springcloud-eureka高可用集群搭建
一 前言
eureka作为注册中心,其充当着服务注册与发现功能,加载负载均衡;若在项目运行中eureka挂了,那么整个服务整体都会暂停,所以为服务运行的安全性,有必要搭建eureka集群;当其中一个eureka节点挂了,我们还有另外的节点可用;本篇文章的核心是如何在idea上运行eureka集群,和项目部署;需注意的jdk版本是1.8,高于jdk1.8打包部署会出问题,需要引入其他依赖;
二 eureka-server配置文件改造
之前的配置文件如下,这是单个eureka-server的配置,并不能满足于我们实际项目需求,我们要将其改造成高可用的集群节点模式;
server:
port: 10086
eureka:
instance:
hostname: localhost
client:
# 作为server,表示禁止向自己注册
register-with-eureka: false
fetch-registry: false
service-url:
defaultZone: http://${eureka.instance.hostname}:${server.port}/eureka/
改造配置文件如下,之前的文章中我们了解了eureka的peer to peer 交流机制,我们现在就根据这个原理搭建高可用的eureka集群,在配置文件中可以看见知识追寻者配置了3个peer(peer1,peer2,peer3); 它们的端口分别是10081,10082,10083; peer1,分别向 peer2,peer3注册,peer2则向 peer1,peer3注册,peer3同理;这样就构成了eureka简单的3个节点集群;
spring:
application:
name: eureka-server-cluster
---
spring:
profiles: peer1
server:
port: 10081
eureka:
instance:
hostname: peer1
client:
service-url:
# 向peer2 peer3节点注册自己
defaultZone: http://peer2:10082/eureka,http://peer3:10083/eureka
---
spring:
profiles: peer2
server:
port: 10082
eureka:
instance:
hostname: peer2
client:
service-url:
# 向peer1 pee3节点注册自己
defaultZone: http://peer1:10081/eureka,http://peer3:10083/eureka
---
spring:
profiles: peer3
server:
port: 10083
eureka:
instance:
hostname: peer3
client:
service-url:
# 向peer1 peer2节点注册自己
defaultZone: http://peer1:10081/eureka,http://peer2:10082/eureka
三 eureka-client配置文件改造
在之前的基础上多添加了注册server节点 peer2,peer3
server:
port: 8090
spring:
application:
name: eureka-client # 应用名称
eureka:
client:
service-url:
# 服务注册地址
defaultZone: http://peer1:10081/eureka/,http://peer2:10082/eureka/,http://peer3:10083/eureka/
四 host文件修改
修改host文件目的是peer对应ip地址,实际项目中 每个peer节点都是一个ip地址;
192.168.0.101 peer1
192.168.0.101 peer2
192.168.0.101 peer3
五 复制启动配置
复制配置如下:点击 cpoy configuration 选项;
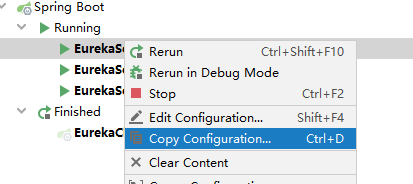
