net/uid-29917301-id-4989879.html 在Linux2.6版本的内核中,我们经常可以看到下面的结构体的 ...
- Delphi中的异常处理(10种异常来源、处理、精确处理)
一.异常的来源 在Delphi应用程序中,下列的情况都比较有可能产生异常. 1.文件处理 2.内存分配 3.windows资源 4.运行时创建对象和窗体 5.硬件和操作系统冲突 6.网络问题 7.数据 ...
- Linux内核中的GPIO系统之(3):pin controller driver代码分析
一.前言 对于一个嵌入式软件工程师,我们的软件模块经常和硬件打交道,pin control subsystem也不例外,被它驱动的硬件叫做pin controller(一般ARM soc的datash ...
- 调皮的程序员:Linux之父雕刻在Linux内核中的故事
本文内容由公众号“格友”原创分享. 1.引言 (不羁的大神,连竖中指都这么帅) 因为LINUX操作系统的流行,Linus 已经成为地球人都知道的名人.虽然大家可能都听过钱钟书先生的名言:“假如你吃 ...
- 进程在Linux内核中的角色扮演
在Linux内核中,内核将进程.线程和内核线程一视同仁,即内核使用唯一的数据结构task_struct来分别表示他们:内核使用相同的调度算法对这三者进行调度:并且内核也使用同一个函数do_fork() ...
- Linux内核中的jiffies及其作用介绍及jiffies等相关函数详解
在LINUX的时钟中断中涉及至二个全局变量一个是xtime,它是timeval数据结构变量,另一个则是jiffies,首先看timeval结构struct timeval{time_t tv_sec; ...
- Linux内核中的GPIO系统之(3):pin controller driver代码分析--devm_kzalloc使用【转】
转自:http://www.wowotech.net/linux_kenrel/pin-controller-driver.html 一.前言 对于一个嵌入式软件工程师,我们的软件模块经常和硬件打交道 ...
随机推荐
- 封装axios来管控api的2种方式
前言:我们在开发项目的时候,往往要处理大量的接口.并且在测试环境 开发环境 生产环境使用的接口baseurl都不一样 这时候如果在开发环境完成之后切换每一个接口的baseurl会变的非常的麻烦,(要去 ...
- Spring Cloud(一):服务注册与发现
Spring Cloud是什么 Spring Cloud是一系列框架的有序集合.它利用Spring Boot的开发便利性巧妙地简化了分布式系统基础设施的开发,如服务发现注册.配置中心.消息总线.负载均 ...
- 为什么说 Java 程序员必须掌握 Spring Boot ?(转)
Spring Boot 2.0 的推出又激起了一阵学习 Spring Boot 热,那么, Spring Boot 诞生的背景是什么?Spring 企业又是基于什么样的考虑创建 Spring Boot ...
- Docker详解(二)
目录 1.Docker常用命令 1.1 镜像命令 1.2 容器命令 1.2.1 常用的容器命令 1.2.2 重要的容器命令 序言:上一章我们初步介绍了一下Docker的概念,那么这次我们着手于Dock ...
- BASK、BFSK、BPSK调制方法的Matlab程序实现
%以下为手动编程方法,也可调用matlab集成函数dmod,具体调制方式见doc. n = [0:0.01:5.99]; x1 = ones(1,100); x2 = zeros(1,100); x3 ...
- Eclipse For Mac下中文乱码解决
在Mac os 版本的eclipse下引入java项目或是源代码,经常会碰到其中中文部分都是乱码.对于这一问题,经过小试,可以解决. 1.打开eclipse 偏好设置 2.General ——> ...
- SoloLear_C# Tutorial_Contents
一.Basic Concepts 基本概念 二.Conditionals and Loops 条件语句和循环 三.Methods 方法 四.Classes&Objects 类&对象 五 ...
- opencv中IplImage* src = cvLoadImage,错误
在调试这段代码时 IplImage* src = cvLoadImage("D:\\图像\\已处理 - 11.26\\1.jpg", 1); 提示一下错误 引发了异常: 读取访问权 ...
- python自增自减?赋值语句返回值?逗号表达式?
咳咳,直接进入正题吧. 自增自减(++/--),以及赋值语句,还有逗号表达式都是在C/C++中常见的运算符或表达式. 熟悉C/C++的小伙伴们都知道,在C/C++中: 自增自减(前缀/后缀)运算符将实 ...
- Hadoop 之 Hadoop2.0
1.Hadoop2.0与1.0 答:Hadoop2.0之后的版本移除了原有的JobTracker和TaskTracker,改由Yarn平台的ResourceManager负责集群中所有资源的管理和分配 ...