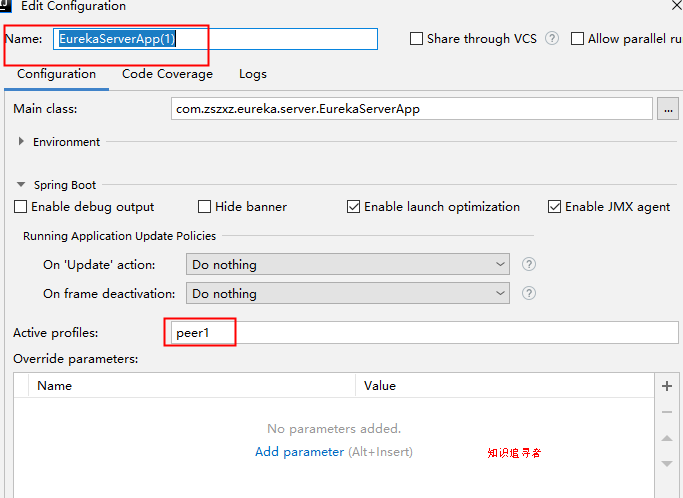
进入编辑状态,修改 name 为 EurekaServer(1), 激活的配置文件选项 填 peer1;以此类推,我们复制三个实例; 分别是 EurekaServer(1),EurekaServer(2),EurekaServer(3);分别激活配置 peer2,peer2,peer3;
六 启动 eureka-server
分别启动三个配置实例,图如下;
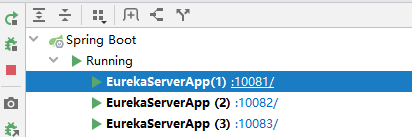
浏览器输入 http://localhost:10083/ 或者 http://localhost:10082/ 或者 http://localhost:10081/;结果如下,知识追寻者在浏览器输入的 peer3地址,那么 对应的复制的Node 是 peer2,peer1;server有三个;

七 启动 eureka-client
启动eureka client 图如下
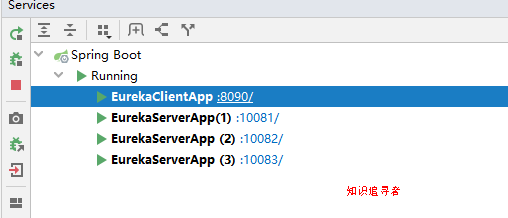
刷新浏览器界面,可以看见 client 已经注册到 server;
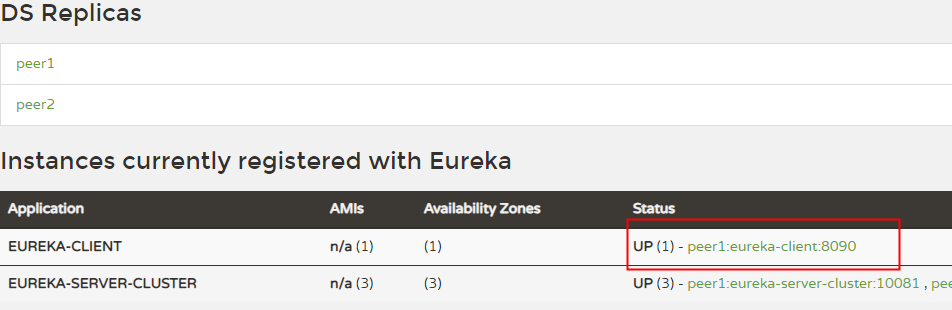
八 打包部署
进入 eureka-server 工程目录 执行 打包命令 mvn clean package
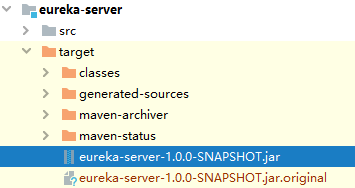
打开三个命令行分别执行对应的命令,一个cmd一条;
java -jar eureka-server-1.0.0-SNAPSHOT.jar --spring.profiles.active=peer1
java -jar eureka-server-1.0.0-SNAPSHOT.jar --spring.profiles.active=peer2
java -jar eureka-server-1.0.0-SNAPSHOT.jar --spring.profiles.active=peer3
pee3 如下
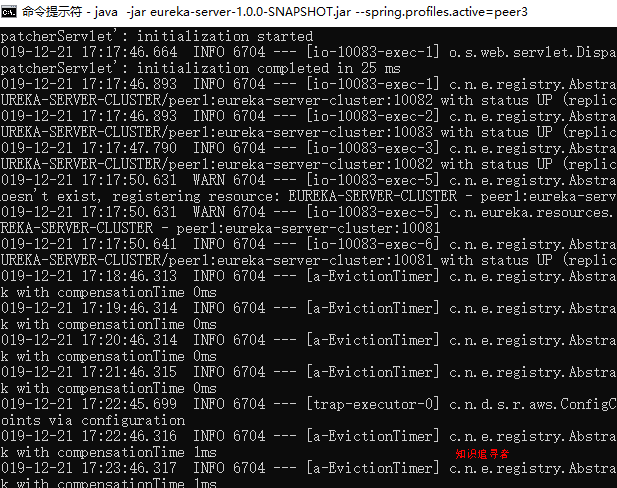
浏览器页面如下:

九 多 profile运行注意事项
如下 配置文件 不写在src/main/resources一个 application 中,而是分为 application-peer1.yml, application-peer2.yml, application-peer3.yml ; 在 idea 的虚拟机参数(VM Options)配置 是
-Dspring.profiles.active=peer1 , -Dspring.profiles.active=peer2 ,-Dspring.profiles.active=peer3;部署方式相同;也可以通过 mvn spring-boot:run -Dspring.profiles.active=peer1 的形式运行;

springcloud-eureka高可用集群搭建的更多相关文章
- spring cloud 服务注册中心eureka高可用集群搭建
spring cloud 服务注册中心eureka高可用集群搭建 一,准备工作 eureka可以类比zookeeper,本文用三台机器搭建集群,也就是说要启动三个eureka注册中心 1 本文三台eu ...
- SpringCloud全家桶学习之服务注册与发现及Eureka高可用集群搭建(二)
一.Eureka服务注册与发现 (1)Eureka是什么? Eureka是NetFlix的一个子模块,也是核心模块之一.Eureka是一个基于REST的服务,用于定位服务,以实现云端中间层服务发现和故 ...
- SpringCloud(四):服务注册中心Eureka Eureka高可用集群搭建 Eureka自我保护机制
第四章:服务注册中心 Eureka 4-1. Eureka 注册中心高可用集群概述在微服务架构的这种分布式系统中,我们要充分考虑各个微服务组件的高可用性 问题,不能有单点故障,由于注册中心 eurek ...
- 服务注册组件——Eureka高可用集群搭建
服务注册组件--Eureka高可用集群搭建 什么是Eureka? 服务注册组件:将微服务注册到Eureka中. 为什么需要服务注册? 微服务开发重点在一个"微"字,大型应用拆分成微 ...
- Eureka高可用集群搭建
就是搭建Eureka的集群. 每个Eureka Server需要相互注册,确保数据一致. 我这里准备两个Eureka Server 他两的POM文件配置是一样的 <dependencies&g ...
- hadoop高可用集群搭建小结
hadoop高可用集群搭建小结1.Zookeeper集群搭建2.格式化Zookeeper集群 (注:在Zookeeper集群建立hadoop-ha,amenode的元数据)3.开启Journalmno ...
- Spark高可用集群搭建
Spark高可用集群搭建 node1 node2 node3 1.node1修改spark-env.sh,注释掉hadoop(就不用开启Hadoop集群了),添加如下语句 export ...
- Hadoop HA高可用集群搭建(Hadoop+Zookeeper+HBase)
声明:作者原创,转载注明出处. 作者:帅气陈吃苹果 一.服务器环境 主机名 IP 用户名 密码 安装目录 master188 192.168.29.188 hadoop hadoop /home/ha ...
- Hadoop 3.1.2(HA)+Zookeeper3.4.13+Hbase1.4.9(HA)+Hive2.3.4+Spark2.4.0(HA)高可用集群搭建
目录 目录 1.前言 1.1.什么是 Hadoop? 1.1.1.什么是 YARN? 1.2.什么是 Zookeeper? 1.3.什么是 Hbase? 1.4.什么是 Hive 1.5.什么是 Sp ...
- MongoDB高可用集群搭建(主从、分片、路由、安全验证)
目录 一.环境准备 1.部署图 2.模块介绍 3.服务器准备 二.环境变量 1.准备三台集群 2.安装解压 3.配置环境变量 三.集群搭建 1.新建配置目录 2.修改配置文件 3.分发其他节点 4.批 ...
随机推荐
- 学习PHP框架只停留在会用层面,职业生涯肯定走不远!
工作这么多年,也面试过很多PHP工程师,我发现很多PHP工程师只停留在使用框架的层面,然而对框架底层根本没有深入去了解,那么这就会给自己的职业生涯带来一定的瓶颈,当遇到问题的时候你就无从下手,不知道如 ...
- 《HelloGitHub》第 44 期
兴趣是最好的老师,HelloGitHub 就是帮你找到兴趣! 简介 分享 GitHub 上有趣.入门级的开源项目. 这是一个面向编程新手.热爱编程.对开源社区感兴趣 人群的月刊,月刊的内容包括:各种编 ...
- vue当文字很多的时候实现...代替
vue当文字很多的时候实现...代替只需加三行代码 overflow: hiddenwhite-space: nowraptext-overflow: ellipsis
- MySQL 格式化时间 成字符串
创建个表: CREATE TABLE `x02基本信息` ( `ID` varchar(32) NOT NULL COMMENT '系统内记录的唯一标识,供系统内部使用.', `名称` varchar ...
- 渗透测试初学者的靶场实战 1--墨者学院SQL注入—布尔盲注
前言 大家好,我是一个渗透测试的爱好者和初学者,从事网络安全相关工作,由于爱好网上和朋友处找了好多关于渗透的视频.工具等资料,然后自己找了一个靶场,想把自己练习的体会和过程分享出来,希望能对其他渗透爱 ...
- Kafka topic Schema version mismatch error - org.apache.kafka.common.protocol.types.SchemaException
Problem description: There is error messge when run spark app using spark streaming Kafka version 0. ...
- 从入门到入土:Lambda完整学习指南,包教包会!
什么是Lambda表达式 Lambda表达式是Java SE 8中一个重要的新特性.lambda表达式允许你通过表达式来代替功能接口.lambda表达式就和方法一样,它提供了一个正常的参数列表和一个使 ...
- 漫谈LiteOS之开发板-GPIO(基于GD32450i-EVAL)
[摘要] 本文主要从GPIO的定义.工作模式.特色.工作场合.以及GD32450i-EVAL开发板的引脚.对应的寄存器以及GPIO的流水灯示例对GPIO加以介绍,希望对你有所帮助. 1定义 GPIO( ...
- Python文本转化语音模块大比拼,看看青铜与王者的差别!
文本转语音 如果把Python比喻成游戏中的一个英雄,你觉得它是谁?对于Dota老玩家来说,我会想到钢琴手卡尔!感觉Python和卡尔一样,除了生孩子什么都可以做的角色.日常生活中,我们会涉及到很多语 ...
- FF.PyAdmin 接口服务/后台管理微框架 (Flask+LayUI)
源码(有兴趣的朋友请Star一下) github: https://github.com/fufuok/FF.PyAdmin gitee: https://gitee.com/fufuok/FF.Py ...